门票通过网上购买,存储在智能手机中。你需要将手机放到指定区域上,建立NFC连接,门票随之得到确认,大门开启允许你进入。所有这一切都是在匿名情况下发生的。这些协议基于知识的零知识证明,主要由通信和算法组成——这正是我们研究的对象。
想像一下你正在排队等待参加一个重要活动。门票是通过网上购买的,存储在你的智能手机中。你需要将手机放到某个指定区域上,建立起NFC连接,门票随之得到确认,大门开启允许你进入。好消息是,所有这一切都是在匿名情况下发生的。
在这类应用中,你的匿名信息可以通过使用最近开发的匿名信任协议(如IBM的Idemix或微软的U-Prove)得到保护。这些协议基于知识的零知识证明(ZKPK)。你可以证明你拥有某个属性的知识而不用透露具体数值。这种属性与所谓的承诺中的公钥是捆绑在一起的。
图1给出了这种ZKPK——本例中的Schnorr协议的简要示意图。其中y是x的承诺。在强大的RSA假设下,是很难从y找出x的,即使你知道g和m。
仔细观察协议我们会发现x仍然是隐藏的。验证方只知道y是正确的承诺。我们还能发现,协议主要由通信和算法组成——这正是我们研究的对象。
《电子技术设计》网站版权所有,谢绝转载 {pagination} 嵌入式安全性测试平台 我们很快发现,当这些ZKPK在嵌入式系统上实现时,通信和算法都会引起瓶颈(见例子)。我们不希望用户保持NFC连接超过比方说5秒钟,不然会与通过“接触”交换数据的NFC概念发生冲突。 为了详细研究这个问题,我们构建了一个测试平台(见图3),以便我们能够方便地改变协议的不同方面。例如,如果我们将算法卸载到硬件加速器来提升算法速度会怎么样?或者操作数的长度对通信和算法的速度有何影响? 我们开发的平台如图3所示,它基于的是赛灵思的ML605评估板。我们增加了恩智浦的PN532开发套件用于NFC通信。运行嵌入式Linux的MicroBlaze用于控制整个系统。使用Linux(本例中用的是PetaLinux发行版)有很大的优势,即在嵌入式系统中可以用标准库,比如用于算法的GMP和用于NFC通信的libnfc。
《电子技术设计》网站版权所有,谢绝转载 {pagination} 开源硬件 因此我们想要一个可以用作硬件加速器的加密内核。可能的话,它可以计算:
《电子技术设计》网站版权所有,谢绝转载 {pagination} 一些背景 并行求幂 最直接也是高效的模幂运算方法是通过重复平方和乘法运算获得最终结果。这种方法很容易扩展到并行求幂运算。下面就是这种算法的描述,其中Mont()表示蒙哥马利乘法。这是一种用硬件执行模乘运算的有效方法,我们对此还将进一步讨论。我们假设R2 (= 22n ,n是m的长度)可以通过控制软件提供甚至计算。
《电子技术设计》网站版权所有,谢绝转载 {pagination} 性能 乘法器资源使用率取决于操作数(n)的长度和流水线的级数(k)。 对FPGA来说可以表示为:
