
据EDN电子技术设计报道,2月20日,复旦大学自然语言处理实验室邱锡鹏教授团队悄然发布了国内首个类ChatGPT模型MOSS(https://moss.fastnlp.top/),不仅一举刷出数个微博热搜话题,在知乎上更是直接冲上热榜,话题浏览进306万次。
据EDN报道,复旦NLP团队这个类ChatGPT模型,发布即面向公众进行内测,据悉,3月份将开放源代码。(更多详情:国内首个类ChatGPT模型MOSS内测,中国版ChatGPT还差什么?)
有知乎匿名网友称已经拿到了内测资格,并实时更新了一波测试结果:
1、帮我把今年的国自然写一下。杰青那种。

2. 在我的电脑桌面上有一个名为wxc的文件夹,文件夹内有400个名字不同的mat文件,每个mat文件中都有名字为x,y,z的数据组,请你用matlab代码实现将文件夹中的mat文件里的x,y,z,数据组合并成一个csv文件

for(i=1:length(mat文件中的名字)){name = mat文件中的名字[i];data = {name};fprintf('%s,',name);}end for
3. Write three poems about artificial intelligence, humans, religion, war, death, life, thought, freedom, rebellion, action, destruction

4. Moss,请帮我写一个k-mean算法

5. 鸡兔同笼问题 @胖蟹


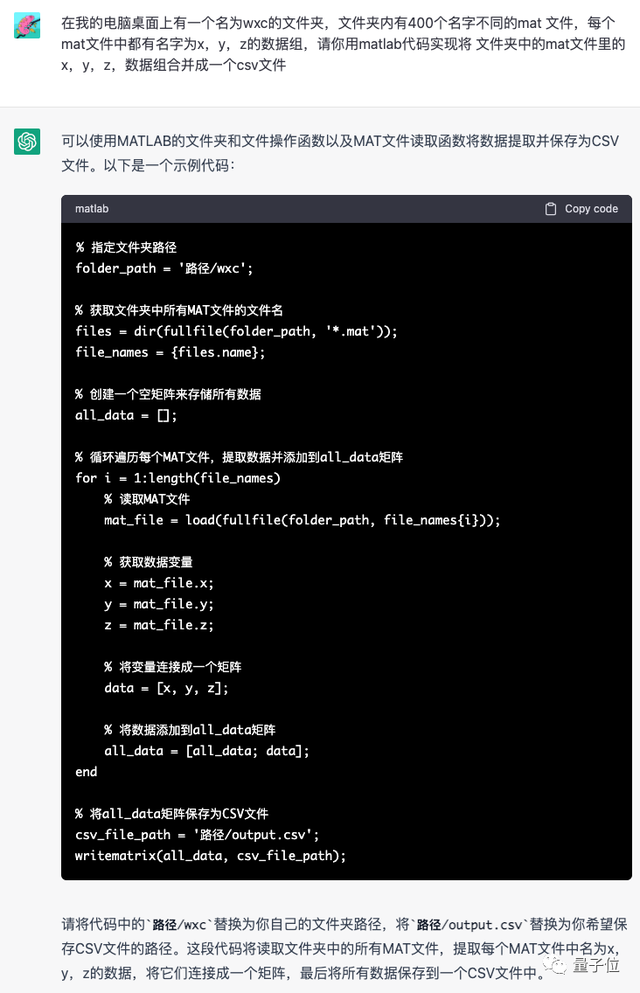


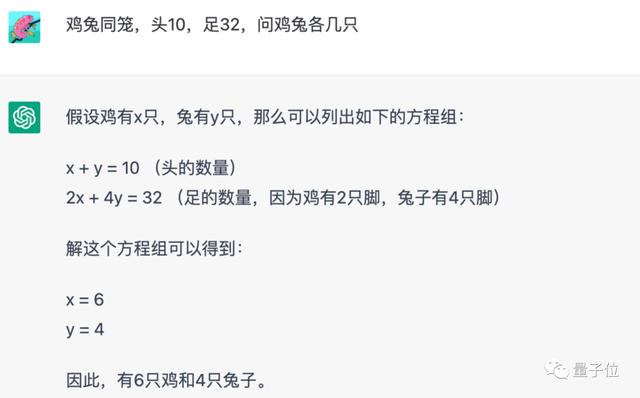
综合来看,MOSS的回答明显不及ChatGPT。
据研发团队表示,MOSS开发的基本步骤与ChatGPT一样,包括自然语言模型的基座训练、理解人类意图的对话能力训练两个阶段。在对话能力训练阶段,OpenAI收集了至少几十万条人类指令,让各行各业的专业标注员写出指令回复,再将它们输入模型基座,以帮助ChatGPT逐步理解各种指令。但不同的是技术路线,复旦团队通过让MOSS和人类以及其他对话模型都进行交互,显著提升了学习效率和研发效率,短时间内就高效完成了对话能力训练。
邱锡鹏坦言:“MOSS与ChatGPT的差距主要在自然语言模型基座预训练这个阶段。MOSS的参数量比ChatGPT小一个数量级,在任务完成度和知识储备量上,还有很大提升空间。”
此外,团队表示,在这些问题里面MOSS的最大短板是中文水平不够高。主要原因是互联网上中文网页干扰信息如广告很多,清洗难度很大。为此,复旦大学自然语言处理实验室正在加紧推进中文语料的清洗工作,并将清洗后的高质量中文语料用于下一阶段模型训练。科研团队相信,这将有效提升模型的中文对话能力。
 最前沿的电子设计资讯
最前沿的电子设计资讯
