
11月10日,由全球电子技术领域知名媒体集团AspenCore主办的国际集成电路展览会暨研讨会(IIC Shenzhen 2022)的国际工业4.0技术与应用论坛上,中科院深圳先进技术研究院助理研究员杨永魁博士发表了“MCU智能化技术探索”主题演讲。
云端应用多用于推理训练,它的特点是大数据、大模型,它对于性能的要求很高,但对于功耗不敏感。而对于更小的终端应用,例如无人机、手机、可穿戴设备等,他们对功耗的要求则非常的高,针对这些不同的技术路径,芯片的要求是不一样的。我们对于终端会针对低功耗,低成本做一些特殊的优化。
常用的神经网络比如ResNet、VGG,图象识别的准确度可以达到80%甚至90%,但是它的计算量也是相当大的,在计算一张图片时计算量可以达到几十G的Ops,而它的存储空间需要几十兆、上百兆。可是远程侧设备的特点和云端是完全不一样的,比如云端GPU加速卡内存就有几十G,存储甚至可以达到TB级别,到了手机内存就只有几GB,存储也往往只有几百GB,如果到了IT/OT这种更远程的应用,它的存储和内存就更受限了,通常只有几百KB的内存空间和几MB的存储空间。
MCU的特点就是小存储,小算力,但是神经网络的特点又是计算密集型和存储密集型,所以我们需要做很多的优化,才可以使这些神经网络跑在我们的小芯片上。
第一种MCU智能化技术路线是通过工具链的软件方式,现在各个大厂已经用得非常成熟,比如ST的NanoEdge Studio,可以把在Keras、PyTorch上面训练的模型部署到32位的MCU上。通过把一些运行好的模型文件利用工具链进行压缩,就可以大大降低模型所占用的存储空间,然后放到很小的MCU上。这种技术路线可以识别CIFAR网络,量化后存储只需要133KB,必须的计算只要24.7M Ops、99.1ms的处理能力。

第二种MCU智能化技术路线叫数字-AI加速器,如果我们要把神经网络往数字型的AI加速器上部署,我们就必须对其进行优化。
