
北京时间12月12日晚,Intel在圣克拉拉举办了架构日活动。Intel揭开了2021年CPU架构路线图、下一代核心显卡、图形业务的未来、全新3D封装技术,甚至部分2019年处理器新架构的面纱。
英特尔还介绍了在驱动不断扩展的数据密集型工作负载方面的战略进展,从而为PC和其他智能消费设备、高速网络、人工智能(AI)、云数据中心和自动驾驶汽车提供支持。
不仅展示了一系列处于研发中的基于10纳米的系统,将用于PC、数据中心和网络设备,并预览了其他针对更广泛工作负载的技术,还一连分享了聚焦于六个工程领域的技术战略,包括:
英特尔表示,对这些领域的重大投资和技术创新,将为更加多元化的计算时代奠定了基石,到2022年,潜在市场规模将超过3000亿美元。
近一段时间以来,业界一直非常期待看到Intel未来的架构路线图,但自Skylake以来却一直处于犹抱琵琶半遮面的状态。最近几个月Intel简单公布了一部分数据中心产品路线图,包括Cascade Lake,Cooper Lake和Ice Lake以及未来几代,但消费级产品却依旧难产。
在本次架构日活动上,Intel终于带来了消费级的PC处理器架构路线图和Atom架构路线图。
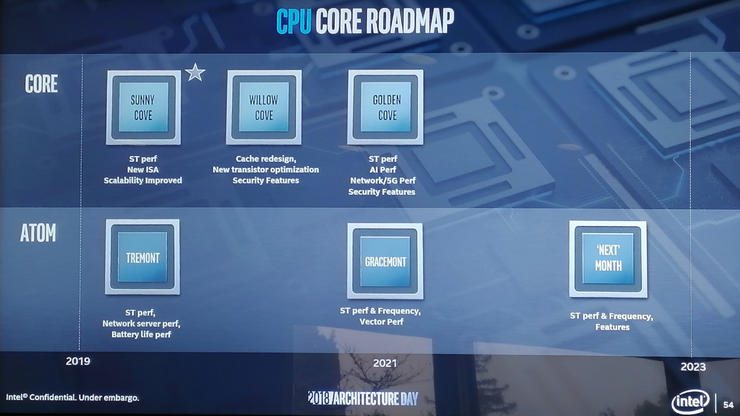
在高性能的Core系列产品线上,Intel列出了未来三年内的三个新代号:Sunny Cove、Willow Cove和Golden Cove,其中离我们最近的Sunny Cove将于2019年上市(PS:你猜会不会鸽^_^)。
据悉,Sunny Cove架构旨在提高通用计算任务下每时钟计算性能和降低功耗,将拥有AVX-512单元,并包含了可加速人工智能和加密等专用计算任务的新功能,将成为Intel下一代PC和服务器处理器的基础架构。
随后的Willow Cove在路线图上位于2020年,很可能也是10nm。Intel将此处的重点列为缓存重新设计(可能意味着L1/L2调整)、新的晶体管优化(基于制造)以及其他安全功能,可能是指新一类侧信道攻击的进一步增强。
Golden Cove则位于图表中的2021年,工艺制程仍是一个问号,可能是10nm也可能是7nm,Intel将进一步提升其单线程性能和人工智能性能,并在核心设计中增加了潜在的网络和AI功能,安全特性看起来也得到了提升。
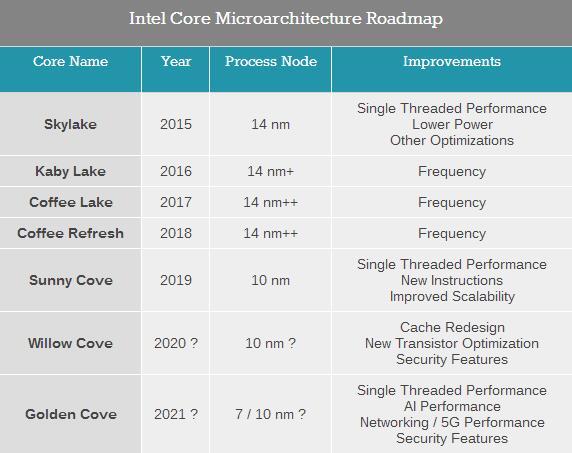
Atom系列低功耗处理器的架构路线图比酷睿系列的节奏慢,考虑到其历史,这并不奇怪。鉴于Atom必须适应各种设备,业界更多的是期望产品能够提供更广泛的功能,尤其是SoC方面。
即将在2019年推出的架构名为Tremont,专注于单线程性能、网络服务器性能以及电池续航时间的提升。紧随Tremont之后的将是Gracemont,Intel将其列为2021年的产品,可能会拥有更宽的矢量处理单元或支持新的矢量指令。
从路线图上看,Gracemont之后还会有一款“XXXmont”系列核心,Intel正在研究这款新内核在2023年时可能具备的性能、频率和特性。
