3月9日下午3点30分,备受各界关注的人机世纪大战首战结果公布,执黑先行的李世石,在中盘局势领先的情况下,被 AlphaGo敏锐捕捉到其右下角局部的失误,随即AlphaGo获得主动权,最终1-0,AlphaGO取得本局的胜利。
面对9段高手李世石,AlphaGo不仅与其“分庭抗礼”,且最终获得首胜。我们不禁要问,作为一款计算机程序,AlphaGo的计算能力到底有多强呢?
这不禁让人想起曾经声名显赫、轰动世界的IBM“深蓝”。深蓝是美国IBM公司生产的一台超级国际象棋电脑,重1270公斤,有32个大脑(微处理器),每秒钟可以计算2亿步,计算能力11.38 GFLOPS,输入了一百多年来优秀棋手的对局两百多万局。
IBM的深蓝曾在1997年战胜国际象棋世界冠军卡斯帕罗夫。而据搜狗CEO王小川表示,现在,一台笔记本的计算能力已是当年IBM计算机深蓝的3万倍。
AlphaGo的“大脑”如何战胜人脑?
传统的人工智能方法是将所有可能的走法构建成一棵搜索树 ,但这种方法对围棋并不适用。而据了解,此次谷歌的AlphaGo使用的是蒙特卡洛树搜索算法,将高级搜索树与深度神经网络结合在一起,而其中的深度神经网络,则是由 “价值网络”(value network)与“决策网络”(policy network) 这两种不同的深度神经网络一起构成。值网络评估大量选点计算局面,策略网络则负责选择落点。这些神经网络通过12个处理层传递对棋盘的描述,处理层则包含数百万个类似于神经的连接点。
说通俗一点,就是围棋过程中,AlphaGo 的“大脑 ”可以模拟人脑先“筛选”出那些有利的棋局,并“抛弃”掉明显的差棋,从而将计算量控制在AlphaGo “大脑”可以完成的范围内。具体来看:
1. “价值网络”负责减少搜索的深度:AI 会一边推算一边判断局面,局面明显劣势的时候,就直接抛弃某些路线,不用一条道算到黑。
2. “策略网络 ”负责减少搜索的宽度:面对眼前的一盘棋,有些棋步是明显不该走的,比如不该随便送子给别人吃。
3.利用蒙特卡洛拟合,将这些信息放入一个概率函数,AI 就不用给每一步以同样的重视程度,而可以重点分析那些能赢的棋步。
 SdRednc
SdRednc
众所周知,机器最初通过模仿人类玩家,尝试匹配职业棋手的棋局,一旦它达到了一定的熟练程度,它开始和自己对弈大量棋局,使用强化学习进一步改善它。而谷歌AlphaGo的训练方式有过之而无不及。
谷歌方面用人类围棋高手的三千万步围棋走法训练神经网络,与此同时,AlphaGo也自行研究新战略,在它的神经网络之间运行了数千局围棋,利用反复试验调整连接点,这个流程也称为巩固学习(reinforcement learning),通过广泛使用Google云平台,完成了大量研究工作。
【分页导航】
《电子技术设计》网站版权所有,谢绝转载
{pagination}
AlphaGo运算学习的两大核心技术分析
出门问问的NLP工程师李理则从技术角度分析了AlphaGo的核心算法技术:
MCTS(Monte Carlo Tree Search)
MCTS之于围棋就像Alpha-Beta搜索之于象棋,是核心的算法,而比赛时的搜索速度至关重要。就像深蓝当年战胜时,超级计算机的运算速度是制胜的关键因素之一。
 SdRednc
SdRednc
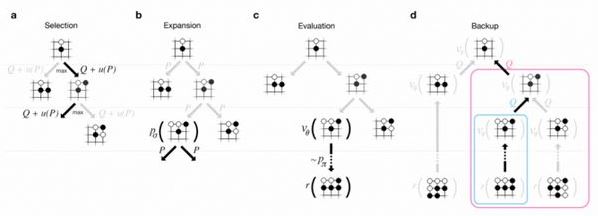
MCTS的4个步骤:Selection,Expansion,Evaluation(rollout)和Backup
MCTS的并行搜索:
(1) Leaf Parallelisation
最简单的是Leaf Parallelisation,一个叶子用多个线程进行多次Simulation,完全不改变之前的算法,把原来的一次Simulation的统计量用多次来代替,这样理论上应该准确不少。但这种并行的问题是需要等待最慢的那个结束才能更新统计量;而且搜索的路径数没有增多。
(2) Root Parallelisation
多个线程各自搜索各自的UCT树,最后投票
