
近日,一项研究声称能够用Stable Diffusion将大脑活动重建为高分辨率、高精确度的图像,在网上掀起轩然大波。
这项研究声称,使用fMRI(功能磁共振成像技术,相比sMRI更关注功能性信息,如脑皮层激活情况等)扫描大脑特定部位获取信号,AI就能重建出我们看到的图像。相关论文已经被CVPR 2023(IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议)接收。

这项研究来自日本大阪大学,研究希望能从人类大脑活动中,重建高保真的真实感图像,来理解大脑、并解读计算机视觉模型和人类视觉系统之间的联系。

可视化去噪过程
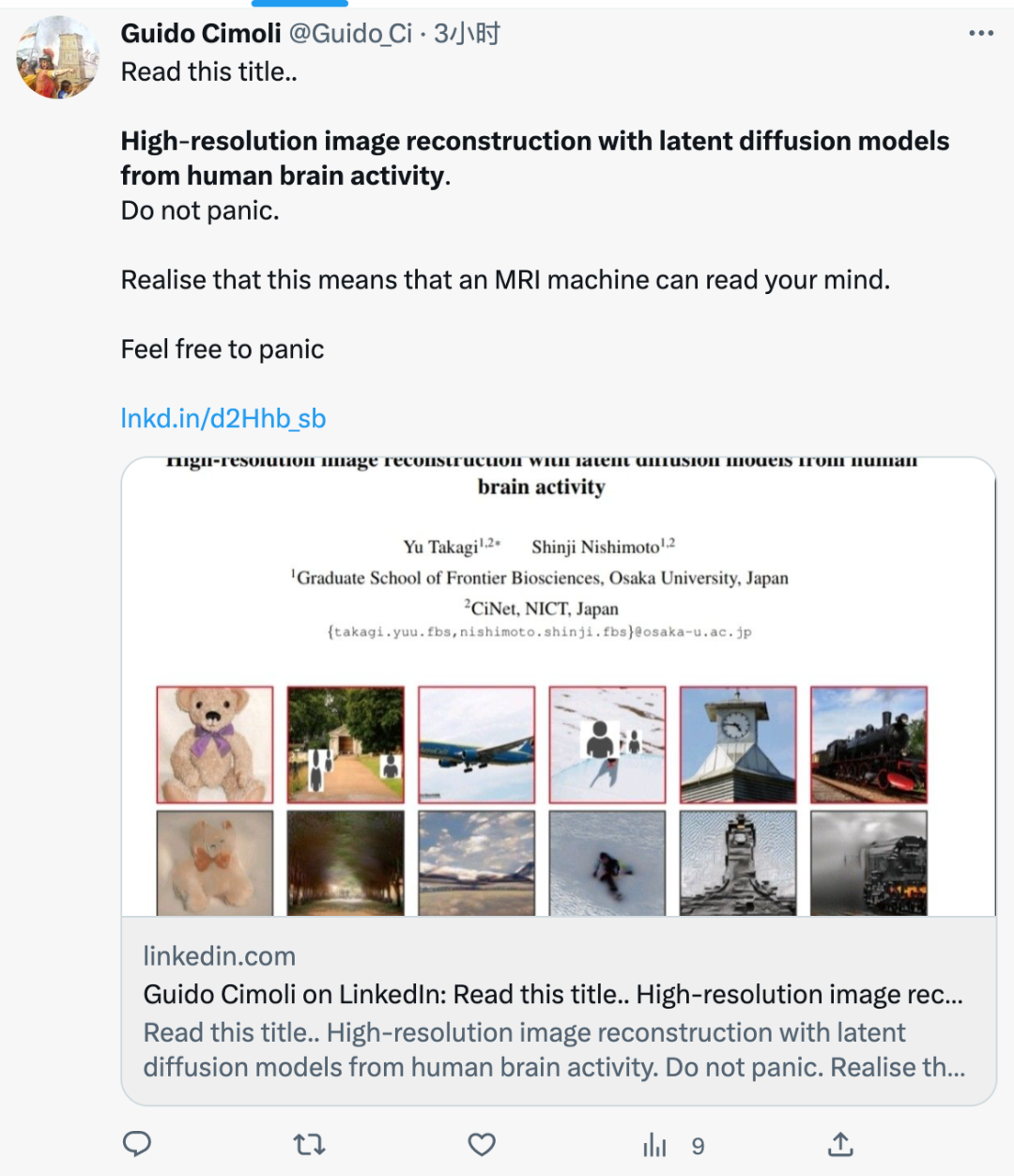
研究人员选用潜在扩散模型(LDM)Stable Diffusion进行重建信号。整体研究的思路是,基于Stable Diffusion打造一种以人脑活动信号为条件的去噪过程的可视化技术。