
但其目的不是多GPU游戏,不会成为最好的游戏显卡,而是针对不断增长的AI市场。
从Nvidia发布的信息和图片来看,H100 NVL(H100 NVLink)将在顶部采用三个NVLink连接器,相邻的两块卡可插入单独的PCIe插槽。

这是一个有趣的变化,显然是为了适应不支持Nvidia的SXM服务器,重点是推理性能而不是训练。NVLink连接应该有助于提供NVSwitch在SXM解决方案上提供的缺失带宽。
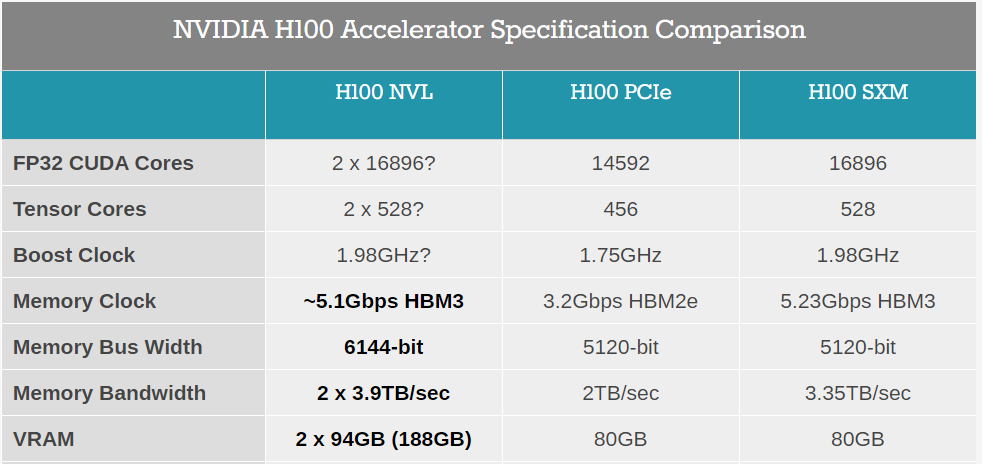
以规格为例。以前的H100解决方案(包括SXM和PCIe),都配备了80GB的HBM3内存,但实际包装包含六个堆栈,每个堆栈有16GB的内存。目前还不清楚是否有一个堆栈被完全禁用,或者是用于ECC或其他目的。我们所知道的是,H100 NVL每个GPU将有94GB,总共有188GB HBM3。我们认为每个GPU "缺少 "的2GB是为了ECC。
 功率比H100 PCIe略高,每个GPU为350-400瓦(可配置),增加50瓦。
功率比H100 PCIe略高,每个GPU为350-400瓦(可配置),增加50瓦。
同时,总性能实际上是H100 SXM的两倍:134 teraflops的FP64,1,979 teraflops的TF32,和7,916 teraflops FP8(以及7,916 teraops INT8)。基本上,这看起来与H100 PCIe的核心设计相同,它也支持NVLink,但现在可能启用了更多的GPU核心,而且内存增加了17.5%。内存带宽也比H100 PCIe高一些,每个GPU为3.9TB/s,合计7.8TB/s(而H100 PCIe为2TB/s,H100 SXM为3.35TB/s)。由于这是一个双卡解决方案,每张卡占用2个插槽的空间,Nvidia只支持合作伙伴和认证系统的2至4对H100 NVL卡。
总而言之,英伟达宣称H100 NVL的GPT3-175B推理吞吐量是上一代HGX A100的12倍(8个H100 NVL对8个A100)。对于希望尽快为LLM工作负载部署和扩展系统的客户来说,这无疑是很有吸引力的。

如前所述,H100 NVL在架构特征方面没有带来任何新的东西——这里的大部分性能提升来自Hopper架构的新变压器引擎,但H100 NVL将作为最快的PCIe H100选项和具有最大GPU内存池的选项,为一个特定的利基市场服务。
据NVIDIA称,H100 NVL卡将在今年下半年开始出货。
 最前沿的电子设计资讯
最前沿的电子设计资讯
