
自1960年代以来,模拟计算在商业应用中的部署微乎其微,只有用于军事与利基工业的用例。虽然数字计算的发展已主导商业应用数十年,但模拟计算的一些新进展表明这一趋势正在转变。
随着边缘人工智能(AI)应用的计算要求呈指数级成长,数字系统正苦苦挣扎于跟上其脚步。很明显,传统的数字计算扩展方法,即转向更先进的半导体工艺节点,显然已经达到物理极限(即摩尔定律已经失效),而不断攀升的制造成本则限制了只有少数几家最富有的公司才能使用该技术。下一代的人工智能处理亟需采用新的方法。事实证明,与数字系统相比,模拟计算在成本与功耗方面具有10倍的更高优势,而且这一差距只会继续扩大。
在深入探讨人工智能时代模拟系统与数字系统相比的可行性之前,让我们看看人工智能硬件的两项关键因素:可扩展性与可访问性。人工智能算法的权重计数会有很大的不同:图像识别等计算机视觉任务的权重可能为5M至100M,而自然语言处理的权重则为500M至100B。
随着人工智能算法变得更加复杂,这些数字将持续增加,因此人工智能硬件具有可扩展性对于各种应用至关重要。当我们想到可扩展性时,人工智能硬件能够即时处理信息至关重要。毕竟延迟问题会限制用户体验,阻碍生产力,而且还可能为某些应用带来严重的安全风险(图1)。
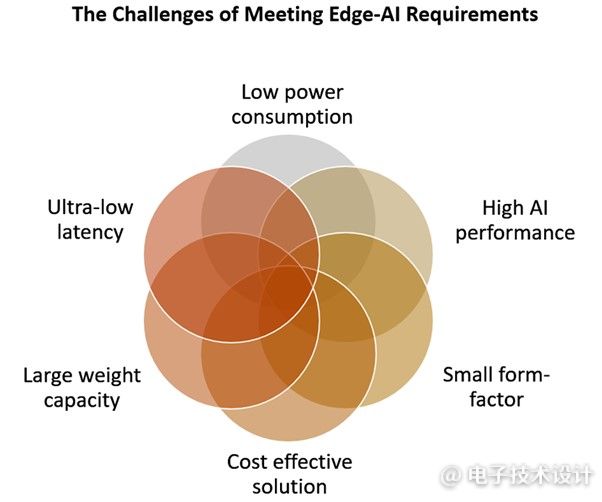
图1:满足边缘AI需求所面临的挑战。(图片来源:Mythic)
现代数字系统基于冯·诺依曼(Von Neumann)体系结构,这是一种最初于1945年所提出的计算概念。该体系结构指定了单独的数字计算逻辑单元和存储单元来访问和存储数据。这在数字系统中以CPU或GPU计算逻辑访问外部存储器(通常是DRAM)来实现。处理大型人工智能算法就暴露了冯·诺依曼架构的一个重大弱点,即边缘设备中进行实时 AI 处理时的逻辑处理,其访问权重存储在外部 DRAM 中。这个弱点造成三个系统层面的问题。首先,访问外存会增加延迟,而使存储器带宽成为系统性能的瓶颈。其次,访问外存会消耗大量电量。而且,随着系统性能要求的提高,功耗只会不断增加。第三,为了顺应更高性能的CPU与GPU,更快与更多的DRAM,以及有源冷却系统以散去功耗所产生的热能,物料清单(BOM)成本将会增加。
目前,一种展现巨大前景的特定方法是模拟存内计算(CIM),它将模拟计算与闪存等非易失性存储器(NVM)搭配使用(图2)。模拟CIM系统可以利用闪存优越的密度进行数据存储和计算。这意味着模拟CIM处理器可以在片上运行多个大型、复杂的深度神经网络(DNN),从而无需使用DRAM芯片。这种方法完全消除了与采用冯·诺依曼系统进行AI处理有关的数字逻辑和外存瓶颈、功耗以及BOM成本。
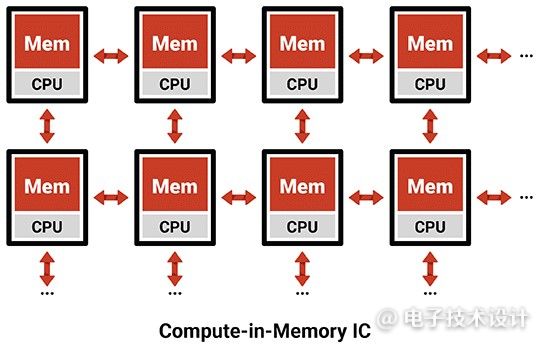
图2:存内计算IC。(图片来源:Mythic)
让我们仔细了解NVM的优势。NVM具有令人难以置信的密度和零功耗保持功能,这意味着存储在每个单元中的权重在没有电源的情况下仍可保持不变。模拟CIM方法能让NVM单元在NVM单元内存储并执行算术运算,其工作原理是以快速而省电的方式将整个存储体的小电流组合起来。通过使用NVM存储器本身,就可以立即完成计算。模拟CIM系统不需要使用能量来访问外存中的权重,因而能减少能量使用。