上面这些是架构的名称,而实际产品可能可能会有另外的代号,也就是酷睿系列近些年来一直使用的“XXX-Lake”命名,比如代号为Ice Lake的处理器就是由Sunny Cove架构的CPU内核与Gen11核心显卡联合构成。
活动中的另一个值得关注的消息是,Intel未来的架构很可能与工艺制程脱离关系。Raja Koduri和Murthy Renduchintala博士解释称,为了让产品线拥有一定的弹性,未来这些架构的最新产品将以当时可用的最佳工艺制程推向市场。
虽然没有明说,但雷锋网认为这应该意味着目前已经名存实亡的“Tick-Tock”策略彻底被扫进了历史的垃圾桶,未来某些核心设计跨越不同制程的情况可能会成为常态。
在封装领域,英特尔推出的 Foveros 是业界首个真正的 3D 封装,可以把整个系统封进一颗芯片中,达成真正的 System in Package 概念,远比目前台积电与三星都在发展的 2D 或 2.5D 封装技术更为先进。
英特尔展示了Foveros全新3D封装技术,该技术首次引入了3D堆叠的优势,可实现在逻辑芯片上堆叠逻辑芯片,比目前台积电与三星在发展的 2D 或 2.5D 封装技术要更先进。英特尔预计将从2019年下半年开始推出一系列使用Foveros的产品。

首款Foveros产品将整合高性能10nm计算堆叠“芯片组合”和低功耗22FFL基础晶片。 英特尔称,它将在小巧的产品形态中实现世界一流的性能与功耗效率。
据称此封装技术可做到约1mm的超薄厚度,Raja还在现场秀出仅有12mm x 12mm尺寸的量产芯片。
Foveros为整合高性能、高密度和低功耗硅工艺技术的器件和系统铺平了道路,有望第一次将晶片的堆叠从传统的无源中间互连层和堆叠存储芯片扩展到高性能逻辑芯片,如CPU、图形和AI处理器。
因为设计人员可在新的产品形态中“混搭”不同的技术专利模块与各种存储芯片和I/O配置,该技术提供了极大的灵活性,并使得产品能分解成更小的“芯片组合”,其中I/O、SRAM和电源传输电路可以集成在基础晶片中,而高性能逻辑“芯片组合”则堆叠在顶部。
英特尔表示, Foveros将成为继2018年英特尔推出突破性的嵌入式多芯片互连桥接(EMIB)2D封装技术之后的下一个技术飞跃。
每次听到全新处理器架构的消息时,大家最期待的都是对于新架构的详细分析,以及相对前代的变化情况。
自Skylake于2015年首次推出以来,到目前为止Intel已经推出了Kaby Lake、Coffee Lake和Coffee Lake三代小改款,由于每代提升都不大,被玩家戏称为“挤牙膏”。虽然这次Intel展示了全新的Sunny Cove架构,但遗憾的是其信息还不够全面,主要集中在架构设计的后端部分。

Intel将其微体系结构更新分为两个不同的部分:通用性能提升和特殊用途性能提升,通用性能提升指原始IPC(每时钟指令)吞吐量或频率增加,IPC的增加可能来自核心更宽(每个时钟执行指令更多)、更深(每个时钟更多并行)或更智能(通过前端更好的数据传输),而频率通常是实现和过程的函数,而特殊用途性能提升可以通过其他加速方法(如专用IP或专用指令)来改进特定方案中使用的某些工作负载。
