
微软推出了 Kosmos-1,据称它是一种多模式大型语言模型 (MLLM),不仅可以对语言提示做出反应,还可以对视觉线索做出反应,可用于一系列任务,包括图像说明、视觉问题回答等等。
OpenAI的ChatGPT帮助普及了LLM的概念,如GPT(生成性预训练转化器)模型,以及将文本提示或输入转化为输出的可能性。
虽然人们对这些聊天功能印象深刻,但微软的 AI 研究人员在一篇名为“Language Is Not All You Need: Aligning Perception with Language Models”的论文中表明,LLM在处理多模态输入时仍有困难,例如图像和音频提示。这篇论文认为,要超越类似于 ChatGPT 的能力,需要将感知与语言模型结合起来,在现实世界中进行多模态感知,或在现实世界中获取知识"接地气",实现人工通用智能(AGI)。
论文说:"更重要的是,解锁多模态输入极大地拓宽了语言模型在更多高价值领域的应用,如多模态机器学习、文档智能和机器人技术"。
微软表示,其Kosmos-1 MLLM可以感知一般模式,遵循指令(零样本学习),并在上下文中学习(少样本学习)。"论文说:"我们的目标是使感知与LLM保持一致,这样模型就能看到并说话。
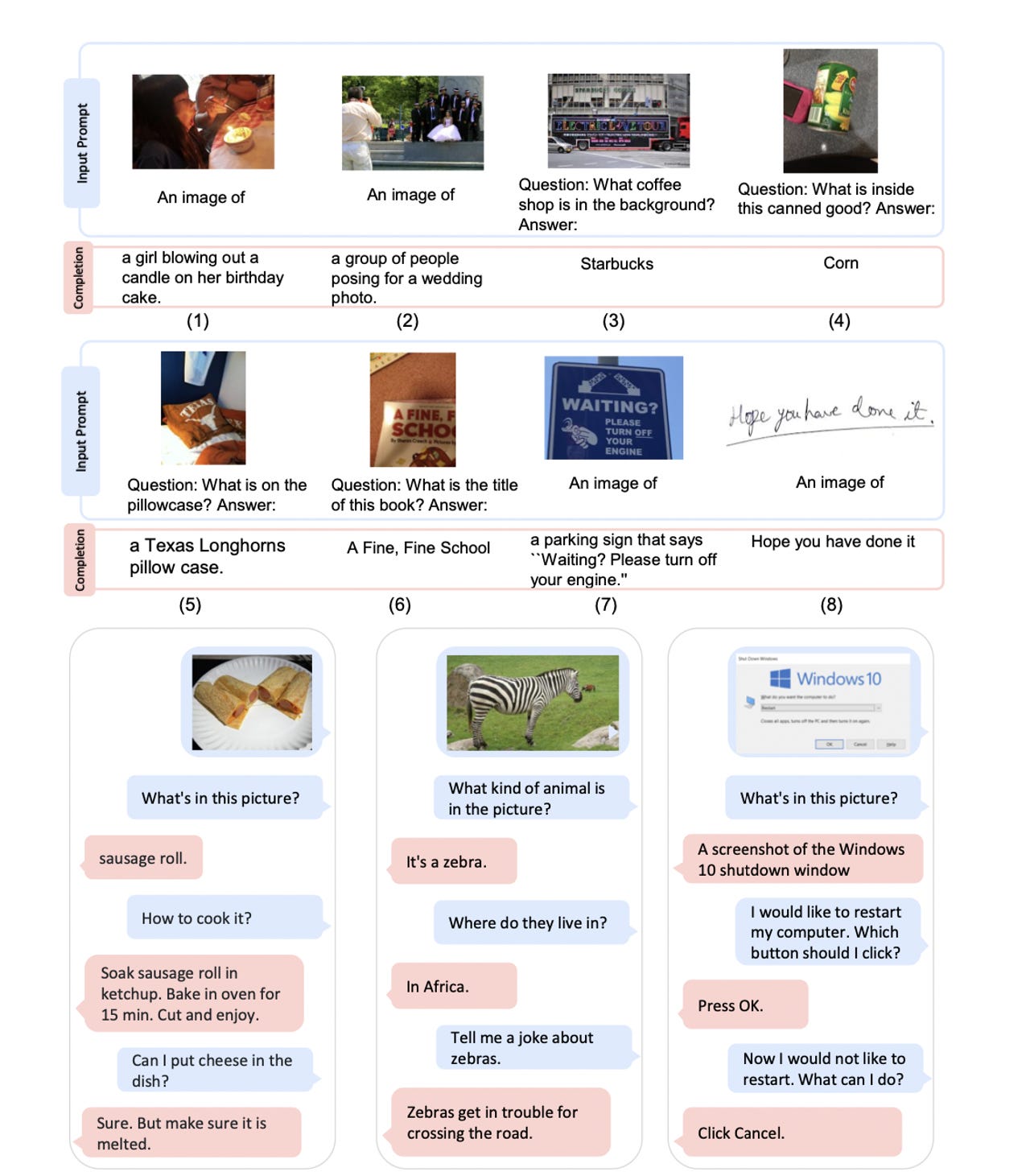
在输出演示中,Kosmos-1面对一张小猫的图像、一个人拿着一张纸、嘴角挂着微笑。提示是:“解释为什么这张照片很有趣?” Kosmos-1 的回答是: "猫咪戴着面具,让猫咪露出了笑容"。
其他例子显示它:从一张图片中感知到网球运动员有一个马尾巴;从一张10:10的钟面图片中读出时间;从一张4+5的图片中计算出总和;根据GitHub的描述页面回答 "什么是TorchScale?"(这是一个PyTorch机器学习库);以及从一个Apple Watch的表面读取心率。
每个例子都展示了像Kosmos-1这样的MLLM在多种情况下自动执行任务的潜力,从告诉Windows 10用户如何重新启动他们的电脑(或任何其他有视觉提示的任务),到阅读网页以启动网络搜索,解释来自设备的健康数据,为图像加上字幕,等等。然而,该模型不包括视频分析功能。
研究人员还测试了 Kosmos-1 在零样本 Raven IQ 测试中的表现。结果发现“当前模型与成年人的平均水平之间存在巨大的性能差距”,但也发现其准确性显示了 MLLM 通过将感知与语言模型对齐来“在非语言环境中感知抽象概念模式”的潜力。
鉴于微软计划使用基于 Transformer 的语言模型使 Bing 成为谷歌搜索的更好竞争对手,对“网页问答”的研究很有趣。
“网页问答的目的是从网页中找到问题的答案。它需要模型理解文本的语义和结构。网页的结构(如表格、列表和HTML布局)起着关键作用在信息的排列和显示方式中的作用。这项任务可以帮助我们评估我们的模型理解网页语义和结构的能力,”研究人员解释道。
图片:微软
 最前沿的电子设计资讯
最前沿的电子设计资讯