《电子技术设计》网站版权所有,谢绝转载 {pagination} 首次测试 基于NFC的ZKPK 作为第一次实际测试,我们实现了基于NFC的简化Schnorr ZKPK,详见我们的嵌入式测试平台介绍。这种个嵌入式平台是验证方,而PC(连接有PN532电路板)用作证明方。 下表给出了不同操作数长度下的时序结果。很明显,当使用我们的硬件IP内核时,操作数长度对总的协议时间基本上没有影响。增加操作数长度会稍稍增加通信时间(这是预料中的)。然而,验证所需的时间将大大增加。 我们需要指出的是,通信占总时间的很大一部分。像产生随机数等一般数据操作也需要一定的时间。然而,我们的IP内核还无法克服这些挑战。
《电子技术设计》网站版权所有,谢绝转载 {pagination} 小结和未来发展 我们已经表明,这种用于模并行求幂运算的IP内核的可定制VHDL设计是非常适合匿名信任加密系统的嵌入式实现的。我们已经见证了如何调整内核参数来满足用户的需要。 除了更为理论性的性能分析外,我们还在实际的嵌入式装置中使用了这个设计。作为我们未来工作的一部分,我们将继续为匿名信任证书开发完整的嵌入式应用程序。 进一步开发对象还将导向内核本身。目前内核只提供PLB接口。提供对AXI和Wishbone接口的支持“已经列在任务清单上”。 包括所有乘法与求幂技术文档和测试基准的完整VHDL设计已经在开源网站OpenCores上公开上线。只要有GNU较宽松通用公共许可(LGPL)协议就能免费下载VHDL源代码。 项目的网页地址:http://opencores.org/project,mod_sim_exp 原文作者:Geoffrey Ottoy、Bart Preneel、Jean-Pierre Goemaere、Nobby Stevens和Lieven De Strycker
《电子技术设计》网站版权所有,谢绝转载
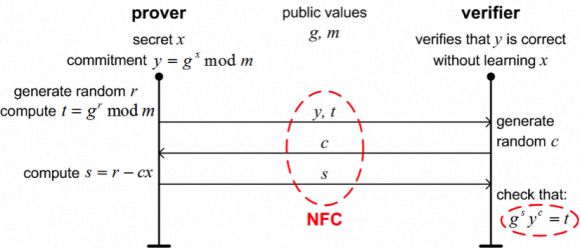
图1: Schnorr ZKPK协议的简化版本。
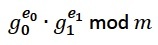
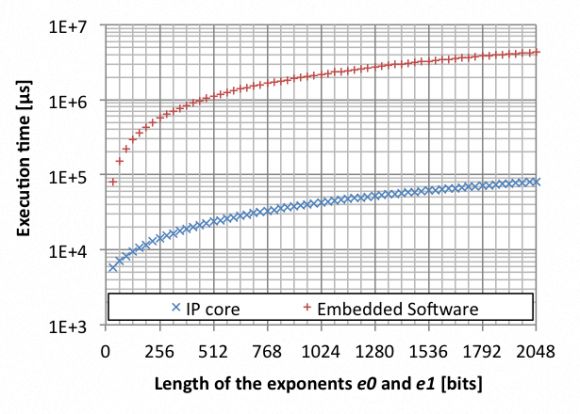
图2:在嵌入式平台上分别用硬件卸载和不用硬件卸载时的并行求幂执行时间。
【分页导航】
| • 第1页:匿名信息通过匿名信任协议保护 | • 第2页:嵌入式安全性测试平台 |
| • 第3页:开源硬件 | • 第4页:一些背景 |
| • 第5页:性能 | • 第6页:首次测试 |
| • 第7页:小结和未来发展 | |
《电子技术设计》网站版权所有,谢绝转载 {pagination} 嵌入式安全性测试平台 我们很快发现,当这些ZKPK在嵌入式系统上实现时,通信和算法都会引起瓶颈(见例子)。我们不希望用户保持NFC连接超过比方说5秒钟,不然会与通过“接触”交换数据的NFC概念发生冲突。 为了详细研究这个问题,我们构建了一个测试平台(见图3),以便我们能够方便地改变协议的不同方面。例如,如果我们将算法卸载到硬件加速器来提升算法速度会怎么样?或者操作数的长度对通信和算法的速度有何影响? 我们开发的平台如图3所示,它基于的是赛灵思的ML605评估板。我们增加了恩智浦的PN532开发套件用于NFC通信。运行嵌入式Linux的MicroBlaze用于控制整个系统。使用Linux(本例中用的是PetaLinux发行版)有很大的优势,即在嵌入式系统中可以用标准库,比如用于算法的GMP和用于NFC通信的libnfc。
