

那么,忆芯科技增长的第二曲线是什么?接下来,忆芯首席AI科学家孙唐博士为我们介绍了STAR2000D可计算存储方案。
为什么我们需要做更高效的信息交互呢?“在芯片上进行的交互就像走亲访友、去邻居家串门,它的距离只有100米;从主机芯片到固态硬盘,其实就相当于从合肥的天鹅湖到南京的长江大桥,距离会达到200公里;而如果在传统的主机和硬盘之间进行交互,其实它是一场跨国旅游,相当于从澳大利亚一路要前进到俄罗斯的古堡,整体的性能消耗会达到传统芯片消耗的8万倍以上。”孙唐打比方说。
那么,忆芯科技在STAR2000D上做了什么?首先忆芯通过STAR2000这颗芯片,首次实现了计算和存储两个功能领域在一颗芯片上的融合。这颗芯片的片上加载了28颗CPU,其中有8核的高性能A55,同时通过领域化的定制设计,在芯片上加载了AI NPU,加载了索引检索,加载了矩阵计算、统计计算等一系列硬件加速模块,实现了更高效的消息直通。这样做的好处是:1.整体计算效率相比主机,它的能耗降低了15-30倍;2.刚才我们的同事程雪也介绍过,它的整体交互效率高至接近主机端的4倍以上,这就是STAR2000D可计算存储带来的基础的能力提升。
下面来看一个“以图搜图”的场景。“在四五百万人的数据底库的存储容量上,我们只需要花不到1秒钟的时间就可以找到和搜索目标最相似的人员。实际应用中,不仅需要人工智能的分析,也包含了大量的业务处理的数据存储和加载。我们把数据读出以后,还要进行检索和比对,而在不同的应用中,我们需要用到不同的数据库,而不同的数据库的搜索和比对的形式是完全不同的。”孙唐举例说。
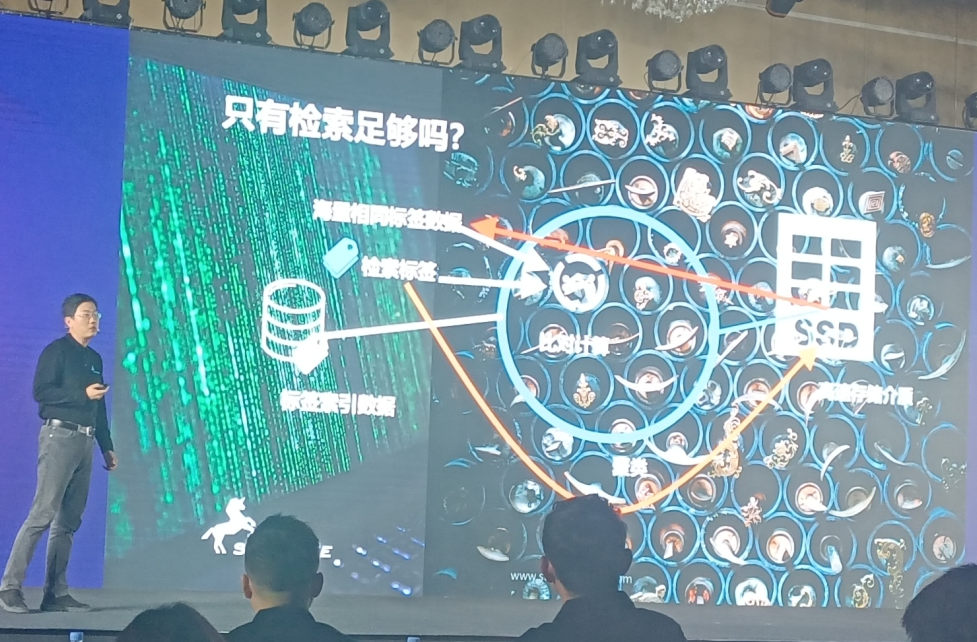
对于这样的场景,忆芯是如何来加速对应的AI处理的呢?“可以看到AI为我们的千业百态提供了添加标签的能力,而这些标签在右边的图上代表了不同的数据,找到标签之后,通过聚类,存储到不同的存储空间领域。这时候如果有人想要检索一个目标,他只需要读取特定领域的存储数据,就可以完成一次检索。但这就足够了吗?其实不够。在海量的大数据前提下,整体上的聚类数据虽然存储在介质中,它在同一个区域,但是通过索引检索的时候,返回的是海量的相同标签的数据。忆芯科技也是首创式地在芯片上引入了比对计算加速,可以在芯片中直接找到最符合的目标,再把这个数据交给用户,极大地降低了整体传输的带宽和计算所需要的性能开销。”孙唐表示。
