想像一下你正在排队等待参加一个重要活动。门票是通过网上购买的,存储在你的智能手机中。你需要将手机放到某个指定区域上,建立起NFC连接,门票随之得到确认,大门开启允许你进入。好消息是,所有这一切都是在匿名情况下发生的。
在这类应用中,你的匿名信息可以通过使用最近开发的匿名信任协议(如IBM的Idemix或微软的U-Prove)得到保护。这些协议基于知识的零知识证明(ZKPK)。你可以证明你拥有某个属性的知识而不用透露具体数值。这种属性与所谓的承诺中的公钥是捆绑在一起的。
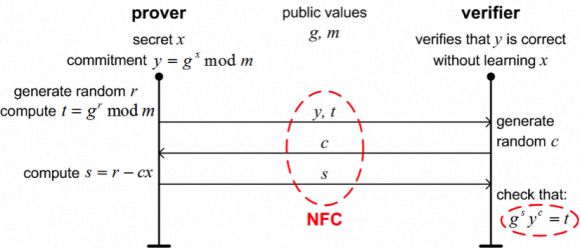
图1给出了这种ZKPK——本例中的Schnorr协议的简要示意图。其中y是x的承诺。在强大的RSA假设下,是很难从y找出x的,即使你知道g和m。
仔细观察协议我们会发现x仍然是隐藏的。验证方只知道y是正确的承诺。我们还能发现,协议主要由通信和算法组成——这正是我们研究的对象。
7Lyednc
图1: Schnorr ZKPK协议的简化版本。
-----------------------------------------------------------------
在嵌入式平台上计算并行求幂所需的时间例子
在我们的测试装置(后面会讨论到)上,我们比较了硬件加密内核和软件实现方法的执行时间。
硬件和软件都计算:
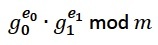 7Lyednc
7Lyednc
在匿名信任协议中经常使用的并行求幂。
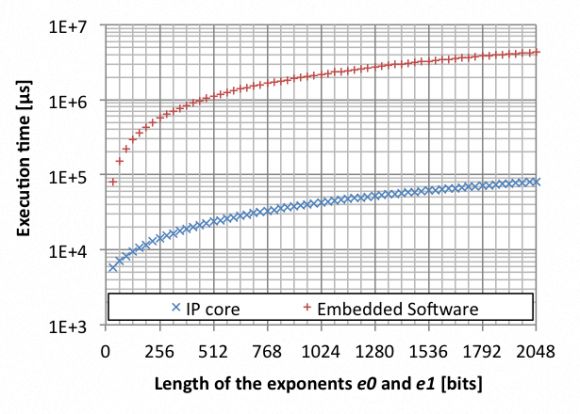
我们规定指数长度在32位和2048位之间变化。基数的长度是固定的,本例中是1024位。软件运行在嵌入式Linux操作系统上,并在多精度算法中使用了GMP库。
处理器和IP内核都以相同速度(100MHz)运行。我们发现,两种方法的执行时间都随指数长度成比例的增加。然而,采用硬件卸载方式的运算要快10至50倍。
7Lyednc
图2:在嵌入式平台上分别用硬件卸载和不用硬件卸载时的并行求幂执行时间。
-----------------------------------------------------------------
嵌入式安全性测试平台
我们很快发现,当这些ZKPK在嵌入式系统上实现时,通信和算法都会引起瓶颈(见例子)。我们不希望用户保持NFC连接超过比方说5秒钟,不然会与通过“接触”交换数据的NFC概念发生冲突。
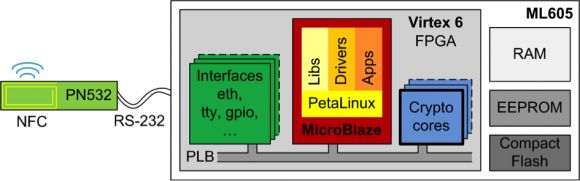
为了详细研究这个问题,我们构建了一个测试平台(见图3),以便我们能够方便地改变协议的不同方面。例如,如果我们将算法卸载到硬件加速器来提升算法速度会怎么样?或者操作数的长度对通信和算法的速度有何影响?
