
在计算机中,整个内存可以根据访问时间和容量分为不同的级别。图1显示了内存层次结构中的不同级别。更小、更快的内存会更靠近处理器。如果处理器所需要的数据离处理器越近,访问时间就越少。因此,我们希望让处理器所需要的数据离它更近。但这是怎么实现的呢?
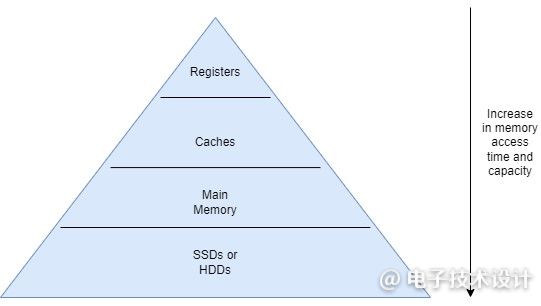
图1:内存层次结构。
根据局部性原则,当处理器访问一个字节的内存时,它更有可能再次访问该内存位置。此外,处理器更有可能很快访问附近的字节。在图2中,诸如比较“i”和“n”、递增“i”、将“a”加1等指令执行了多次。像“i”、“a”、“b”、“n”和“c”这样的变量被多次使用。这些指令和变量在工作集中。如果工作集可以保存在缓存中,程序将运行得更快。随着程序的执行,工作集发生了变化。
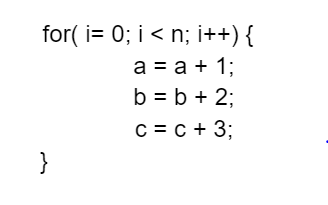
图2:简单的C语言for循环。
缓存是临时存储数据的高速存储器。它们的大小较小,从几KB到几MB不等。CPU缓存通常分为不同的级别(L1缓存、L2缓存和L3缓存)。离CPU越远,缓存越大,访问时间越长。因此,L2缓存可以存储比L1缓存更多的缓存行,而L3缓存可以存储比L2缓存更多的缓存行。当处理器启动并运行时,缓存控制器会接收请求以确定所请求的数据是否存在于缓存中。如果没有,可能会要求缓存控制器分配缓存行。那么,当数据从下游返回时,缓存控制器如何将其放入缓存中呢?
存在三种不同类型的缓存映射:直接映射、全相联映射和组相联映射。
在直接映射缓存中,一个内存块只能映射到缓存中的一个可能位置。例如,让我们考虑一个8KB缓存,缓存行大小为64字节。这意味着缓存有128个缓存行。在缓存的传入地址中,需要6位来寻址缓存行中的每个字节(2^6=64),它们被称为缓存偏移位(图3)。地址中接下来的7位用于将内存块映射到缓存行(2^7=128),它们被称为索引位。其余位存储在缓存中以标识内存块。这些位称为标记。
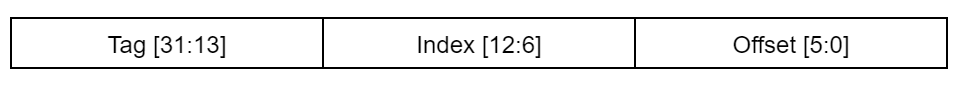
图3:直接映射缓存的缓存地址。
在全相联缓存中,内存块可以放置在任何缓存行中。如果上述示例中的同一个缓存是全相联的,那么就不需要任何位来索引任何缓存行。因此,除了6个缓存偏移位之外,其余的都是标记位(图4)。

