
近日在Micron Insight 2019期间美光科技推出了X100 SSD,这是美光第一款3D XPoint技术的产品,旨在填补DRAM和NAND闪存之间的存储市场空白。
“X100是基于第一代3D XPoint技术的产品,年内会向少量受邀客户发送样品。”美光技术开发高级副总裁Naga Chandrasekaran透露,同时美光第二代3D XPoint也在研制中,未来还将会有显著的性能提升。
现在,X100的每秒读写操作次数(IOP)高达2.5M——相比之下英特尔Optane P4800X最高读写速度为500K IPOs;在读、写和读写混合模式下带宽超过9GB/s,显著快于目前的竞品NAND。
美光新兴存储副总裁Bob Brennan强调2.5M IOPs的读写速度比现有世界上所有SSD都快,他向记者展示了美光几种不同存储介质的性能差异。
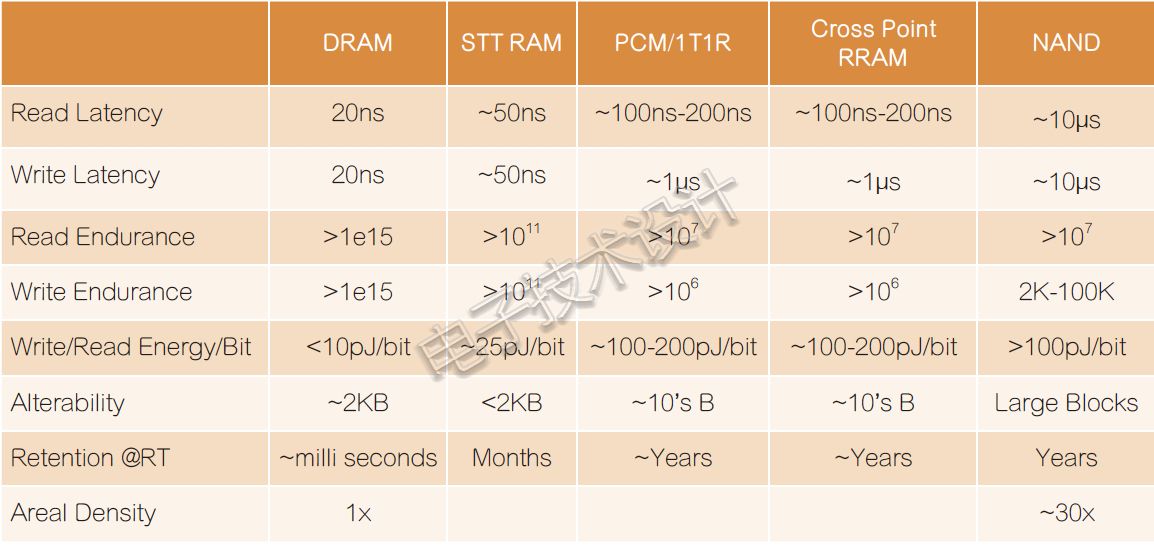
图1:DRAM、NAND和3D XPoint技术的性能对比。
“X100比NAND具有更高的性能和耐久性,比DRAM具有更大的容量和持久性。未来3D XPoint其他产品还可以通过降低工艺尺寸、添加更多层、增加每个单元内的数据位数来增加产品容量。”他指出。
由于3D XPoint的市场定位是填补DRAM和NAND之间的市场空白,这意味着它的售价必须比DRAM更便宜,才能取得商业市场的成功。在三星Z-Nand、东芝XL -Flash等低延时竞品的包围中,X100的市场空间还有待观察。但在本次Micron Insight期间,记者发现,比起新兴存储介质对未来的影响,存储本身与计算之间的融合,是更值得关注的趋势。
过去人们普遍认为处理器是最重要的,但现在计算能力已不再单纯由处理器性能决定。处理器跟存储器之间的数据传输,也面临瓶颈,从而限制了计算能力的发展。
在Micron Insight 2019期间的一个小组讨论中,Cadence首席执行官Lip-Bu Tan就指出人工智能时代出现了更多需要及时分析的数据,为CPU/GPU带来巨大压力,如何把存储和数据拉近显得尤为重要,而且对很多应用来说,把数据放到云端是不适合的,比如工业自动化,数据存储距离一定要近才有效率。