我们开发的平台如图3所示,它基于的是赛灵思的ML605评估板。我们增加了恩智浦的PN532开发套件用于NFC通信。运行嵌入式Linux的MicroBlaze用于控制整个系统。使用Linux(本例中用的是PetaLinux发行版)有很大的优势,即在嵌入式系统中可以用标准库,比如用于算法的GMP和用于NFC通信的libnfc。
7Lyednc
图3:用于测试和评估匿名信任协议的嵌入式平台。
使用FPGA可以很方便地增加和开发加密硬件加速器。本文余下部分将讨论我们开发用于测试目的的这种IP内核设计。
开源硬件
因此我们想要一个可以用作硬件加速器的加密内核。可能的话,它可以计算:
 7Lyednc
7Lyednc
市场上有多种IP内核可以用来执行单次模幂运算。然而,像DAA或Idemix等协议要求至少两次这种求幂的产品。这意味着我们仍然必须执行大操作数的多次(模)乘法,这将进一步增长总的执行时间。另外,我们希望能够改变所有操作数的长度,但不显著降低性能。也许我们还希望在其它平台上测试硬件。
这份希望清单促成了开源IP内核的设计,并符合以下规范:
● 针对嵌入式平台的开源IP内核(控制要求的软件)
● VHDL代码独立于器件和制造商,并得到良好归档
● 基数g0、g1和模数m的长度可以在综合前自由选取
● 为指数准备了一个FIFO,因此e0和e1的长度可以完全取决于控制软件
● 将流水线式蒙哥马利乘法器作为IP内核的核心,并具有自由选择的级长,从而允许调整内核获得想要的速度/面积
● 操作数RAM专门针对并行求幂进行了优化7Lyednc
然而,这不是一个(完美的)商用产品。我们知道可以实现更快或更小的设计。但每个人都可以自由使用并用这个设计做试验。这是我们设计的最初目的,也是我们做得尽可能可定制的原因。
目前这个内核还没有任何JTAG接口或自检功能。然而,可以对某些测试矢量执行求幂并比较结果来验证操作是否正确。
一些背景
并行求幂7Lyednc
最直接也是高效的模幂运算方法是通过重复平方和乘法运算获得最终结果。这种方法很容易扩展到并行求幂运算。下面就是这种算法的描述,其中Mont()表示蒙哥马利乘法。这是一种用硬件执行模乘运算的有效方法,我们对此还将进一步讨论。我们假设R2 (= 22n ,n是m的长度)可以通过控制软件提供甚至计算。
 7Lyednc
7Lyednc
仔细观察这个算法可以发现,采用要么运行单次乘法(用于预运算和最终乘法)要么自动运行主环的方式只实现一个乘法器并实现控制逻辑是合理的设计选择。
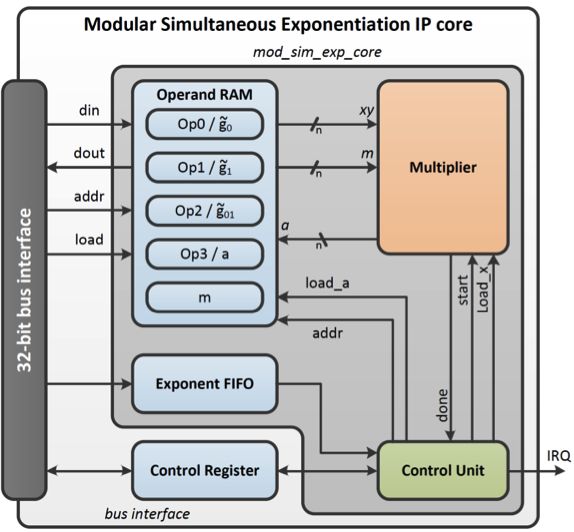
遵循标准的设计思路,我们将IP内核实现为存储器映射的外设。内核行为可以通过驱动软件使用控制寄存器改变(图4)。由于主环要求4个操作数,因此需要提供内存进行存储。中断线允许硬件就某些事件提醒处理器。
普通32位总线接口可以很容易扩展到多种流行的总线标准,如AXI或Wishbone。下面给出了最终设计的框图(n代表操作数的宽度)。
7Lyednc
图4:我们开发的并行求幂IP内核的框图。
模乘7Lyednc