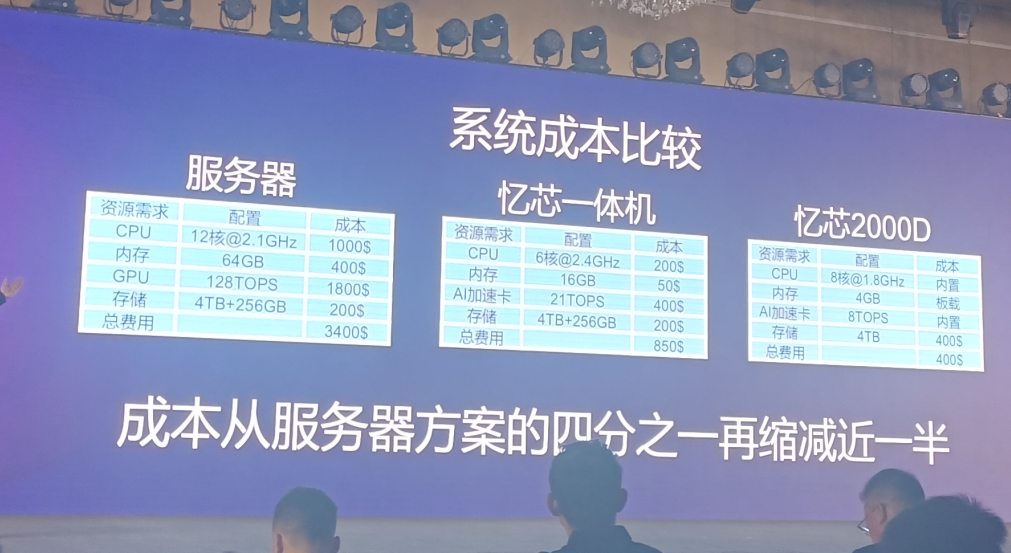
下面是整体系统成本比较。“传统的百万级别的以图搜图的应用中,它需要用到一台将近三四千美金的服务器,需要用到12核CPU以及高达128T算力的GPU,而在现场发布会所展示的忆芯的存算融合一体机上,我们仅仅需要它1/4的成本,就可以做到同等性能的业务实施。而通过STAR2000D内置的CPU,板载的内存,片上的8T 算力NPU以及本身很高性能的SSD存储应用,我们可以把成本从服务器方案的1/4再缩小一半。这对业内来说会是一个颠覆性的创新,会对整个业态产生更具想象力的市场影响。”孙唐强调。
“我们不仅做了单板的存储方案,通过STAR2000D底层基础设施,再加上标准AI应用框架,我们可以同时支持在异构平台、主机平台、嵌入式平台进行相应的分布式部署,而且整体的业务可以把数据中心的架构直接向边缘做迁移,实现多用户、多服务、可配置的业务框架,同时能实现AI业务降费增效、数据库业务增效及网络业务增效。通过可计算存储部署,它的高安全性、高性价比也能让扩展更灵活,部署更简单,运维也会更方便。”
下面再来看数据中心CDN场景。“大家都喜欢网络电影或者流媒体,原数据可以用低清、低分辨率的视频进行STAR2000D存储,通过人工智能来进行数据的分门别类。当用户想要观看某部影片的时候,同时STAR2000D本地实时计算,直接进行超分辨率提升,把原来的普通视频变成高清视频,再分发给不同的业务用户。同时它可以和GPU阵列兼容,实现更大体系上的降本增效,实现更低成本的超分辨率视频CDN业务。可以这么说,我们通过简简单单的一台普通主机,加上STAR2000D的可计算存储方案,就构成了一个可替换现有的一些专用应用存储或者业务应用服务器的标准应用,我们也希望能够让STAR2000D进入到更多行业,为行业赋能。”
 最前沿的电子设计资讯
最前沿的电子设计资讯