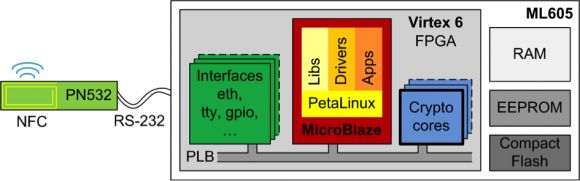
图3:用于测试和评估匿名信任协议的嵌入式平台。
【分页导航】
| • 第1页:匿名信息通过匿名信任协议保护 | • 第2页:嵌入式安全性测试平台 |
| • 第3页:开源硬件 | • 第4页:一些背景 |
| • 第5页:性能 | • 第6页:首次测试 |
| • 第7页:小结和未来发展 | |
《电子技术设计》网站版权所有,谢绝转载 {pagination} 开源硬件 因此我们想要一个可以用作硬件加速器的加密内核。可能的话,它可以计算:

● 针对嵌入式平台的开源IP内核(控制要求的软件)
● VHDL代码独立于器件和制造商,并得到良好归档
● 基数g0、g1和模数m的长度可以在综合前自由选取
● 为指数准备了一个FIFO,因此e0和e1的长度可以完全取决于控制软件
● 将流水线式蒙哥马利乘法器作为IP内核的核心,并具有自由选择的级长,从而允许调整内核获得想要的速度/面积
● 操作数RAM专门针对并行求幂进行了优化
【分页导航】
| • 第1页:匿名信息通过匿名信任协议保护 | • 第2页:嵌入式安全性测试平台 |
| • 第3页:开源硬件 | • 第4页:一些背景 |
| • 第5页:性能 | • 第6页:首次测试 |
| • 第7页:小结和未来发展 | |
《电子技术设计》网站版权所有,谢绝转载 {pagination} 一些背景 并行求幂 最直接也是高效的模幂运算方法是通过重复平方和乘法运算获得最终结果。这种方法很容易扩展到并行求幂运算。下面就是这种算法的描述,其中Mont()表示蒙哥马利乘法。这是一种用硬件执行模乘运算的有效方法,我们对此还将进一步讨论。我们假设R2 (= 22n ,n是m的长度)可以通过控制软件提供甚至计算。

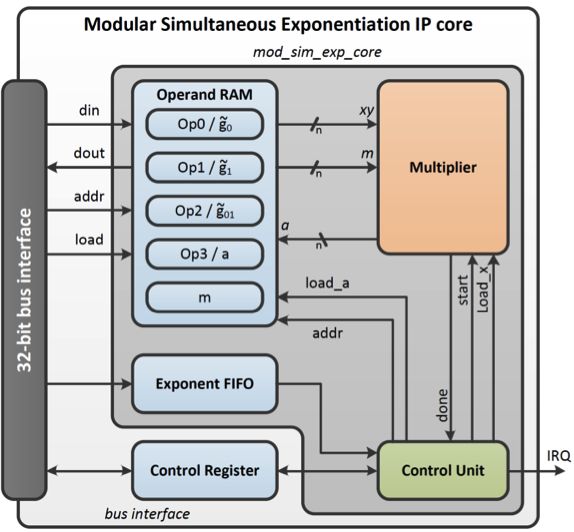
图4:我们开发的并行求幂IP内核的框图。
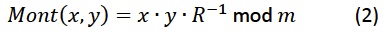
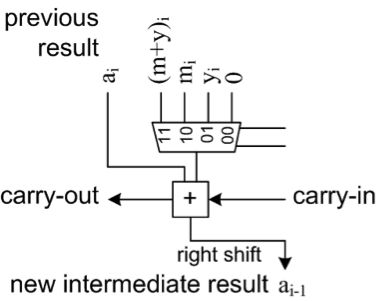
图5:一个脉动阵列单元计算中间结果a的一个位。
图6:脉动流水线操作。
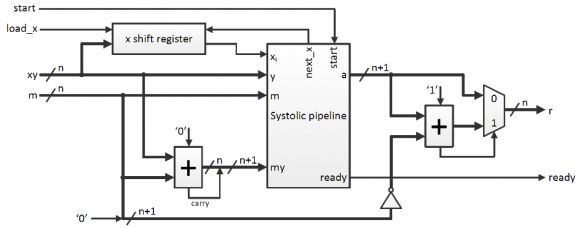
图7:蒙哥马利乘法器结构。
【分页导航】
| • 第1页:匿名信息通过匿名信任协议保护 | • 第2页:嵌入式安全性测试平台 |
| • 第3页:开源硬件 | • 第4页:一些背景 |
| • 第5页:性能 | • 第6页:首次测试 |
| • 第7页:小结和未来发展 | |
