
你对人工智能(AI)和机器学习(ML)感到好奇吗?你想知道如何在你已经使用过的MCU上使用它吗?在本文中,我们将向你介绍MCU上的机器学习。本主题也称为微型机器学习(TinyML)。请准备好在剪刀石头布游戏中输给ESP-EYE开发板。你将了解数据收集和处理、如何设计和训练AI以及如何让它在MCU上运行。此示例为你提供了从头到尾完成你自己的TinyML项目所需的一切。
你肯定听说过DeepMind和OpenAI等科技公司。他们凭借专家和GPU能力在ML领域占据主导地位。为了给人一种规模感,最好的人工智能,比如谷歌翻译所使用的人工智能,需要进行数月的训练。他们并行使用数百个高性能GPU。TinyML通过变小来稍微扭转局面。由于内存限制,大型AI模型不适合MCU。下图显示了硬件要求之间的差异。
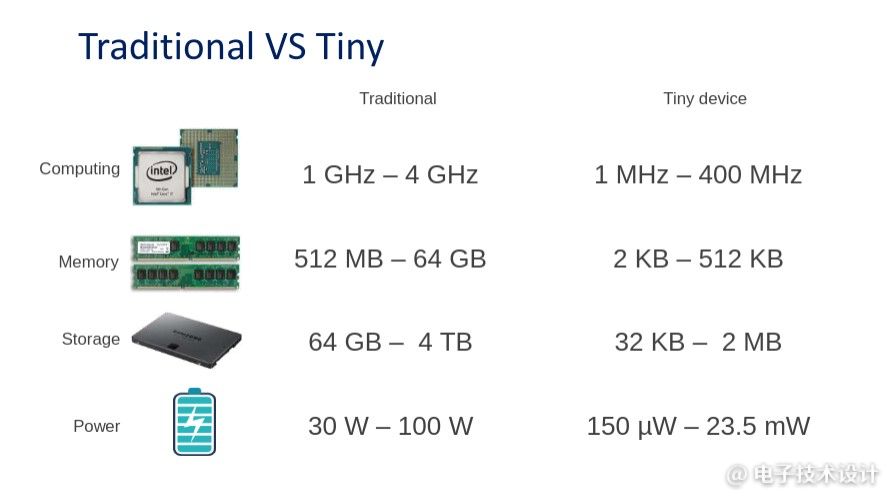
与在云中使用AI服务相比,MCU上的ML有哪些优势?我们发现了七个主要优势:

你有没有在与AI的石头剪刀布中输过?或者你想通过打败人工智能来打动你的朋友吗?你将使用TinyML对抗ESP-EYE开发板。要使这样的项目成为可能,你需要学习五个步骤。以下部分提供了必要步骤的高级概述。如果你想仔细查看,请参阅我们的项目存储库中的文档。它解释了实用的细节。
收集数据是ML的重要组成部分。为了让事情运行起来,你需要拍摄用你的手形成石头剪刀布手势的图像。图片越独特越好。AI将了解到你的手会处于不同的角度、位置或光线变化。数据集包含了所记录的图像和每个图像的标签。这被称为监督学习。
最好使用与训练人工智能相同的传感器和环境来运行人工智能。这样能确保模型熟悉所传入的数据。例如,由于制造差异,温度传感器对于相同的温度具有不同的电压输出。就我们的目的而言,这意味着使用ESP-EYE摄像头在统一背景上录制图像是理想的。在部署期间,人工智能将在类似的背景下发挥最佳作用。还可以使用网络摄像头录制图像,但可能会牺牲一些准确性。由于MCU容量有限,我们将记录和处理96×96像素的灰度图像。
收集数据后,将数据分成训练集和测试集很重要。我们这样做是为了了解我们的模型如何识别以前从未见过的手势图像。该模型自然会对训练期间已看到的图像表现良好。

这里有一些示例图像。如果你现在不想收集数据,可以在这里下载我们现成的数据集。
识别数据中的模式不仅仅对人类来说很困难。为了让AI模型更容易做到这一点,通常依赖预处理算法。在我们的数据集中,我们使用ESP-EYE和网络摄像头记录图像。由于ESP-EYE可以捕获96×96分辨率的灰度图像,因此我们在这里不需要做太多进一步的处理。然而,我们需要将网络摄像头图像缩小并裁剪为96×96像素,并将它们从RGB格式转换为灰度格式。最后,我们要标准化所有图像。下图可以看到我们所处理的中间步骤。

设计模型非常棘手!详细的处理超出了本文的范围。我们将描述模型的基本组件以及如何设计我们的模型。在幕后,我们的AI依赖于神经网络。可以将神经网络视为神经元的集合,这有点像我们的大脑。这就是为什么在僵尸末日的情况下,AI也会被僵尸吃掉。