对于高效数据流,比方说如果是权重固定的话,因为AI指定网络计算是一些重复循环的计算,它的权重是可以共享的,这种情况下我们可以减少它对外部存储的访问。比如输入固定权重每次都在改变,在这种情况下我们要在硬件架构上进行一些优化。
对于硬件算法协同优化,比如量化,我们知道训练与训练完的神经网络一般是一些4位、32位、64位浮点数,它在硬件实现上代价很高,所以可以把它量化成1位或者2位这种小型化的神经网络。还有剪枝条,就是把一些不需要的连接链路去掉,而且不会对神经网络的准确度造成太大的影响。
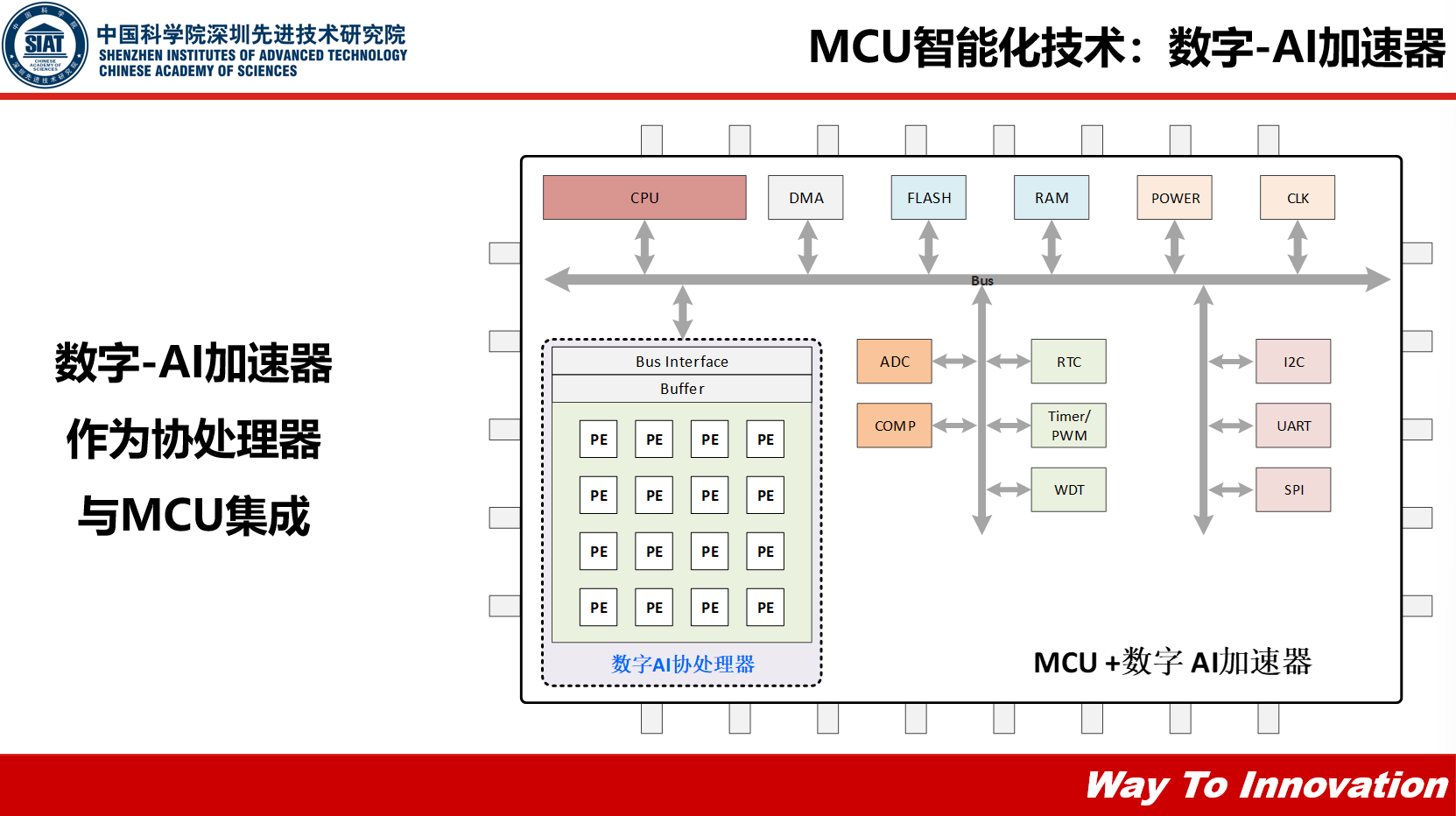
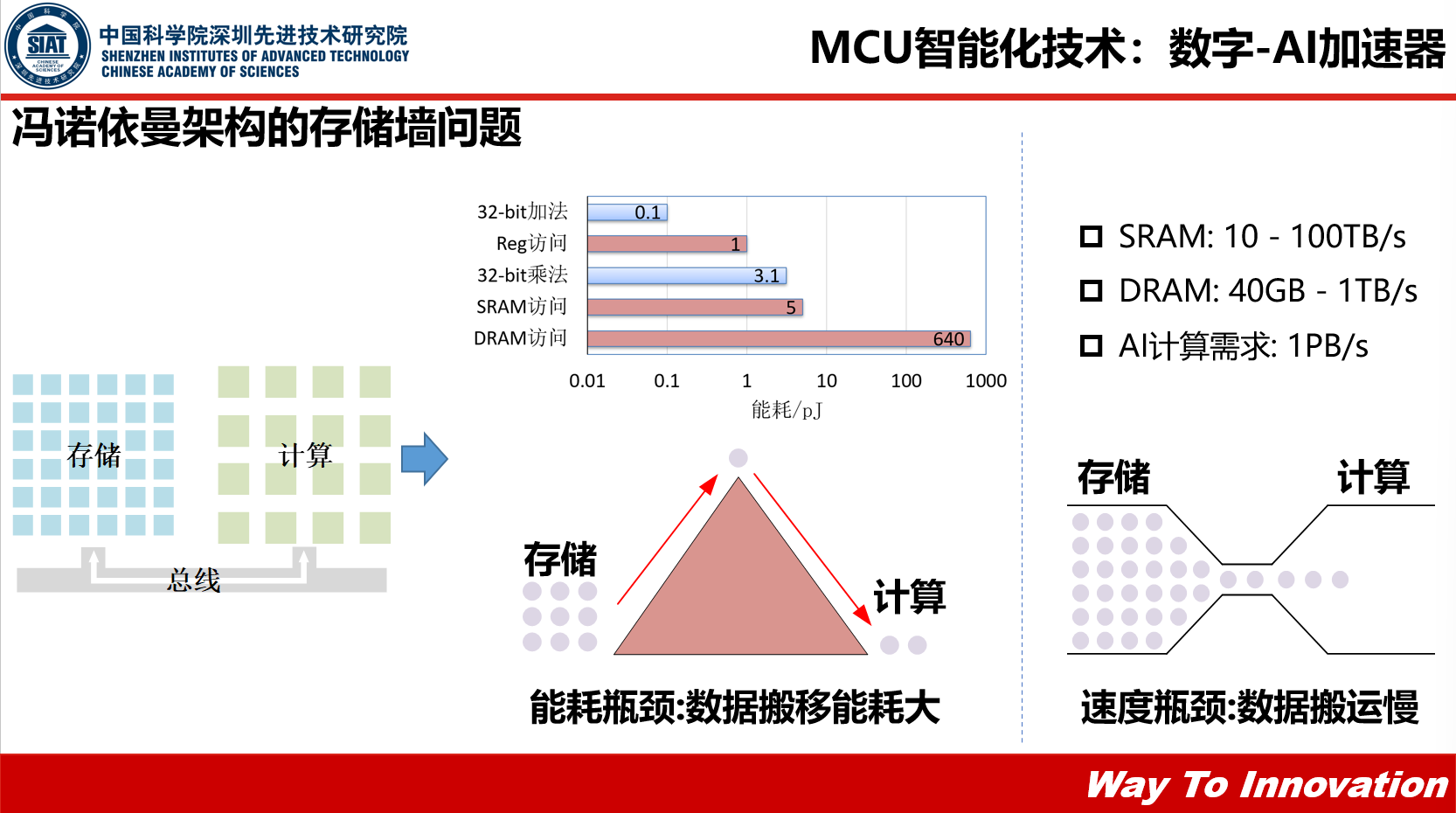
数字-AI加速器采用冯诺依曼架构,存储和计算是分开的,是通过一个主线将它们连接在一起,这种架构在物理上有很大的局限性:
