
3月7日,在接连推出AI聊天机器人Bard、发布通用语音模型(USM)API与研究成果之后,谷歌和柏林工业大学的团队重磅推出了史上最大的视觉语言模型——PaLM-E,参数量高达5620亿(GPT-3的参数量为1750亿)。
在市场形势利好的背景下,全球机器人的基础技术和前沿技术也在不断进步。小型机器人看重MCU的成本与功耗,通用型机器人看重MCU精准的电机控制,高端机器人更需要MCU兼顾算力与拓展性,MCU作为机器人核心主控芯片中的第一大类别,必将受惠于机器人市场的快速增长。
3月30日,AspenCore将在上海举办国际集成电路展览会暨研讨会(IIC Shanghai 2023),同期举办的“MCU技术与应用论坛”邀请到国内外多家优秀MCU设计和系统方案商,欢迎感兴趣的朋友到场交流,大家可以点击这里报名参会。

PaLM-E的应用示意。
PaLM-E是PaLM-540B语言模型与ViT-22B视觉Transformer模型的结合体,也是迄今为止已知的最大VLM(视觉语言模型)。它主要基于谷歌现有的PaLM大语言模型,并添加了感官信息和机器人控制。PaLM-E会将图像信息、传感器数据等编码为一系列与语言标记大小相同的向量,从而以与处理语言相同的方式“理解”感官信息。换言之,PaLM-E证明了,在视觉、文本等多模态输入下,大型语言模型也可作出具体决策,并执行复杂任务。
作为一种多模态具身VLM,它不仅可以理解图像,还能理解、生成语言,执行各种复杂的机器人指令而无需重新训练。它还展示出了强大的涌现能力(模型有不可预测的表现),如具备多模态思维链推理(允许模型分析包括语言和视觉信息的一系列输入)、只接受单图像提示训练的多图像推理(使用多个图像作为输入来做出推理或预测)等。
据谷歌介绍,当得到一个高级命令,如“把抽屉里的薯片拿给我”,PaLM-E可以为带有手臂的移动机器人平台生成一个行动计划,并自行执行这些行动。而这一过程无需对场景进行预处理,PaLM-E可以通过分析来自机器人相机的数据来实现这一点。这消除了人类预处理或注释数据的需要,并可实现更为自主的机器人控制。
而更重要的一点是它的行动计划还具有弹性,可以对环境做出反应。例如,在谷歌的演示视频中,研究人员从机器人手中抓取薯片并移动它们,但机器人找到薯片并再次抓取它们。PaLM-E模型不但可以引导机器人从厨房取薯片袋,而且通过将PaLM-E集成到控制回路中,它可以抵抗任务期间可能发生的中断。

机器人抓取薯片过程
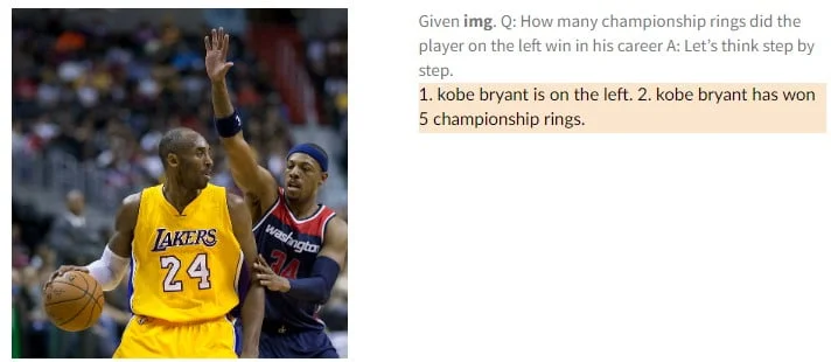
除此之外,PaLM-E也是一种“有效的视觉语言模型”,不但可以识别分析图象,还可以针对带有手写数字的图像,执行数学运算。例如,它可以识别图中的篮球明星科比·布莱恩特,并可以生成关于他的文本信息,比如他赢得了多少次冠军。或者根据手写的餐馆菜单图片,PaLM-E可直接算出2份披萨的价钱。

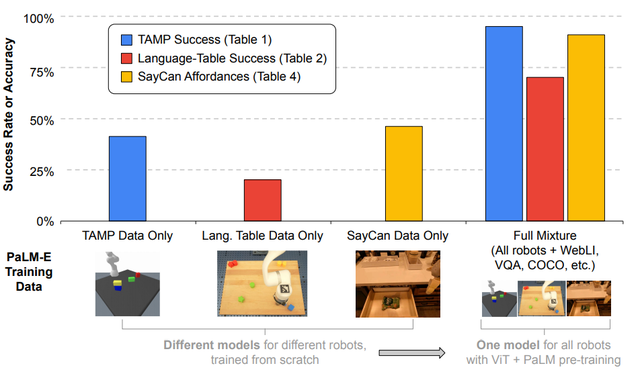
更加令人振奋的是,得益于PaLM-E的大型语言模型核心,PaLM-E表现出了“正迁移”能力,即可以将一项任务中学到的知识和技能迁移到另一项任务中,从而与单任务机器人模型相比具有“显着更高的性能”。
还有一点非常值得关注,灾难性遗忘常常是预学习模型必须面对的一大挑战,即当一个训练好的模型被进一步训练时,现有任务性能便将显著下降。在本次研究中研究人员观察到:“语言模型越大,在视觉语言和机器人任务训练时就越能保持其语言能力——从数量上讲,562B PaLM-E模型几乎保留了其所有的语言能力。”同时,他们也证明了冻结语言模型是通向完全保留其语言能力的通用具身多模态模型的可行之路。
谷歌研究人员计划在未来将探索PaLM-E在现实世界中有更多应用,例如家庭自动化或工业机器人,也希望PaLM-E能够激发更多关于多模态AI的应用。
在市场形势利好的背景下,全球机器人的基础技术和前沿技术也在不断进步。小型机器人看重MCU的成本与功耗,通用型机器人看重MCU精准的电机控制,高端机器人更需要MCU兼顾算力与拓展性,MCU作为机器人核心主控芯片中的第一大类别,必将受惠于机器人市场的快速增长。
3月30日,AspenCore将在上海举办国际集成电路展览会暨研讨会(IIC Shanghai 2023),同期举办的“MCU技术与应用论坛”邀请到国内外多家优秀MCU设计和系统方案商,欢迎感兴趣的朋友到场交流,大家可以点击这里或扫码报名参会。

 最前沿的电子设计资讯
最前沿的电子设计资讯