当网络中的所有神经元都相互连接时,这称为完全连接或密集。可以认为这是最基本的神经网络类型。由于我们希望我们的AI能够从图像中识别手势,因此我们使用了更高级更适合图像的卷积神经网络(CNN)。卷积降低了图像的维数,提取了重要的模式并保留了像素之间的局部关系。为了设计模型,我们使用了TensorFlow库,它提供了现成的神经网络组件,称为层,可以轻松创建神经网络!
创建模型意味着堆叠层。它们的正确组合对于开发鲁棒且高精度的模型至关重要。下图显示了我们正在使用的不同层。Conv2D代表一个卷积层。BatchNormalization层对上一层的输出应用了一种标准化形式。然后我们将数据送入激活层,这会引入非线性并过滤掉不重要的数据点。接下来,最大池化类似于卷积来减小图像的大小。这个层块重复几次,合适的数量由经验和实验所决定。之后,我们使用扁平化层将二维图像缩减为一维数组。最后,该数组与代表石头剪刀布类的三个神经元紧密相连。
def make_model_simple_cnn(INPUT_IMG_SHAPE, num_classes=3):
inputs = keras.Input(shape=INPUT_IMG_SHAPE)
x = inputs
x = layers.Rescaling(1.0 / 255)(x)
x = layers.Conv2D(16, 3, strides=3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.MaxPooling2D()(x)
x = layers.Conv2D(32, 3, strides=2, padding="same", activation="relu")(x)
x = layers.MaxPooling2D()(x)
x = layers.Conv2D(64, 3, padding="same", activation="relu")(x)
x = layers.MaxPooling2D()(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(units=num_classes, activation="softmax")(x)
return keras.Model(inputs, outputs)
一旦我们设计了一个模型,就可以训练它了。最初,AI模型将进行随机预测。预测是与标签相关的概率,在我们的例子中是石头、剪刀或布。我们的AI会告诉我们它认为一张图像是每个标签的可能性有多大。因为人工智能一开始就在猜测标签,所以它经常会把标签弄错。训练是在将预测标签与真实标签进行比较后进行的。预测误差会导致网络中神经元之间的更新。这种学习形式称为梯度下降。因为我们的模型是在TensorFlow中所构建的,所以训练就像一、二、三一样简单。下面,可以看到训练期间所产生的输出——准确性(训练集)和验证准确性(测试集)越高越好!