据悉,Sunny Cove在通用性能和特殊用途性能两个方面有着全方位的提升。在架构的后端部分,Intel已经做了包括增加高速缓存大小、增加核心执行宽度、增加L1存储带宽等改进。
Sunny Cove架构的L1数据缓存从32KB升级为48KB,通常当缓存容量增大时,缓存未命中的概率将以平方根的比例降低,因此Sunny Cove架构的L1缓存未命中率理论上可减少22%。同时Sunny Cove架构Core和Xeon处理器的L2缓存也将分别比目前的256KB和1MB有所增加,具体容量尚未可知。
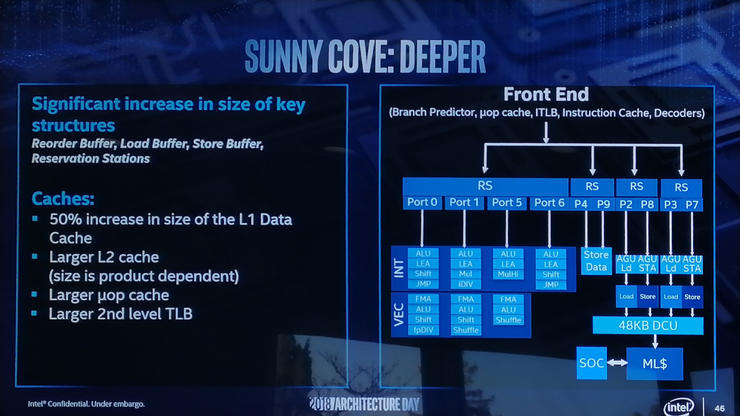
此外,微操作(uOp)缓存和二级TLB虽然不属于后端,但其容量也都相比目前有所增加,这将有助于机器地址转换。图中还可以看到一些其他更改,例如执行端口从8增加到10,允许一次从调度程序中获得更多指令;重排序缓冲区的调度也从每个周期4条指令增加到5条指令;端口4和端口9链接到了一个循环数据存储,使带宽加倍,但AGU存储功能也增加了一倍,这将有助于增加L1-D大小。
Sunny Cove架构的执行端口也发生了重大变化,详情见下图:
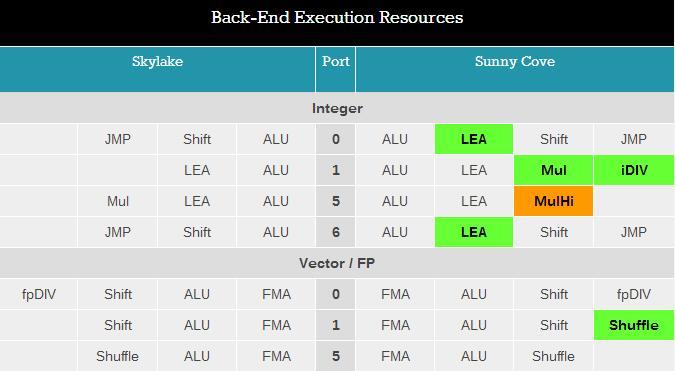
我们看到Intel为核心的整数部分配备了更多LEA单元,以帮助进行内存寻址计算,可能有助于通过需要频繁内存计算的安全缓解来帮助改善性能损失,或者帮助提供具有恒定偏移的高性能阵列代码。端口1从Skylake端口5获取MUL(乘法)单元,可能用于重新平衡,但此处还有一个整数分频器单元。这是一个小小的调整,Cannon Lake在其设计中也有一个64位IDIV(带符号整数除法)单元,在这种情况下,它将64位整数除法从97个时钟(混合指令)降低到18个时钟,Sunny Cove可能与之类似。
在整数运算单元方面,端口5的乘法单元已成为“MulHi”单元,在其他架构中,它会在寄存器中留下最重要的半字节以便进一步使用,但目前不能确定它在Sunny Cove核心中的位置究竟是什么。
在浮点运算单元方面,Intel增加了洗牌资源,这是出于消除代码中瓶颈的考虑。Intel没有在核心的浮点运算部分说明FMA(熔加运算)的功能,但既然核心内有一个AVX-512单元,这些FMA中就应至少有一个与之交互。Cannon Lake只有一个512位的FMA,这个FMA很可能在这里,而Xeon的可扩展版本可能会有两个FMA。
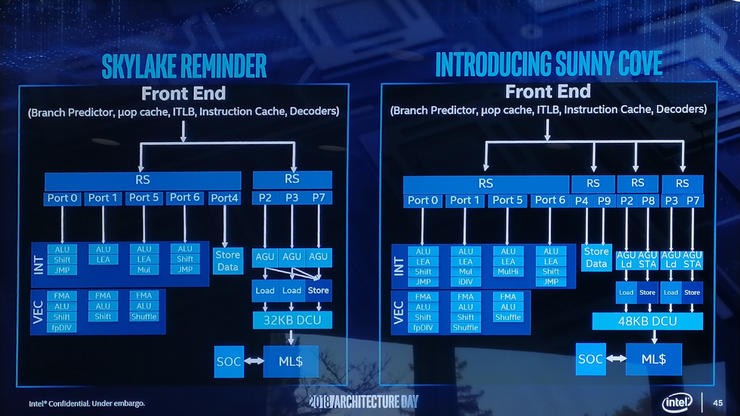
Intel列出的其他更新包括分支预测器的改进,以及由TLB和L1-D带来的有效负载延迟降低。不过雷锋网获悉,有人指出这些改进无法帮助到所有用户,可能只有全新的算法才能使用这些特定部分的核心能力。