《电子技术设计》网站版权所有,谢绝转载 {pagination} 性能 乘法器资源使用率取决于操作数(n)的长度和流水线的级数(k)。 对FPGA来说可以表示为:
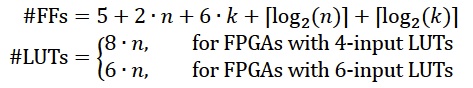
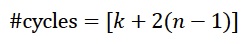
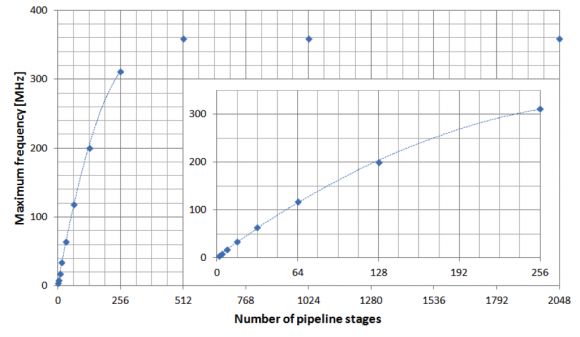
图8:流水线级长度对最高时钟频率的影响。
1.我们预先知道我们的工作频率。然后就足以选择级数以便让时钟频率至少能那么高。选择更多的级数只会导致耗用更多的资源(触发器)。
2.尽量缩短运算时间。这将由级数和最大时钟频率来确定。如果我们认为设计将在这个频率运行(理论上),我们可以获得下图所示的运算时间(n=1536)。我们可以看到,对我们的器件(Virtex 6)来说,当级长为4位时可以获得最短运算时间。
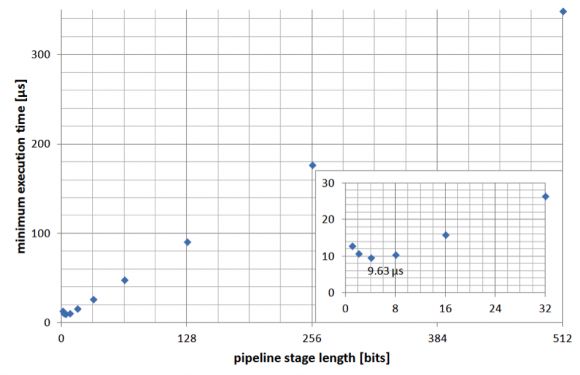
图9:流水线级长对最短执行时间的影响。
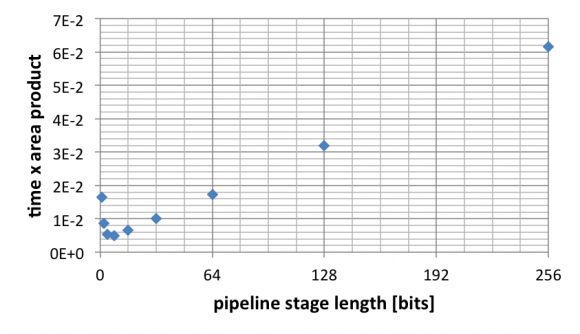
图10:流水线级长对时间与面积乘积的影响。
【分页导航】
| • 第1页:匿名信息通过匿名信任协议保护 | • 第2页:嵌入式安全性测试平台 |
| • 第3页:开源硬件 | • 第4页:一些背景 |
| • 第5页:性能 | • 第6页:首次测试 |
| • 第7页:小结和未来发展 | |
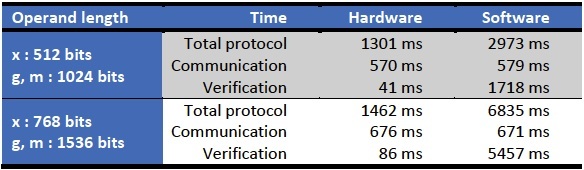
《电子技术设计》网站版权所有,谢绝转载 {pagination} 首次测试 基于NFC的ZKPK 作为第一次实际测试,我们实现了基于NFC的简化Schnorr ZKPK,详见我们的嵌入式测试平台介绍。这种个嵌入式平台是验证方,而PC(连接有PN532电路板)用作证明方。 下表给出了不同操作数长度下的时序结果。很明显,当使用我们的硬件IP内核时,操作数长度对总的协议时间基本上没有影响。增加操作数长度会稍稍增加通信时间(这是预料中的)。然而,验证所需的时间将大大增加。 我们需要指出的是,通信占总时间的很大一部分。像产生随机数等一般数据操作也需要一定的时间。然而,我们的IP内核还无法克服这些挑战。
【分页导航】
| • 第1页:匿名信息通过匿名信任协议保护 | • 第2页:嵌入式安全性测试平台 |
| • 第3页:开源硬件 | • 第4页:一些背景 |
| • 第5页:性能 | • 第6页:首次测试 |
| • 第7页:小结和未来发展 | |