Epoch 1/6
480/480 [==============================] - 17s 34ms/step - loss: 0.4738 - accuracy: 0.6579 - val_loss: 0.3744 - val_accuracy: 0.8718
Epoch 2/6
216/480 [============>.................] - ETA: 7s - loss: 0.2753 - accuracy: 0.8436
在训练过程中,可能会出现多种问题。最常见的问题是过度拟合。随着模型一遍又一遍地接触相同的例子,它会开始记住训练数据,而不是学习潜在的模式。当然,我们从学校就记得理解胜于记忆!在某些时候,训练数据的准确性可能会继续上升,而测试集的准确性则不会。这是过度拟合的明显指标。
经过训练,我们得到了一个TensorFlow格式的AI模型。由于ESP-EYE无法解释这种格式,我们将模型更改为微处理器可读格式。我们从转换为TfLite模型开始。TfLite是一种更紧凑的TensorFlow格式,它使用量化来减小模型的大小。TfLite通常用于世界各地的边缘设备,例如智能手机或平板电脑。最后一步是将TfLite模型转换为C数组,因为MCU无法直接解释TfLite。
现在可以将我们的模型部署到微处理器上了。我们唯一需要做的就是将新的C数组放入预期的文件中。替换C数组的内容,不要忘记替换文件末尾的数组长度变量。我们提供了一个脚本来简化此过程。
让我们回顾一下MCU上所发生的事情。在设置过程中,将解释器配置为我们图像的形状。
// initialize interpreter
static tflite::MicroInterpreter static_interpreter(
model, resolver, tensor_arena, kTensorArenaSize, error_reporter);
interpreter = &static_interpreter;
model_input = interpreter->input(0);
model_output = interpreter->output(0);
// assert real input matches expect input
if ((model_input->dims->size != 4) || // tensor of shape (1, 96, 96, 1) has dim 4
(model_input->dims->data[0] != 1) || // 1 img per batch
(model_input->dims->data[1] != 96) || // 96 x pixels
(model_input->dims->data[2] != 96) || // 96 y pixels
(model_input->dims->data[3] != 1) || // 1 channel (grayscale)
(model_input->type != kTfLiteFloat32)) { // type of a single data point, here a pixel
error_reporter->Report("Bad input tensor parameters in model\n");
return;
}
设置完成后,将捕获的图像发送到模型,然后做出有关手势的预测。