现在我们的工作将简化为设计一个乘法器,并且它能根据我们的需要方便地进行定制。当操作数长度大于512位(对我们的应用来说这是显然的情况)时,一种被称为脉动阵列蒙哥马利的乘法器(2)是最有效的实现。此外,它很容易转换成硬件,从而简化生成通用描述的任务。
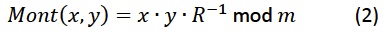 7Lyednc
7Lyednc
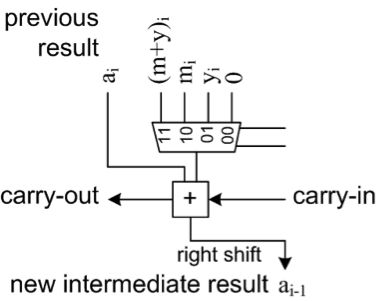
Mont(x,y)可以通过计算x的每一位的中间结果(a)进行运算。因此在经过n位后,乘法运算就完成了。a的每一位都可以用加法器和乘法器进行运算,最后一起形成脉动阵列单元(图5)。当大量单元级联时,为了中断进位链,我们将它们组成级。这样我们就可以控制设计的最大可达到频率,而这个频率主要受限于这个进位链。另外,还允许流水线运算。作为蒙哥马利算法一部分的右移操作可以确保a永远不会大于n+2位。
7Lyednc
图5:一个脉动阵列单元计算中间结果a的一个位。
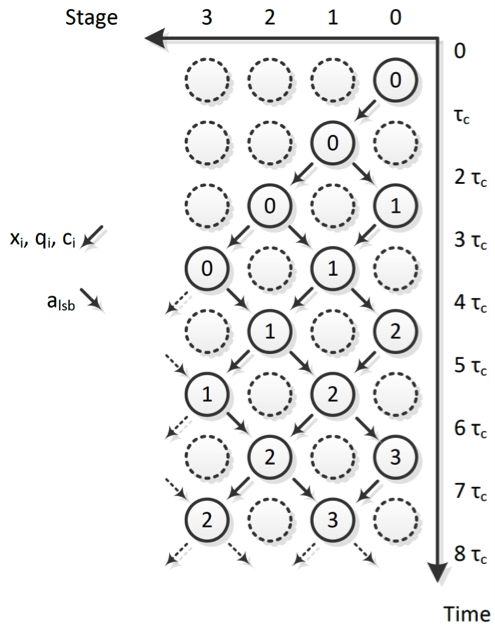
流水线操作见下图所示(图6)。每个圆代表一级。圆内的数字代表当时由那个级正在执行的步骤(x的哪一位)。非活动级用虚线表示。我们可以看到,一个级只能每2τc计算一步。这是右移操作的原因。τc表示一个级实际完成一个步骤所花的时间。在本例中,τc就是1个时钟周期。
7Lyednc
图6:脉动流水线操作。
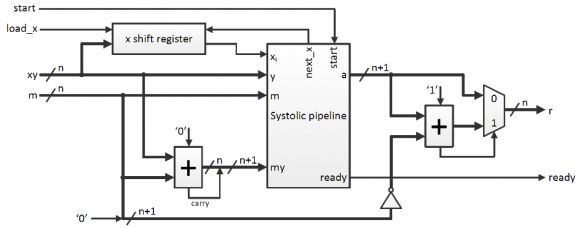
移位寄存器用于将x的位移进脉动流水线。两个额外加法器在必要时计算m+y(这是脉动阵列要求的)和a-m(确保结果小于m)。最终乘法器结构如下所示(图7)。
7Lyednc
图7:蒙哥马利乘法器结构。
性能
乘法器资源使用率取决于操作数(n)的长度和流水线的级数(k)。
对FPGA来说可以表示为:
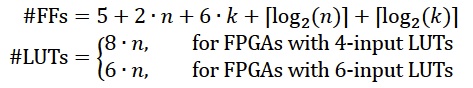 7Lyednc
7Lyednc
对于大的n来说,整个IP内核只使用另外一小部分FF和LUT比如用于控制逻辑和总线接口。然而,它也需要多个RAM单元来存储操作数。
执行乘法的时钟周期数也取决于n和k:
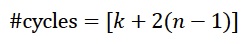 7Lyednc
7Lyednc
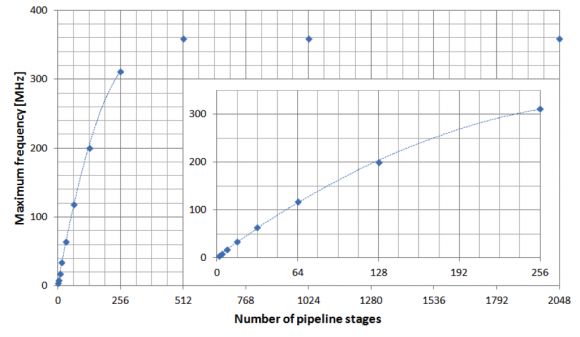
不过如前所述,级数——因此这些级的长度——对乘法器的最大可达时钟频率也有影响。这可以从图7看出来(n=2048)。
7Lyednc
图8:流水线级长度对最高时钟频率的影响。
在使用这个设计时,可以有几种方法:
1.我们预先知道我们的工作频率。然后就足以选择级数以便让时钟频率至少能那么高。选择更多的级数只会导致耗用更多的资源(触发器)。
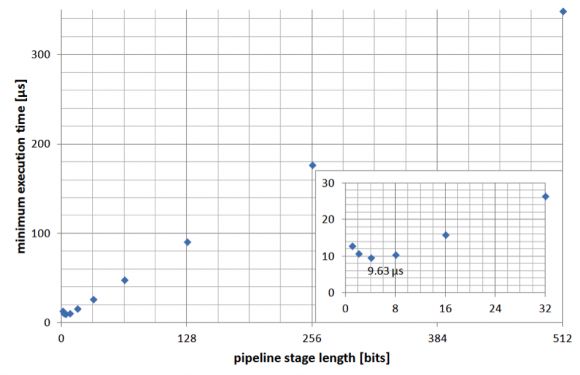
2.尽量缩短运算时间。这将由级数和最大时钟频率来确定。如果我们认为设计将在这个频率运行(理论上),我们可以获得下图所示的运算时间(n=1536)。我们可以看到,对我们的器件(Virtex 6)来说,当级长为4位时可以获得最短运算时间。7Lyednc
7Lyednc