(3) Tree Parallelisation
这是真正的并行搜索,用多个线程同时搜索UCT树。当然统计量的更新需要考虑多线程的问题,比如要加锁。
另外一个问题就是多个线程很可能同时走一样的路径(因为大家都选择目前看起来Promising的孩子),一种方法就是临时的修改virtual loss,比如线程1在搜索孩子a,那么就给它的Q(v)减一个很大的数,这样其它线程就不太可能选择它了。当然线程1搜索完了之后要记得改回来。
《A Lock-free Multithreaded Monte-Carlo Tree Search Algorithm》使用了一种lock-free的算法,这种方法比加锁的方法要快很多,AlphaGo也用了这个方法。
Segal研究了为什么多机的MCTS算法很难,并且实验得出结论使用virtual loss的多线程版本能比较完美的scale到64个线程(当然这是单机一个进程的多线程程序)。AlphaGo的Rollout是用CPU集群来加速的,但是其它的三个步骤是在一台机器完成的,这个就是最大的瓶颈。
DCNN(Deep Convolutional Neural Network)
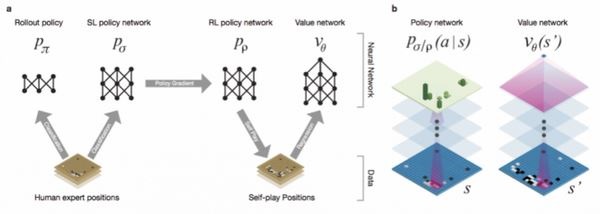
(使用深度神经网络训练的Policy Network和Value Network)
SdRednc
神经网络训练的时间一般很长,即使用GPU,一般也是用天来计算。Google使用GPU Cluster来训练,从论文中看,训练时间最长的Value Network也只是用50个GPU训练了一周。
给定一个输入,用卷积神经网络来预测,基本运算是矩阵向量运算和卷积,由于神经网络大量的参数,用CPU来运算也是比较慢的。所以一般也是用GPU来加速,而AlphaGo是用GPU的cluster来加速的。
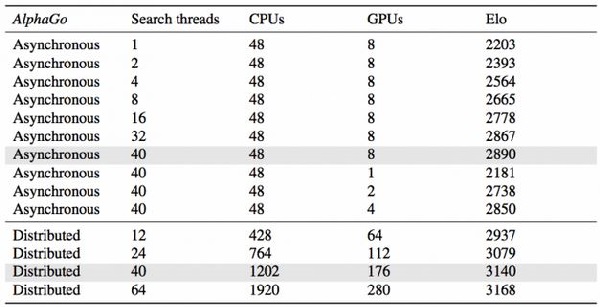
论文送审时(2015年11月)AlphaGo的水平
论文里使用Elo Rating系统的水平:
(使用深度神经网络训练的Policy Network和Value Network)
SdRednc
a图是用分布式的AlphaGo,单机版的AlphaGo,CrazyStone等主流围棋软件进行比赛,然后使用的是Elo Rating的打分。
b图说明了Policy Network Value Network和Rollout的作用,做了一些实验,去掉一些的情况下棋力的变化,结论当然是三个都很重要。
c图说明了搜索线程数以及分布式搜索对棋力的提升。
【分页导航】
《电子技术设计》网站版权所有,谢绝转载
{pagination}
李世石还有雪耻的机会吗?
谷歌DeepMind CEO Hassabis表示,用强化学习技术“教”机器下围棋,就如同教小孩子一样,不是让程序员添一段代码就完事,而是要给程序看足够多的案例,让机器自己“领悟”到正确的下法。
从一定程度上说,AlphaGo是在以预测的方式模拟人类的直觉,试图以人类的思维去学习围棋。目前,AlphaGo模仿人类的直觉判断程度约为80%,但李世石表示由于它的运算速度要优于自己,所以要格外小心。
这种强化学习技术的应用,其实早已不局限于围棋。DeepMind曾用相同的技术教会计算机玩雅达利(美国电脑游戏机厂商)的经典游戏。另有消息称,DeepMind最近宣布与英国国民健康服务中心(NHS)合作,首个项目是为医生护士开发一款可以监测到病人是否出现急性shen衰竭的App。
需要说明的是,人脑不可能像电脑一样无时不刻地接受“深度学习”,所以理论上来说只要 AlphaGo 经历了足够的训练,就能击败所有的人类围棋选手。
原来机器已经如此可怕,接下来的比赛,李世石还有雪耻的机会吗?
(文章来源:雷锋网李理宗仁、新浪科技、天极网)
【分页导航】
《电子技术设计》网站版权所有,谢绝转载
 SdRednc
SdRednc

 最前沿的电子设计资讯
最前沿的电子设计资讯