为了解决上述瓶颈就要用到这个新的技术——存算一体,或者叫存内计算加速器,杨永魁博士简单描述了它的基本工作原理:“我们需要定位一个数模转化,转化成模拟值,再存储、搬移内部进行模拟域的计算,计算完之后,我们输出Y1、Y2,通过一个ADC,将模拟值转化成数字值,完成外面的系统的交互。”
“忆阻器的方式是可以很好的实现一个模拟域的计算。”杨永魁说,“如果我们用忆阻器实现模拟域的计算的话,我们可以输入一个V,左边的X1跟X2,通过忆阻器的G1和G2,可以得出它的电流是一个累加乘的状态,这个累加乘就是神经网络里面最底层的算子。” SRAM实现的基本原理与忆阻器类似,它用SRAM内部拟存储的值,去控制支线上的电流,也可以实现类似忆阻器的累加关系。
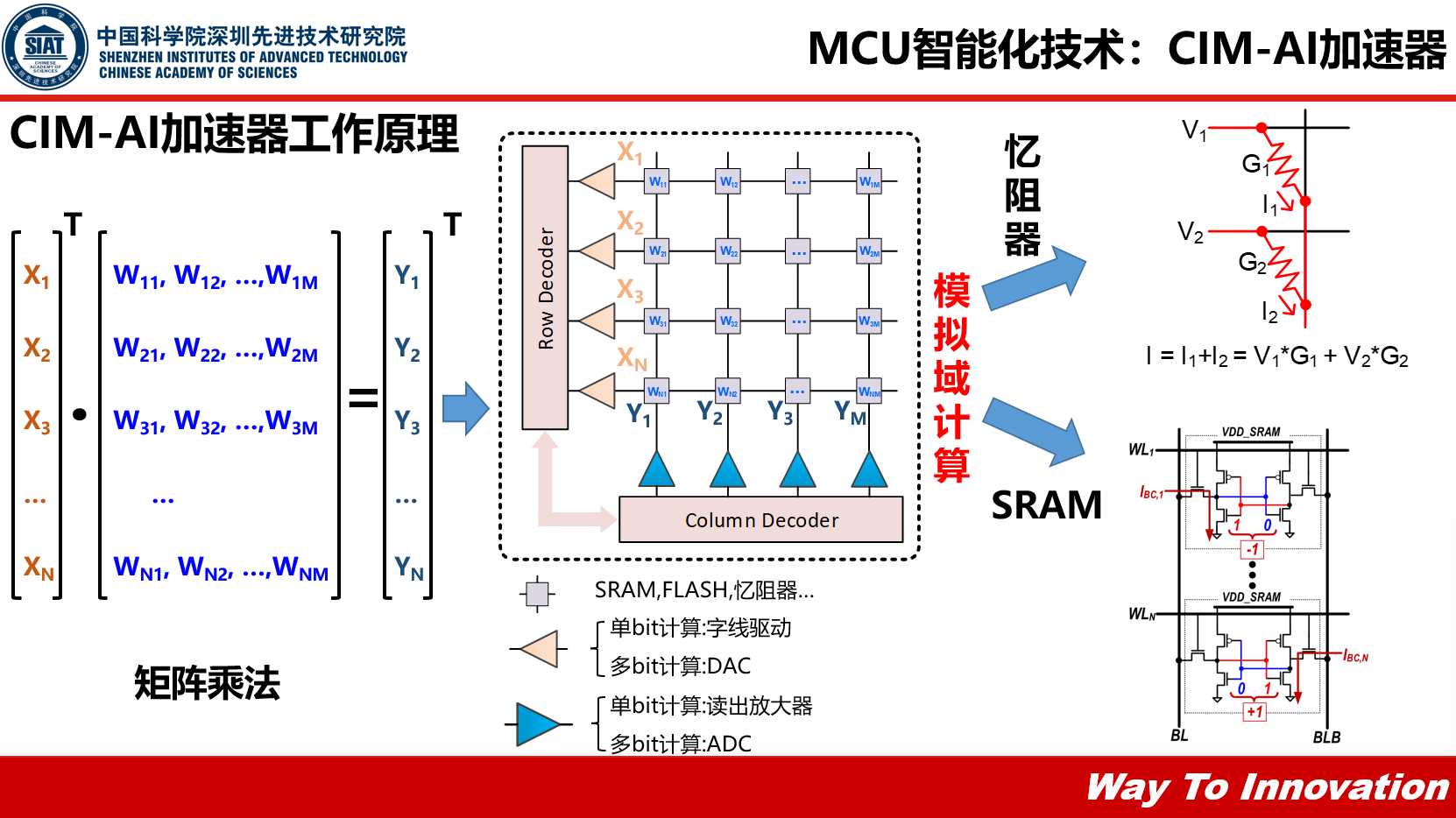
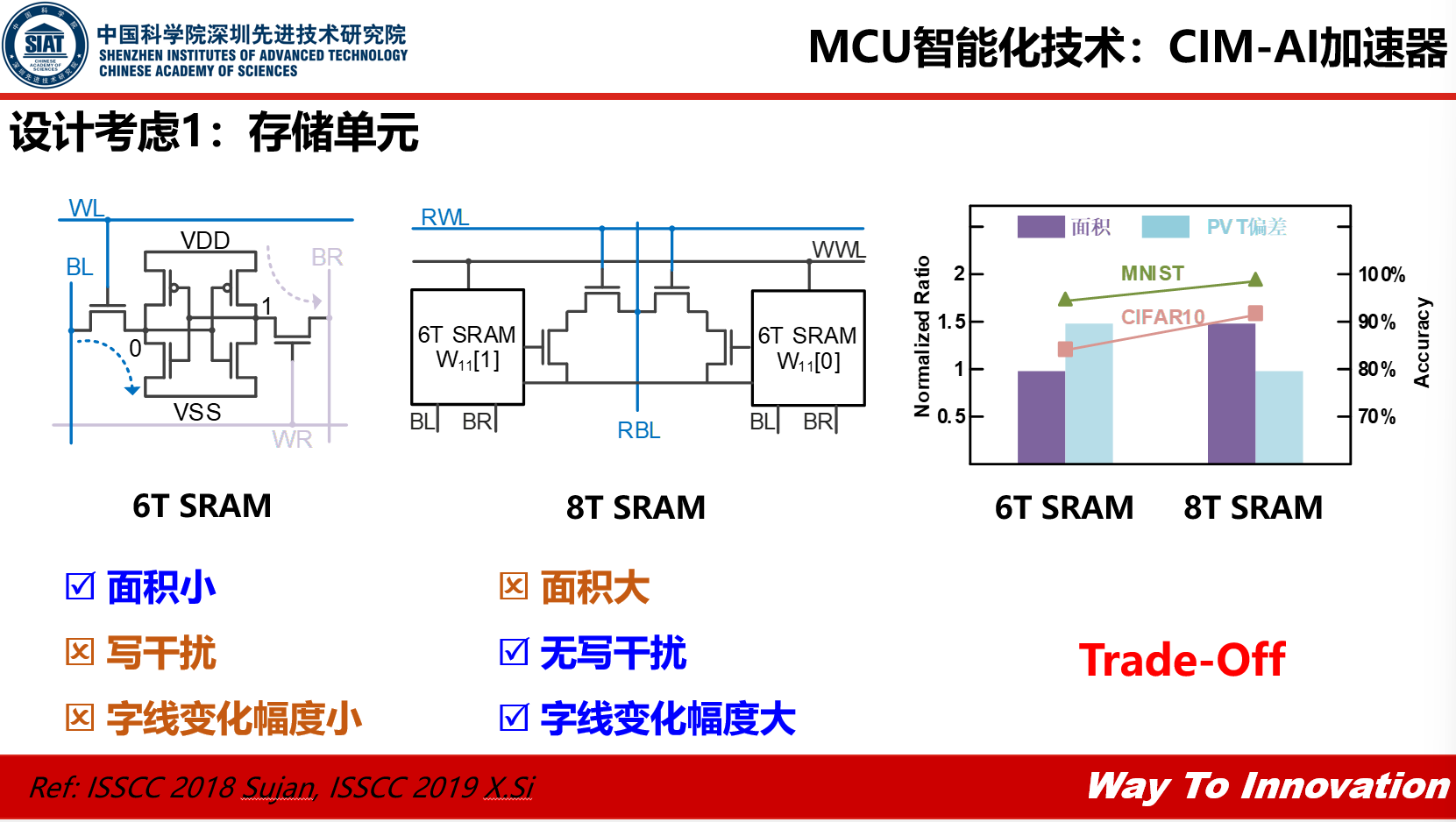
那么在做CIM-AI加速器设计时我们应该有些什么设计考虑呢?