// read image from camera into a 1-dimensional array
uint8_t img[dim1*dim2*dim3]
if (kTfLiteOk != GetImage(error_reporter, dim1, dim2, dim3, img)) {
TF_LITE_REPORT_ERROR(error_reporter, "Image capture failed.");
}
// write image to model
std::vector<uint8_t> img_vec(img, img + dim1*dim2*dim3);
std::vector<float_t> img_float(img_vec.begin(), img_vec.end());
std::copy(img_float.begin(), img_float.end(), model_input->data.f);
// apply inference
TfLiteStatus invoke_status = interpreter->Invoke();
}
然后模型会返回每个手势的概率。由于概率数组只是一系列介于0和1之间的值,因此需要进行一些解释。我们认为识别出的手势是概率最高的手势。现在我们通过将识别的手势与AI的动作进行比较来处理解释,并确定谁赢得了这一轮。你没有机会!
// probability for each class
float paper = model_output->data.f[0];
float rock = model_output->data.f[1];
float scissors = model_output->data.f[2];
下图说明了MCU上的步骤。出于我们的目的,不需要对MCU进行预处理。
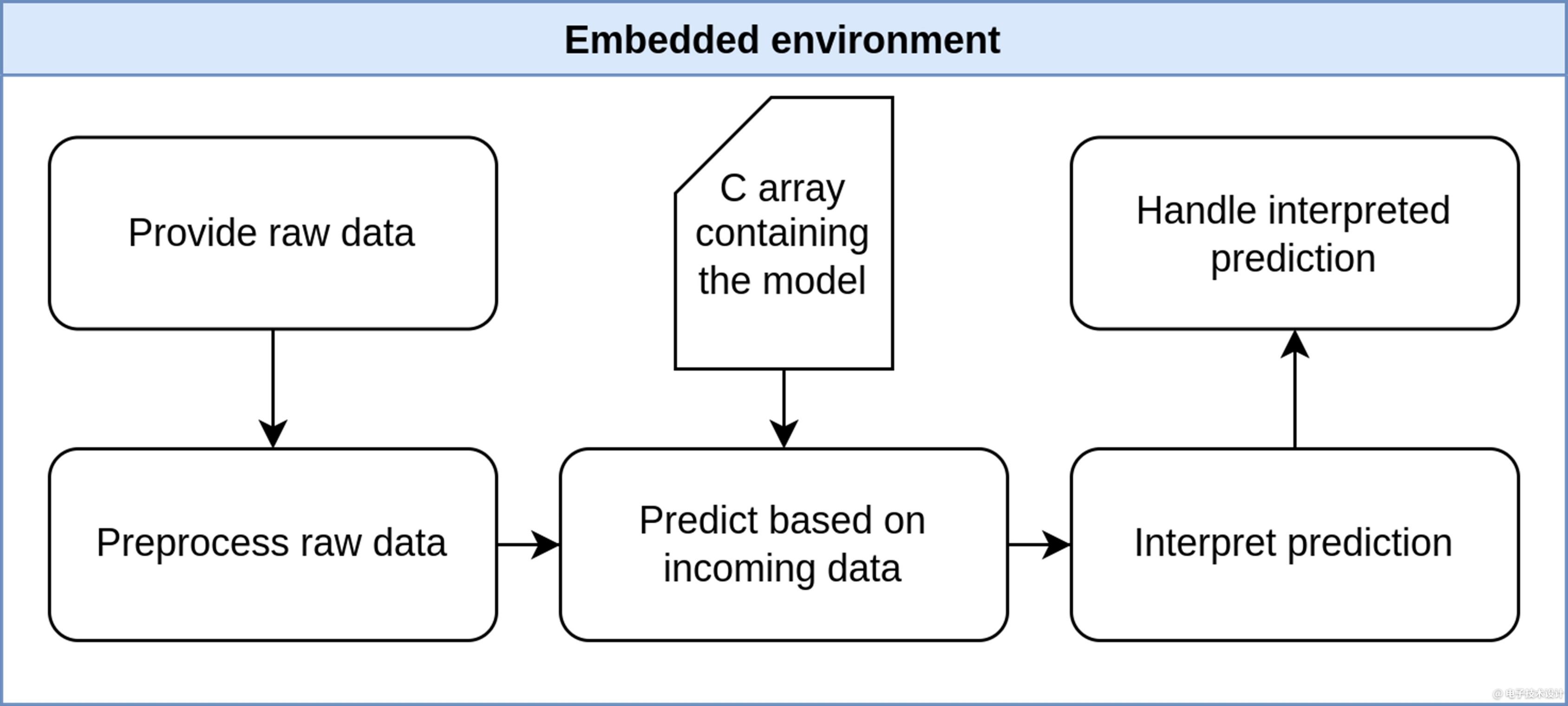
挑战一下怎么样?想要实现新的人生目标?或是给老朋友留下深刻印象或找到新朋友?通过添加蜥蜴和斯波克,可以让石头剪刀布更上一层楼。你的AI朋友将是一项更接近世界霸权的技能。首先你应该看看我们的石头剪刀布知识库,并能够复制上述步骤。README自述文件可帮助你了解详细信息。下图向你展示了游戏的运作方式。你需要添加两个额外的手势和一些新的输赢条件。

如果你喜欢这篇文章并想开始你自己的项目,我们会为你提供一个模板项目,它使用了与我们的剪刀石头布项目相同的简单流水线。你可以在此处找到该模板。不要犹豫,通过社交媒体向我们展示你的项目。我们很想知道你能创造什么!
你可以在和找到有关TinyML的更多信息。Pete Warden的书是一个很好的资源。

Nikolas Rieder是汉堡应用科学大学的学生。他在攻读机电一体化学士学位,并自2022年2月起在Itemis AG进行强制实习。他与TinyML领域的合著者一起工作,将他对AI的热情与他在嵌入式系统方面的专业知识相结合。Nikolas是一个终身学习者,他对改善日常生活的未来技术充满好奇。
(原文刊登于EDN姊妹网站Embedded,参考链接:How to quickly deploy TinyML on MCUs,由Franklin Zhao编译。)
本文为《电子技术设计》2023年1月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。
 最前沿的电子设计资讯
最前沿的电子设计资讯