它不需要在复杂的深度学习模型上进行训练或做精细的微调,只需要做好fMRI成像到Stable Diffusion中潜在表征的简单线性映射关系。整个框架仅由1个图像编码器、1个图像解码器,外加1个语义解码器组成,概览框架如下:
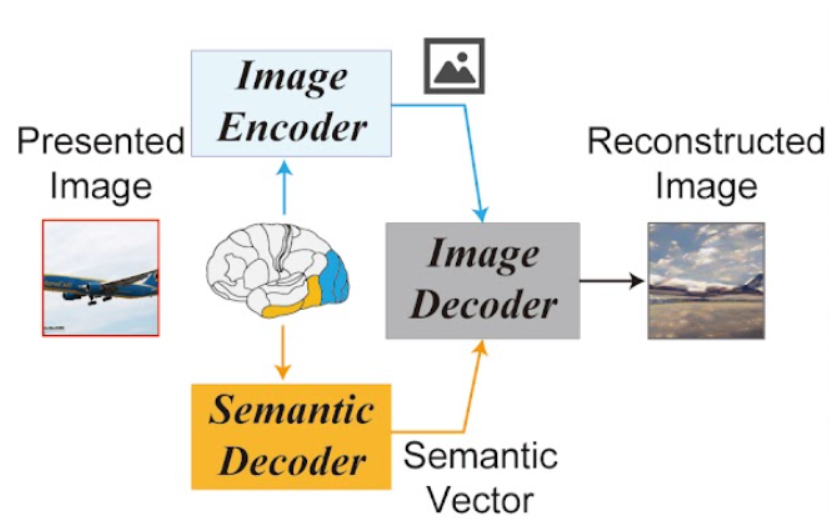
具体来说,研究人员将大脑区域映射为图像和文本编码器的输入。下部脑区被映射到图像编码器,上部脑区被映射到文本编码器。如此一来可以这让该系统能够使用图像组成和语义内容进行重建。研究者分别从早期和高级视觉皮层的fMRI信号中解码出重建图像z以及相关文本c的潜在表征,将其作为输入,由自动编码器生成复现出的图像Xzc。
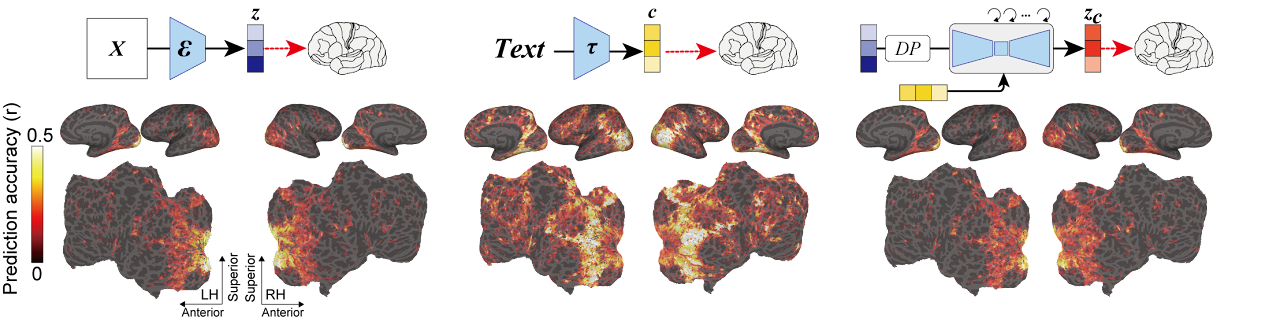
可以看到,如图1所示采用了Zc的编码模型在大脑后部视觉皮层产生的预测精确度是最高的。(Zc是与c进行交叉注意的反向扩散后,z再添加噪声的潜在表征)相比其它两者,它生成的图像既具有高语义保真度,分辨率也很高。

图1:使用z、c和Zc重建的图像。
 最前沿的电子设计资讯
最前沿的电子设计资讯