1.存储单元,以SRAM为例,6T SRAM是很标准的SRAM,可以通过控制它的读写,实现储内计算,它的优点是只需要6个晶体管面积比较小,缺点是存在写干扰和字线变化幅度小。而8T SRAM就没有写干扰和字线变化幅度小的问题,但同时8T SRAM就要比6T SRAM大一些。所以8T SRAM在执行神经网络的时候,识别的准确度比6T的高,它的PVT偏差性能会更好一点,但面积就要比6T的大,因此我们需要就面积、准确度、能耗达到一种平衡。
2.ADC的功耗优化,也就是模拟到数字转化的功耗优化。ADC占的功耗比将近三分之一到一半,这是因为是ADC需要的分辨率很高,而ADC的分辨率和功耗是呈一种指数上升的关系。所以我们可以根据每一层神经网络权重的稀疏程度进行优化,可以把ADC每一层网络的分辨率调整成不同的比特数,这样就可以把神经网络的能耗降下来。
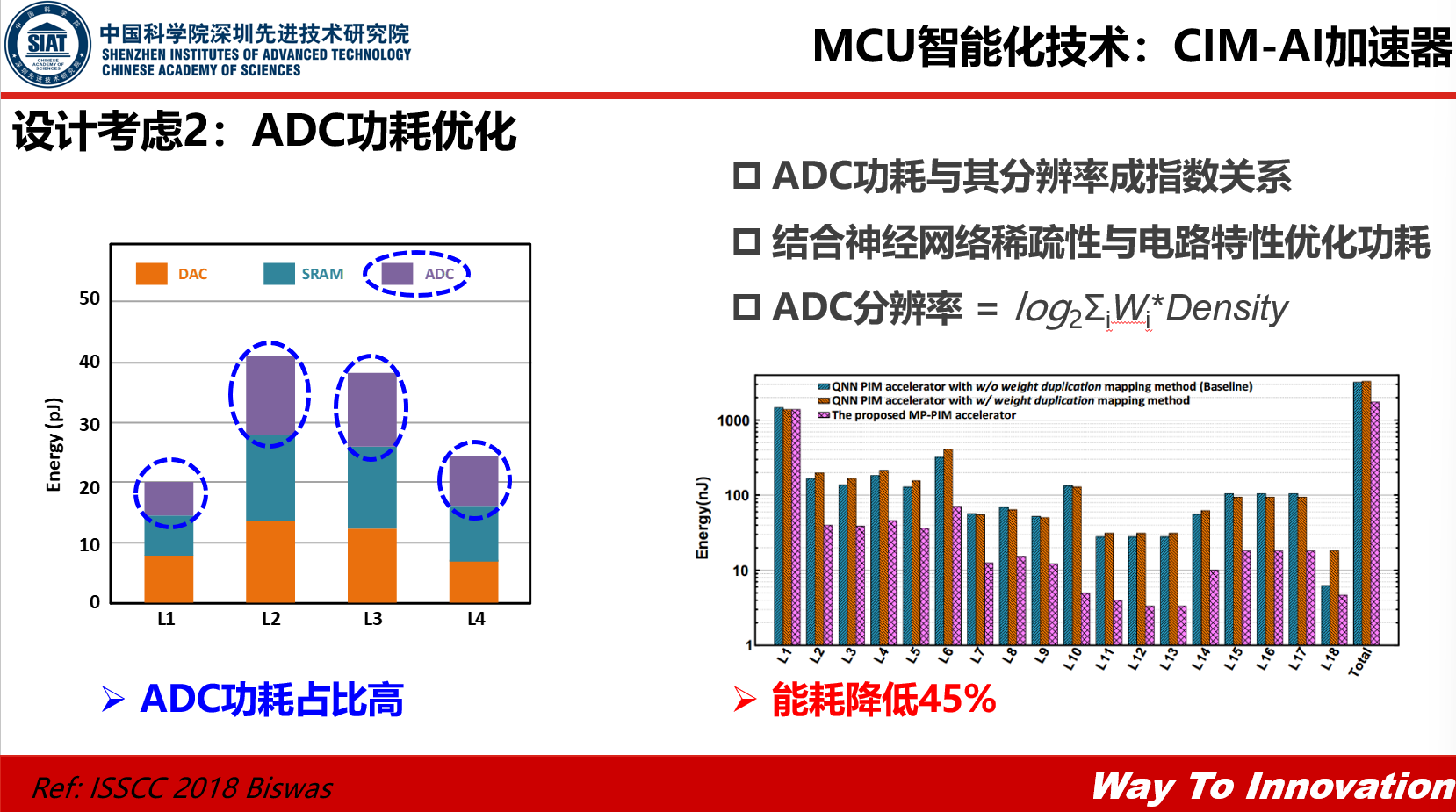
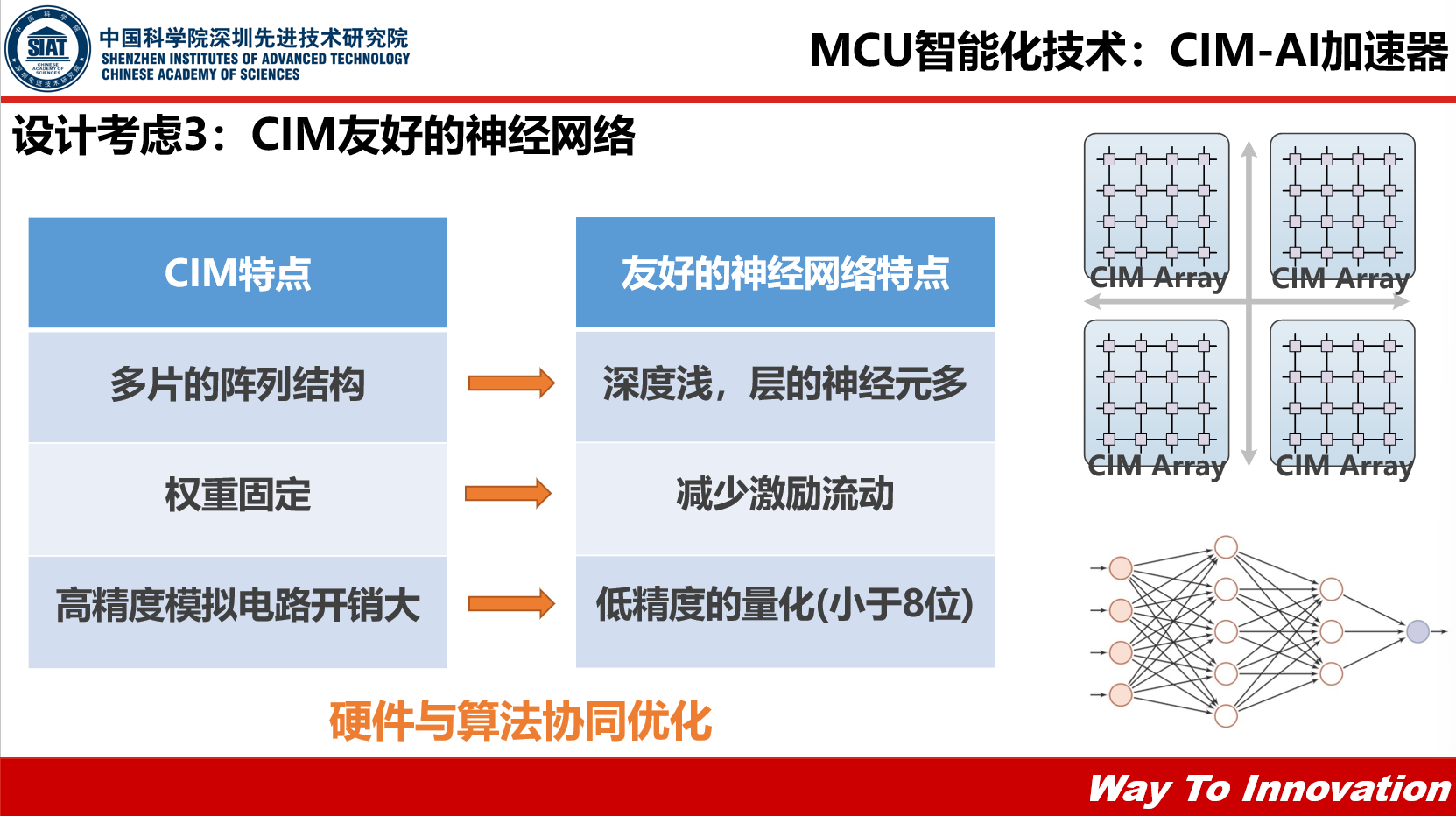
3. CIM友好的神经网络,一方面针对CIM的特点设计多片的阵列结构,设计的时候使神经网络深度较浅,每一层的神经元较多,另一方面将权重固定,减少激励的流动,提高计算的效率,还有就是针对模拟电路高精度开销大,做一些低精度的量化,得到一个整体比较优化的情况。