图9:流水线级长对最短执行时间的影响。
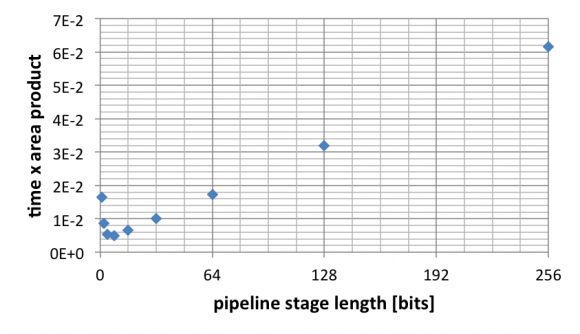
我们想要尽可能地减小时间与面积乘积。事实上,我们可以专注于最大限度地减小时间与FF数量的乘积,因为LUT数量基本上是常数。下图显示了不同流水线级长下的时间与FF数量乘积。当级长为8位时达到最小值。
7Lyednc
图10:流水线级长对时间与面积乘积的影响。
首次测试
基于NFC的ZKPK7Lyednc
作为第一次实际测试,我们实现了基于NFC的简化Schnorr ZKPK,详见我们的嵌入式测试平台介绍。这种个嵌入式平台是验证方,而PC(连接有PN532电路板)用作证明方。
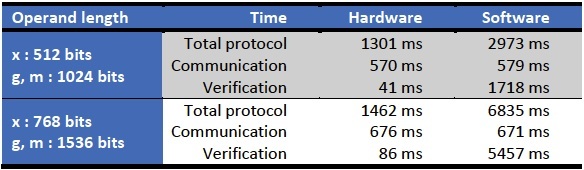
下表给出了不同操作数长度下的时序结果。很明显,当使用我们的硬件IP内核时,操作数长度对总的协议时间基本上没有影响。增加操作数长度会稍稍增加通信时间(这是预料中的)。然而,验证所需的时间将大大增加。
我们需要指出的是,通信占总时间的很大一部分。像产生随机数等一般数据操作也需要一定的时间。然而,我们的IP内核还无法克服这些挑战。
 7Lyednc
7Lyednc
软件控制方案对比全自动操作7Lyednc
实现完整的并行求幂内核是一个英明的决策吗?为什么不只是乘法器和一些控制软件来实现算法1?因为我们可以将我们的IP内核用作乘法器,我们能够非常容易的测试它。我们可以在相同的系统上比较这两种方法。
即使我们将操作数存储在IP内核的RAM中(因此没有额外的总线业务量),全自动操作的速度仍要比软件控制方案快一个数量级(见图2)。这是意料之中的。Linux不是一种实时操作系统。在操作系统处理中断之前,或者应用程序访问它们需要的资源(本例中为我们的存储器映射外设)之前,可能需要等待一定的时间。如果你知道一次求幂要求大约(7/4)t乘法(见算法1),这种“损失时间”会很快累加起来。
如果你知道将乘法器转变成并行求幂内核所需的额外逻辑只由FIFO和一些计数器组成,那么我们可以说额外的硬件是比较值得的。
小结和未来发展
我们已经表明,这种用于模并行求幂运算的IP内核的可定制VHDL设计是非常适合匿名信任加密系统的嵌入式实现的。我们已经见证了如何调整内核参数来满足用户的需要。
除了更为理论性的性能分析外,我们还在实际的嵌入式装置中使用了这个设计。作为我们未来工作的一部分,我们将继续为匿名信任证书开发完整的嵌入式应用程序。
进一步开发对象还将导向内核本身。目前内核只提供PLB接口。提供对AXI和Wishbone接口的支持“已经列在任务清单上”。
包括所有乘法与求幂技术文档和测试基准的完整VHDL设计已经在开源网站OpenCores上公开上线。只要有GNU较宽松通用公共许可(LGPL)协议就能免费下载VHDL源代码。
项目的网页地址:http://opencores.org/project,mod_sim_exp
原文作者:Geoffrey Ottoy、Bart Preneel、Jean-Pierre Goemaere、Nobby Stevens和Lieven De Strycker

 最前沿的电子设计资讯
最前沿的电子设计资讯