除了架构上的差异,Sunny Cove还增加了新的指令以帮助加快专业计算任务。随着AVX-512单元的出现,新架构将支持用于大算术计算的IFMA(带符号熔加运算)指令,这些指令在密码学中非常有用。Sunny Cove还支持Vector-AES、Vector Carryless Multiply、SHA、SHA-NI以及Galois Field指令,这些指令也是密码学的一些元素中的基本构建块。

Sunny Cove支持更大的内存容量,其主存储器分页表从4层增加到了5层,支持最多57bit线性地址空间和最多52bit物理地址空间,这意味着服务器处理器理论上可支持单插槽4TB内存。
根据Intel之前的Xeon路线图,Sunny Cove将在2020年与Ice Lake-SP一起在服务器领域上市。为了安全起见,Sunny Cove具有多密钥全内存加密和用户模式指令预防功能。
2015年,Intel推出了采用Gen9核心显卡的Skylake处理器,不过随后Kaby Lake和Coffee Lake的核心显卡都只是Gen9.5而非Gen10。实际上,Intel 10nm Cannon Lake处理器本该对应Gen10,但Intel从未发布过带核心显卡的PC端Cannon Lake处理器。
今天,Intel首席架构师、核心与视觉计算集团高级副总裁兼边缘计算解决方案总经理Raja Koduri直接公布了全新的Gen11核心显卡,并重申了在2020年推出独立图形处理器的计划。
根据路线图,Gen11核心显卡将于2019年开始随10nm处理器一同面世,配备64个EUs(增强型执行单元),运算规模是此前Gen 9核心显卡的2倍,浮点运算性能超过1TFlops。这64个EUs被分成4个切片,每个切片由2个8EUs的子切片组成,每个子切片均拥有指令缓存和3D采样器,而较大的4个切片则拥有2个媒体采样器、1个PixelFE以及额外的加载/存储硬件。
Intel并没有透露太多关于如何提高EU性能的详情,但表示EU内部的浮点运算单元接口是重新设计,支持快速(2x)FP16性能。每个EU均像以前一样支持7个线程,这意味着整个GPU有512个并发管道,Intel表示已经重新设计了内存接口,并将GPU的L3缓存增加到3MB,相比Gen9.5增加了4倍。
Gen11核心显卡的一项重大改进是终于支持了瓦片式渲染,这让Intel成为继2014年的NVIDIA和2017年的AMD之后,最后一个实现这一特性的PC GPU供应商。虽然瓦片式渲染不是解决GPU性能问题的灵丹妙药,但是优化良好的瓦片式渲染可以很好的适应核心显卡的带宽限制。
与此同时,Intel的无损内存压缩技术也有所改善,在最佳情况下性能可提高10%,平均可提高4%。GTI接口现在支持每个时钟读写64字节以增加吞吐量,以与重新设计的内存接口相配合。
Gen11核心显卡还支持Intel全新的多速率着色技术Coarse Pixel Shading(粗像素着色),这与NVIDIA的可变像素着色很相似,能让GPU减少阴影部分像素所需的渲染操作量。Intel为CPS展示了两个演示,其中像素阴影分别作为与相机距离和屏幕中心相关的一个函数,当物体离相机或屏幕中心较远时渲染量减少,其设计目的是帮助VR实现注视点渲染等功能,Intel表示游戏在支持这一技术后可提高约30%的帧率。