有数据指出当今系统要消耗80%的电能来将数据从内存传输到计算单元,如CPU/GPU/NPU等,高通公司首席执行官Steve Mollenkopf也同时指出,5G的移动设备制造商如果不进行架构更改,也会遇到严重的电池寿命问题。

图2:Micron Insight 2019 CEO炉边谈话。从左至右分别为Nicholas Thompson(《Wired》主编),Lisa Su(AMD首席执行官),Lip-Bu Tan(Cadence首席执行官),Steve Mollenkopf(高通首席执行官)和Sanjay Mehrotra(美光首席执行官)。
这次炉边谈话的CEO们的共识是:数据处理必须靠近或移入内存。
对此,美光首席执行官Sanjay Mehrotra直接指出:昨天的计算体系结构已不适用于明天,从长远来看,我们认为计算最好在内存中完成。
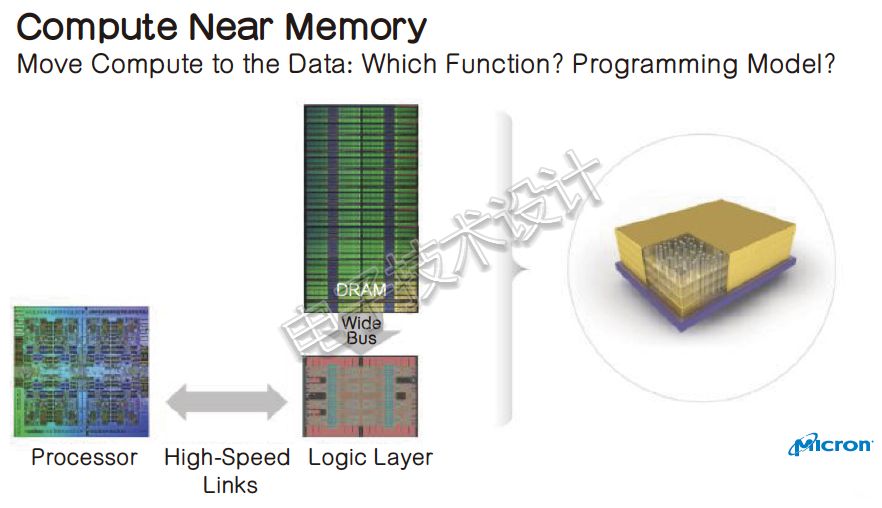
图3:从长远来看,数据处理必须靠近或移入内存,计算在内存中完成。
针对内存与计算架构的发展,Brennan向记者分享了三个阶段:“第一个阶段是让内存非常靠近逻辑计算,用大量的高带宽数据总线把内存和计算处理器更紧密连在一起;第二个阶段就是在内存中进行计算处理,这个概念始于1994年,实现量产在技术上很难,因为软件和逻辑是分开的两部分,但这样没有传输、延迟等问题,并且大幅提升效能。第三个激动人心的阶段则是神经形态(neuromorphic)计算,使用内存架构本身做计算。据称美光也有和IMEC合作开发这个尚处于研究阶段的技术。”
近日,美光很大的一个进展是基于去年对硬件和软件初创公司FWDNXT的收购,将计算,内存,工具和软件集成到了AI开发平台中。
同时反过来,该平台提供了探索针对AI工作负载优化的创新内存所需的构造块。美光深度学习加速器(DLA)能提供编程软件平台来支持机器学习和神经网络。
未来几年,为了解决AI带来的大量负载,对更高内存带宽的需求、减少与内存互连功耗都变得更加重要,将内存堆积在逻辑上,从而实现边缘神经网络的方式或许会复兴。
本文为《电子技术设计》2019年12月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。
 最前沿的电子设计资讯
最前沿的电子设计资讯