在模拟CIM系统中,闪存晶体管用作可变电阻,可根据存储在存储器中的模拟值按比例降低传输到输出端的信号强度。然后,这种效应会触发DNN的乘法阶段。在累加过程中,会通过汇总一整列存储单元的输出来对每个计算的输出进行求和。这种方法可以让模拟CIM系统一步处理整个输入向量,这就与数字处理器的被迫高速迭代有所不同。
在DRAM中保存大型权重阵列的典型数字边缘推理实现,每次乘法累加(MAC) 所耗用的能量可能达到10pJ,而模拟CIM方法则可使其降低至0.5pJ(图3)。当我们考虑到基于视觉的人工智能推理处理需要高达数万亿次MAC计算时,就能感受到节能迅速增加。为何数字系统会消耗如此多的能量呢?有两个原因。第一,乘法运算过程。数字系统需要采用大量并行逻辑门来实现高吞吐量,而且随着数据分辨率提高,逻辑门数量会继续显著增长。其次,随着分辨率与视频帧速率的增加,访问存储在外部DRAM中的权重需要大量能量。
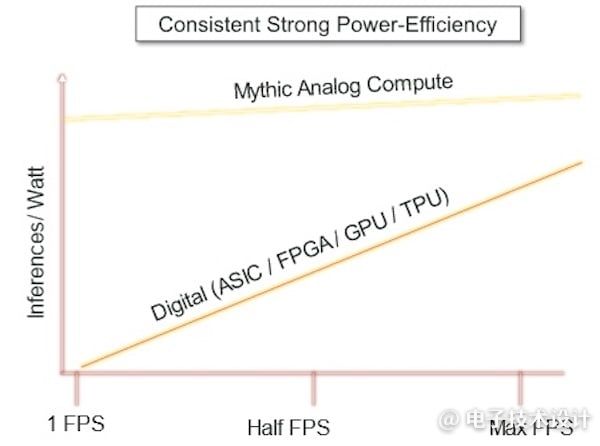
图3:模拟计算有望实现更高能效。(图片来源:Mythic)
此外,由于NVM闪存的高密度特性,可以使用单个闪存晶体管作为存储介质与计算器件,加上一个加法器(累加器)电路,就可以实现一个极为紧凑的系统。这也意味着我们可以节省外部DRAM及其相关元器件的成本。
模拟CIM系统也具有成本优势,因为它可以以成熟的半导体工艺节点制造。一个额外的好处是,前沿节点可用的供应链往往有限,而更成熟的工艺节点则可用性更加广泛,成本效益更高。
另一个好处是,模拟CIM系统提供了非常低的延迟。在NVM闪存单元内存储和处理意味着即时计算结果。数据在处理器中通过数字逻辑门和内存传播,以及访问外部DRAM时,都不会出现延迟问题。相反,大规模并行矩阵计算则是在片上实时执行的。
模拟CIM系统非常适合包括对象检测、分类、姿态估计、分割与深度估计在内的视频分析应用。这些系统的高帧率与采样率需要高水平的计算吞吐量。虽然数字系统能支持实时AI处理的基本要求,但这些系统体积庞大,而且非常耗电。虽然可以使用有源冷却方法,但这对许多通常非常紧凑的边缘设备来说并不可行。
许多数字系统所使用的另一种解决方案是将深度学习工作卸载到远程云服务器,因为这些数字系统无法满足边缘AI应用的能源与尺寸要求。问题是将推理推向云端往往是不切实际的。高带宽通信并非总是可用(想想无人机就知道了),因此,将推理移至云端将会导致显著的延迟,这就使这种方案对于实时应用并不可行。
模拟系统在适应不断变化的环境条件方面也取得了长足的进步。过去,环境噪声会稍微改变处理结果。数字过程中的模拟与数字抑制电路已经完成了重要的研究和开发,这将能补偿实际应用中的环境噪声。
尽管模拟CIM系统与数字系统相比大幅简化了MAC处理,但还需要额外的数字元素来执行经过全面训练的神经网络。例如,最好在数字逻辑中执行激活和池化等功能。