《电子技术设计》网站版权所有,谢绝转载 {pagination} 小结和未来发展 我们已经表明,这种用于模并行求幂运算的IP内核的可定制VHDL设计是非常适合匿名信任加密系统的嵌入式实现的。我们已经见证了如何调整内核参数来满足用户的需要。 除了更为理论性的性能分析外,我们还在实际的嵌入式装置中使用了这个设计。作为我们未来工作的一部分,我们将继续为匿名信任证书开发完整的嵌入式应用程序。 进一步开发对象还将导向内核本身。目前内核只提供PLB接口。提供对AXI和Wishbone接口的支持“已经列在任务清单上”。 包括所有乘法与求幂技术文档和测试基准的完整VHDL设计已经在开源网站OpenCores上公开上线。只要有GNU较宽松通用公共许可(LGPL)协议就能免费下载VHDL源代码。 项目的网页地址:http://opencores.org/project,mod_sim_exp 原文作者:Geoffrey Ottoy、Bart Preneel、Jean-Pierre Goemaere、Nobby Stevens和Lieven De Strycker
【分页导航】
| • 第1页:匿名信息通过匿名信任协议保护 | • 第2页:嵌入式安全性测试平台 |
| • 第3页:开源硬件 | • 第4页:一些背景 |
| • 第5页:性能 | • 第6页:首次测试 |
| • 第7页:小结和未来发展 | |
《电子技术设计》网站版权所有,谢绝转载
上一篇:
意法半导体:提供高性价比的MCU产品
-
微信扫一扫
一键转发 -
 最前沿的电子设计资讯
最前沿的电子设计资讯
请关注“电子技术设计微信公众号”
- Achronix推出基于FPGA的加速自动语音识别解决方案 提供超低延迟和极低错误率(WER)的实时流式语音转文本解决方案,可同时运行超过1000个并发语音流
- Microchip FPGA采用量身定制的PolarFire FPGA和SoC解 涵盖工业和通信领域以及智能嵌入式视觉、电机控制和光学接入技术等十个系列的协议栈,内容包括 IP、参考设计、开发套件、应用说明、演示指南等
- AMD 以面向工业与商业应用的 Kria K24 SOM 及入 K24 SOM 和 KD240 套件支持为电机控制和数字信号处理应用设计高能效量产就绪型解决方案,并加速上市进程···
- AMD Kria新品只有信用卡一半大,无需FPGA经验一小时内 日前,AMD宣布推出AMD Kria™ K24系统模块(SOM)和KD240驱动器入门套件,这是Kria自适应SOM及开发者套件产品组合的最新产品。AMD Kria K24 SOM能以小尺寸提供高能效计算,面向成本敏感型工业和商业边缘应用···
- 通过AI加速,智能终端应用得到创新提升 京微齐力采用Imagination AI加速器,助力打造Avatar高端产品系列第一颗新型智能加速芯片,为不同行业用户提供高性价比、强适配性的系统级平台解决方案
- 2023年嵌入式调查:随着工作负载的激增,更多IP将会被重复 最新的2023年嵌入式调查已经出炉,它不仅显示了迅速增长的工作负载以及工程师如何应对处理,还展示了最常用的设计工具、操作系统和处理器。
- Microchip发布业界能效最高的中端FPGA工业边缘协议栈 这些新工具使得转向使用PolarFire FPGA和片上系统(SoC)FPGA变得比以往更容易