图4:全相联缓存的缓存地址。
组相联缓存是直接映射缓存和全相联缓存的组合。在组相联缓存中,每个内存块都可以映射到一个组,这些组可能包含“n”个缓存行。例如,一个4路组相联缓存在每个组中有4个缓存行。在每个组中,缓存映射是全相联的。因此,组相联缓存需要一些位来索引地址以表示组。让我们将上述示例中的相同缓存视为4路组相联,这意味着将有32个组(128/4=32)。索引到一个组中需要5位(图5)。
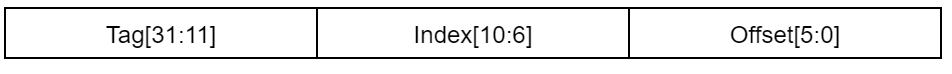
图5:组相联缓存的缓存地址。
现在,让我们看一下具有8次迭代的for循环(图6)。在每次迭代中,数组的一个元素(数据类型为“int”)都会递增。假设在第一次迭代中,将带有a[0]元素(4字节)的内存块(64字节)从主内存引入一级缓存(图7)。在接下来的连续迭代中,处理器所需要的所有数据(a[1]、a[2]、a[3]、…a[7])都将位于L1缓存中。这在很大程度上降低了内存访问时间。
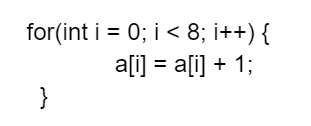
图6:C语言for循环。
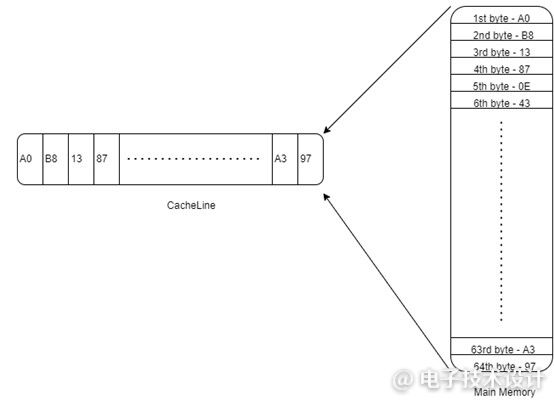
图7:主内存和缓存中的内存块表示。
现在让我们看一个不同的场景。

图8:C语言指令。
让我们考虑一个具有128个缓存行和64字节缓存行大小的直接映射缓存。为了执行第一条语句,需要将内存块从主内存中的地址0引入一级缓存的索引0。执行第二条语句需要将地址为32'h80的内存块引入缓存中。由于地址32'h80映射到索引0,因此需要驱逐现有的有效缓存行以引入新的内存块。这增加了更多的延迟。同样,下一条指令需要地址32'h100处的内存块,将会触发缓存行驱逐和内存块提取。当使用直接映射缓存时,此程序会导致性能不佳。
现在让我们看看具有128个缓存行和64字节缓存行大小的全相联缓存的行为方式。当执行这些指令中的每一个时,就会将新的内存块引入缓存,但不需要驱逐内存块,因为内存块可以放置在缓存中的任何位置,前提是缓存具有无效的缓存行。
4路组相联缓存每个组有4个缓存行。因此它最多可以为同一个索引分配4个内存块而不会驱逐。因此,上面的三个指令将导致在组0下分配三个内存块。
当连续的指令获取映射到一个索引或一个组的内存块时,直接映射缓存和组相联缓存会遇到更多冲突。将会发生驱逐和引入新的内存块。但这些类型的缓存也有优势。在直接映射缓存中,在缓存查找期间,缓存控制器只需要查找一个地方。这使得缓存查找速度更快。在缓存查找期间,全相联缓存需要将所有缓存行与传入地址进行比较,以确定它是否具有缓存行的有效副本。这需要许多比较器,这使得与直接映射缓存相比,全相联缓存更加昂贵。这也意味着全相联缓存会消耗功率来查找缓存。组相联缓存是全相联缓存和直接映射缓存之间的权衡。组相联缓存受到了广泛使用,因为它们受益于以下两个方面:关联性和将内存块映射到组的想法。

Krishnakanth是英特尔的图形硬件工程师。他毕业于圣何塞州立大学,获得了电气工程硕士学位。
(原文刊登于EDN姊妹网站Embedded,参考链接:Understanding cache placement,由Franklin Zhao编译。)
本文为《电子技术设计》2023年1月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。
 最前沿的电子设计资讯
最前沿的电子设计资讯