Raja Koduri宣布了Intel独立显卡业务的新产品品牌:Xe,目前仍被非正式的称为“Gen12”系列,将从2020年开始覆盖从客户端到数据中心的所有领域,也涵盖了未来的核心显卡解决方案,Intel希望Xe从入门到中档,再到发烧友以及AI,都能向竞争对手最好的产品发起竞争。
Xe将从10nm节点开始,为未来几代图形奠定基础,并将遵循Intel的单一堆栈软件哲学,即希望软件开发人员能够利用CPU、GPU、FPGA和AI,所有这些都使用同一套API,这表明Intel已经准备好围绕一个品牌向前发展。
作为架构日活动的一部分,Intel在现场进行了大量芯片演示,据称这些演示均是基于新的Sunny Cove核心和Gen11核心显卡,目前的演示涉及项目包括7-Zip应用和铁拳7游戏两部分。
7-Zip项目相对直接,演示机的同频性能相较于SkyLake平台提高了75%,展示了Sunny Cove架构的Vector-AES和SHA-NI等新指令所带来的特殊用途性能提升。而在铁拳7中,Sunny Cove+Gen11的演示机与SkyLake+Gen9相比更顺畅,完全超出30fps的最低要求。
英特尔还公布了英特尔傲腾技术以及相关产品的最新情况。作为一款新产品,英特尔傲腾数据中心级持久内存集成了内存般的性能、数据的持久性和存储的大容量。
这项技术通过将更多数据放到更接近CPU的位置,能够提高使应用在AI和大型数据库中的更大量的数据集能够的处理速度。
其大容量和数据的持久性减少了对存储进行访问时的时延损失,从而提高工作负载的性能。英特尔傲腾数据中心级持久内存为CPU提供缓存行(64B)读取。
一般来说,当应用把读取操作定向到傲腾持久内存或请求的数据不在DRAM中缓存时,傲腾持久内存的平均空闲读取延迟大约为350纳秒。
如果实现规模化,傲腾数据中心级固态盘的平均空闲读取延迟约为10,000纳秒(10微秒),这将是显著的改进2。
在一些情况下,当请求的数据在DRAM中时,不管是通过CPU的内存控制器进行缓存还是由应用所引导,内存子系统的响应速度预计与DRAM相同(小于100纳秒)。
英特尔还展示了基于英特尔1 TB QLC NAND裸片的固态盘如何把更多海量数据从硬盘迁移到固态硬盘,从而可以更快访问这些数据。
英特尔傲腾固态盘与QLC NAND固态盘相结合,将降低对最常用数据的访问延迟。总体来说,这些对平台和内存的改进重塑了内存和存储层次结构,从而为系统和应用提供了完善的选择组合。
英特尔宣布推出深度学习参考堆栈(Deep Learning Reference Stack),这是一个集成、高性能的开源堆栈,基于英特尔至强可扩展平台进行了优化。
该开源社区版本旨在确保人工智能开发者可以轻松访问英特尔平台的所有特性和功能。深度学习参考堆栈经过高度调优,专为云原生环境而构建。该版本可以降低集成多个软件组件所带来的复杂性,帮助开发人员快速进行原型开发,同时让用户有足够的灵活度打造定制化的解决方案。
(综合整理自雷锋网、智东西)
 最前沿的电子设计资讯
最前沿的电子设计资讯