- 采用CEM插卡模式的VectorPath®加速卡在业内率先通过P Achronix半导体公司今日宣布:其搭载了Speedster®7t FPGA器件的VectorPath加速卡已通过PCI-SIG的PCIe Gen5认证,并且是PCI-SIG 集成商列表中的第一款也是唯一一款通过 PCIe Gen5 x16 认证的FPGA(CEM)加速卡,传输速率达到了32GT/s。
- 无人机视觉跟踪系统解决方案-米尔基于XILINX XCZU3EG 近些年来,计算机视觉技术和无人机技术蓬勃发展,摄像头的像素和工艺也越来越完善,基于这一基础,无人机视觉跟踪技术成为炙手可热的研究领域。
- AMD推出首款5nm基于ASIC的媒体加速器卡,开启大规模交互 专用视频处理架构支持AV1加速处理,每卡可提供32路1080p转码密度,并支持AI优化视频质量
- 直击2023 IIC上海现场,半导体国产化的全速“狂飙” 在3月29日和3月30日,由电子工程领域全球领先的技术媒体机构AspenCore主办的2023国际集成电路展览会暨研讨会(IIC)上海展会活动现场,汇聚了众多国内外优质展商,EDN小编在现场参观走访时,也发现不少的国产厂商都提到了“国产化”,就让我们一起来看看这些国产厂商在这条路上做了哪些努力,又是怎样推动了国产化的全速“狂飙”。
- 米尔基于Zynq 7000系列单板的FPGA农业生产识别系统 随着农业生产模式和视觉技术的发展,农业采摘机器人的应用已逐渐成为了智慧农业的新趋势,通过机器视觉技术对农作物进行自动检测和识别已成为采摘机器人设计的关键技术之一,这决定了机器人的采摘效果和农场的经济效率。
- 2024年1月第3周新能源周销量 本周我们还是关注我们芝能热点品牌的情况,我们罗列了品牌和重点车型的情况···
- 与健康息息相关的分子马达(二) 细胞是一个包含多种分子马达的复杂系统,分子马达功能各异,协作完成细胞活动。但分子马达的功能异常或表达异常
- 拆解报告:酷态科10000mAh 30W快充移动电源 酷态科这款移动电源内置两节21700电池,总容量为10000mAH,体积小巧便携。移动电源两侧分别设有USB-C和USB-A接
- 华为FreeClip开放式耳机全球首拆 HUAWEI华为FreeClip开放式耳机在外观方面,采用极简主义几何设计,兼具了全天候舒适佩戴和时尚佩饰属性。在功能
- 神通552125软包电芯评测 这款神通552125软包电芯,我爱音频网分别在0.2C、0.5C以及1C三种倍率下进行测试,充电方面,1C倍率充电能在1小时2
- 华为FreeClip开放式耳机首发评测 作为华为旗下首款开放式耳机,FreeClip 采用了少见的「夹耳式」结构,整体呈 C 型,通过夹耳廓的形式固定在耳朵上
- 生物生命活动驱动者,与人类健康息息相关的分子马达(一) 分子马达由生物大分子构成,能够将化学能转化为机械能。分子马达作为具有特定结构的蛋白质,能够通过自身的运动
- 人形机器人之关键触觉传感器:刚性到柔性 触觉传感器是机器人进化的核心需要解决的问题,芝能科技将带你逐步了解触觉传感器的技术原理、技术路线、发展