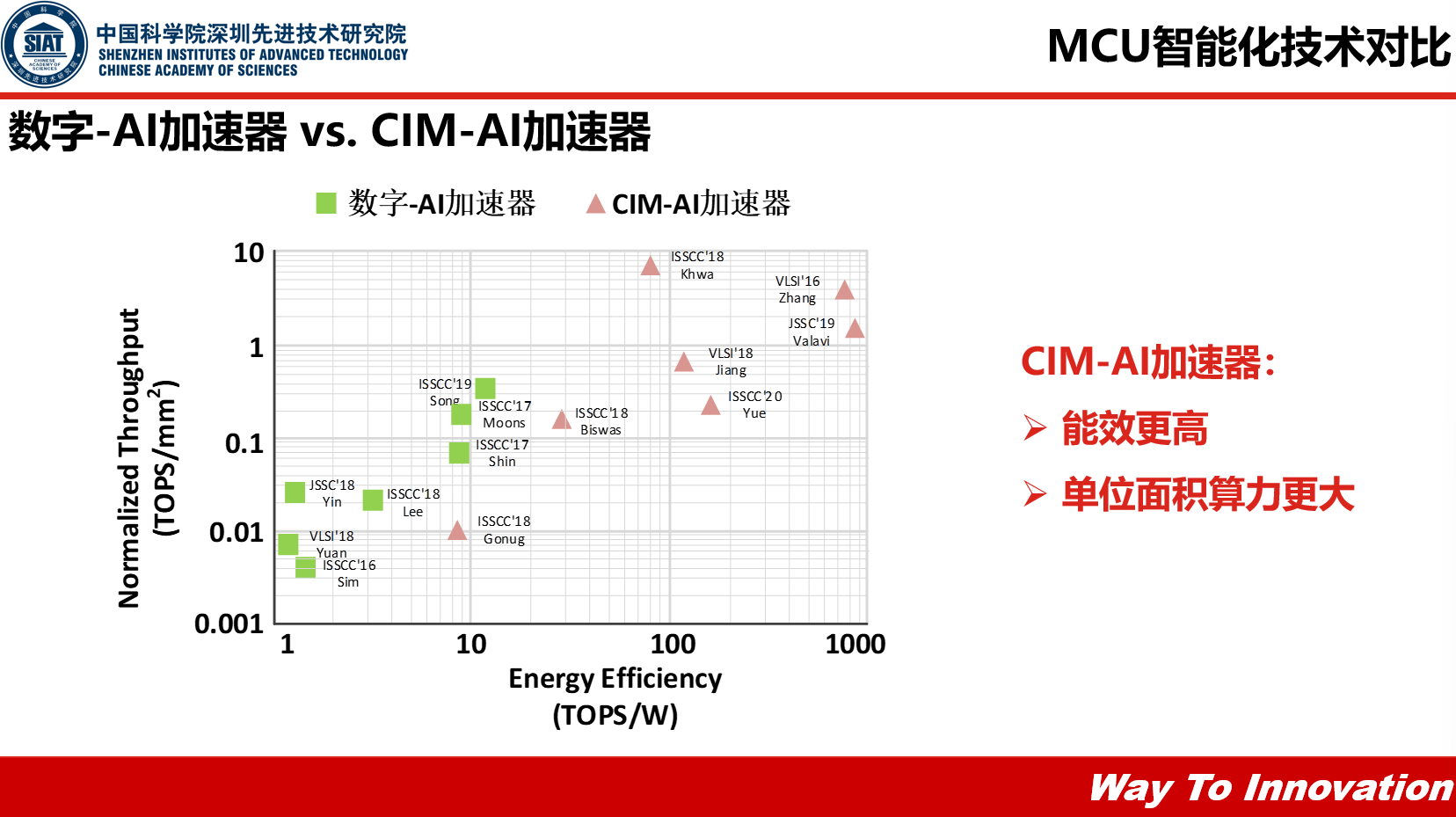
杨永魁表示:“这个表格(表格见下图)列举了当前的存算一体,CIM-AI加速器的能效和吞吐量的对比,可以看到这个吞吐量中,纵坐标,粉色的存算一体加速器会比数字类型的高出很多,同时它的能效,每W的计算的算力比传统的数字-AI加速会高出10倍甚至百倍的效果,因此我们说存算一体能效相当高,单位面积的算力也会大很多。”
从算力、功耗、成本、可编程性、稳定性还有研发周期对这三个MCU智能化技术做一个简单的总结:
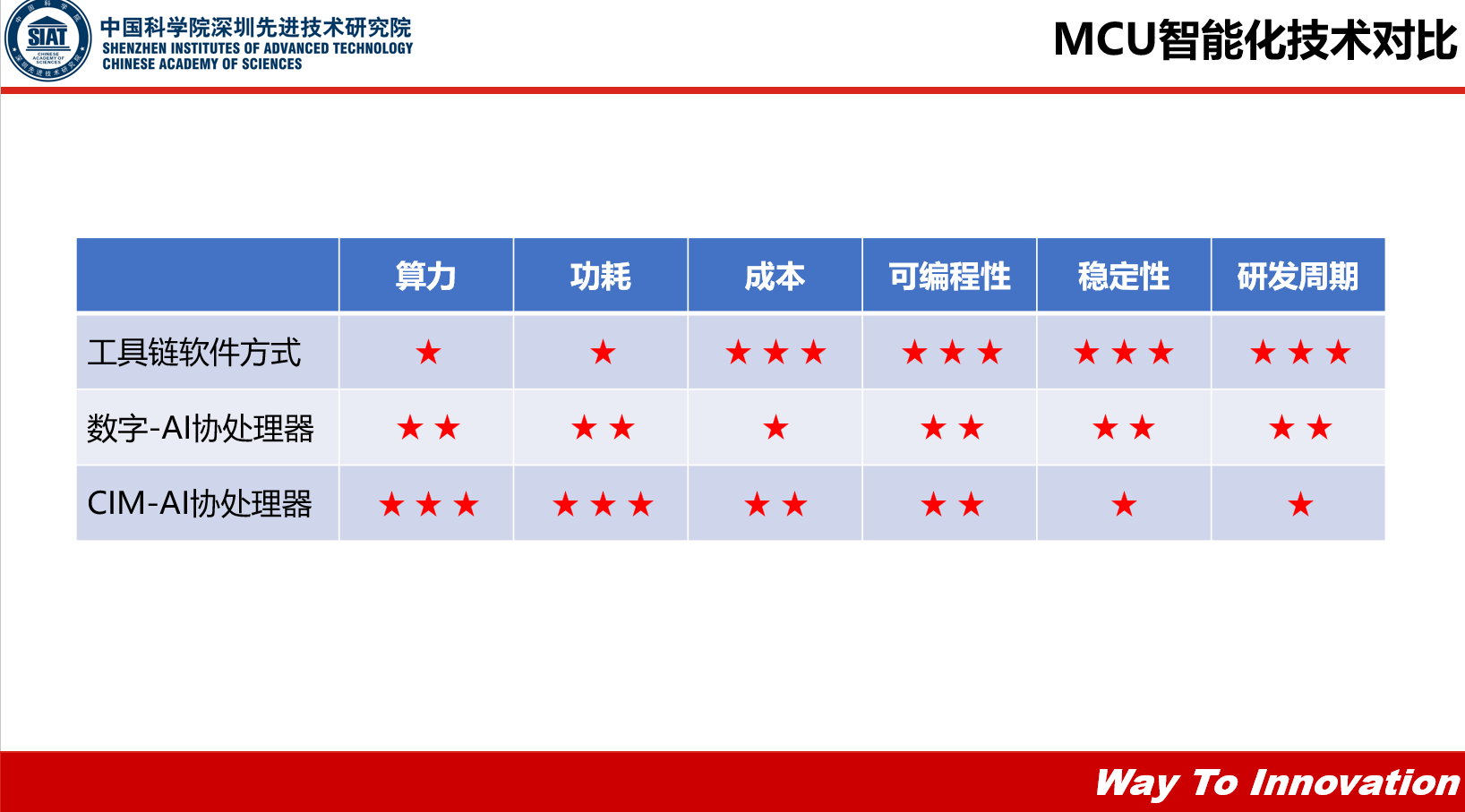
工具链软件方式成本很低,也不需要改进硬件框架,但是它的算力跟功耗是没有太大的优势的。
数字-AI协处理器,算力和功耗都表现不错,但是它的成本也会相对高一些,因为它单位面积的算力比较小。
CIM-AI协处理器,算力、功耗和成本都有一些优势,但是从其他维度看,它的可编程性、灵活性肯定没有工具链软件的方式灵活,还有它的稳定性也比较差。
最后杨永魁博士总结道:“如果我们从研发周期来看,个人觉得工具链肯定是最快的,不管从应用方还是芯片方,都是很快的一个方式,数字-AI协处理器居中,存算一体这个因为涉及到数字跟模拟,还有算法,需要一个协同,所以个人觉得它的研发周期会长很多。”
 最前沿的电子设计资讯
最前沿的电子设计资讯