例如,Mythic公司通过单指令多数据(SIMD)加速器单元、协调运算的RISC-V处理器、用于路由数据流量的片上网络(NoC)以及用于保存数据的本地SRAM来补充其模拟CIM内核,使AI推理处理器能够独立执行完整的DNN模型。这种类型的系统具有很强的可扩展性,因为它将每个基于模拟CIM的内核、SIMD引擎与SRAM都视为处理器中的独立块。通过将一个处理器中的块或一个板上的多个处理器链接起来,该系统可以确保输入、输出和中间数据元素高效流动。

图4:Mythic的神经网络数字架构。其不同之处在于混合信号计算(超密集存储+矩阵乘法)。(图片来源:Mythic)
凭借模拟CIM系统令人难以置信的性能、功耗与成本优势,我们将看到模拟CIM被集成到各种边缘AI应用中,包括视频安防、工业机器视觉与自动化,以及自动机器人与无人机。
对于视频安防市场,边缘AI应用对于保护人们的安全和协助预防损失非常有用。例如,安防摄像头可以使用AI算法实时检测入店行窃事件,或者机场可以检测无人看管的可疑物品。带有模拟CIM的边缘AI应用不仅能即时处理信息,而且还能帮助保护人们的隐私。与需要将整个视频流发送到中央处理系统的传统系统不同,模拟CIM系统可以在边缘处理信息,因此只需要将安全事件的元数据发送到指挥中心。这有助于减轻监控的隐私问题,同时仍能保护公众安全。
在工业领域,可用于质量控制和安全的计算机视觉应用需求日益增加。模拟CIM系统可用于装配线上,以帮助实时识别缺陷和其他生产问题。在未来,我们还会越来越多地看到由AI驱动的机器人与人类一起工作,实现货物运输并执行重复而艰巨的任务。为了确保工人的安全,机器人必须在边缘实时处理信息——这是模拟CIM系统的完美用例。
最后,无人机是模拟CIM系统的另一个关键市场。尽管过去几年围绕无人机有大量的宣传,但主流计算方法无法满足无人机独特的性能与功耗要求。由于数字系统非常耗电,这限制了无人机的飞行时间。此外,数字系统很难运行复杂的AI网络。通过将模拟CIM解决方案与数字系统搭配使用,无人机可以处理多个大型、复杂的DNN,而且其功耗仅为传统系统的一小部分。
要想充分发挥AI行业的潜力,就需要比目前的数字方法有100~1000倍的改进。由于数字系统改进的步伐放缓,模拟CIM系统就提供了满足AI应用的功率、性能、成本与尺寸需求的唯一途径。未来,除了将 3D 内存技术与先进的芯片工艺集成之外,我们还将看到模拟技术的更多进步,包括在 NAND 闪存和 RRAM 中启用模拟计算。我们期待看到模拟计算在未来几年推动AI创新的新时代。
(原文刊登于EDN姊妹网站Embedded,参考链接:Rediscovering analog computing for achieving effective edge AI performance,由Franklin Zhao编译。)
本文为《电子技术设计》2023年2月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。
 最前沿的电子设计资讯
最前沿的电子设计资讯