- 拆解报告:美富达65W 2C1A氮化镓快充充电器 美富达这款65W充电器具备2C1A输出接口,并配有美标折叠插脚。充电器机身上没有标注任何产品信息。实测充电器
- 详细解读ACLR和ACPR 今天射频学堂将和大家一起抽丝剥茧一个射频指标——ACLR。
- 消失的她,GERBER失踪之谜 Gerber格式是线路板行业软件描述线路板(线路层、阻焊层、字符层等)图像及钻、铣数据的文档格式集合。明明有图
- OpenAI进军芯片行业 OpenAI,这个人工智能行业的当红小生,正积极探索半导体市场的机会。OpenAI首席执行官Sam Altman已开始与中东知
- Wi-Fi Alliance选用RUCKUS Wi-Fi 7平台作为Wi-Fi CERTIFIED 7互 RUCKUS Wi-Fi 7接入点为Wi-Fi CERTIFIED 7设备制定标准并支持全球互操作性
- 安霸发布前端AI开发者平台:Cooper Cooper开发者平台为工业应用、AIoT、智能视频分析和前端AI计算应用提供高能效解决方案。
- Microchip推出10款多通道远程温度传感器 MCP998x系列是单一供应商提供的最大车规级远程温度传感器产品组合之一
- 罗克韦尔自动化发布《可持续发展2023年度报告》 阐述在可持续发展方面的进展和成果
- Melexis首创Triphibian技术可实现MEMS压力敏感元件革新 Melexis今日宣布,推出首款采用全新专利Triphibian™技术的压力传感器芯片MLX90830。
- 上海首家第三方整车OTA测试实验室携手MVG 填补智能网联汽车测 MVG近日宣布,中国信通院上海工创中心(以下简称“上海工创中心”) 与浙江埃科汽车技术服务有限公司(以下简称“
- Transphorm发布两款4引脚TO-247封装器件,针对高功率服务器、可再 新推出的氮化镓场效应晶体管可作为原始设计选项或碳化硅(SiC)替代器件
- 全国产六核CPU商显板,米尔-芯驰D9360高性能高安全显控方案 今天给大家介绍一款国产厂商(芯驰科技)推出的六核高性能、高安全性芯片:D9-Pro,这款芯片有超强视频编解码能力,米
- 意法半导体与Sphere Studios联合打造全球最大的电影摄影机图像传 该影像传感器专为世界上最先进的摄影系统 Big Sky而定制,能够为拉斯维加斯的 Sphere球幕拍摄超高分辨率影像
- 美光率先上市基于LPDDR5X的 LPCAMM2内存模块,变革PC用户体验 LPCAMM2 内存模块以更高性能、更低功耗、更小的外形规格助力笔记本电脑实现更快速度、更小巧尺寸和更强续航
- 瑞萨推出其首款集成闪存的双核低功耗蓝牙SoC并实现最低功耗 全新DA14592 SoC和DA14592MOD模块支持众包定位等广泛应用,同时带来最低eBoM
- Vishay为其高性能红外接收器模块推出升级版 器件可提供即插即用方式替换现有解决方案,降低更宽电源电压范围内的供电电流,提高抗ESD可靠性、黑暗环境灵敏

