

现在,我们已经开始适应5G,网络运营商已计划采用5G-Advanced的3GPP标准第18版。这一新版本支持众多功能,如扩展现实、厘米级定位精度和微秒级室外和室内定时精度,将引发RAN基础设施中计算需求爆炸式增长。考虑为消费者和企业提供固定无线接入。通过大规模MIMO RRU应用波束成形技术,必须管理繁重又不断变化的流量,而UE则必须支持运营商聚合。两者都需要更大通道容量。解决方案则必须更环保,保证高性能和低延迟,更有效地管理可变负载,更经济高效地支持大规模部署。基础设施设备制造商希望将基于DSP的ASIC硬件的所有功耗、性能和单位成本优势,以及所有这些硬件的附加功能集成到一个更加高效的封装中。

(资料来源:CEVA)
虚拟化RAN(vRAN)组件能够在一个计算平台上同时运行多个链路,践行更高效承诺。这些系统旨在实现长达十年的C-RAN目标,即保障规模经济性,使供应商更具灵活性,以及通过软件集中管理多链路和拥堵流量。我们知道如何在大型通用CPU上虚拟化作业,因此满足这种需求的解决方案似乎是不言自明的。这些平台也有缺点,即在无线技术核心进行信号处理时,价格高昂、能耗过高且效率低下。
嵌入式DSP搭配大矢量处理器,专为满足信号处理任务(如波束成形)的速度和低功耗而设计,但过去不支持在多个任务之间进行动态工作负载共享。扩大容量需要添加更多内核,有时需要添加较大的内核集群,或者最好通过预设的内核分区以静态形式共享。
动态矢量线程
(资料来源:CEVA)
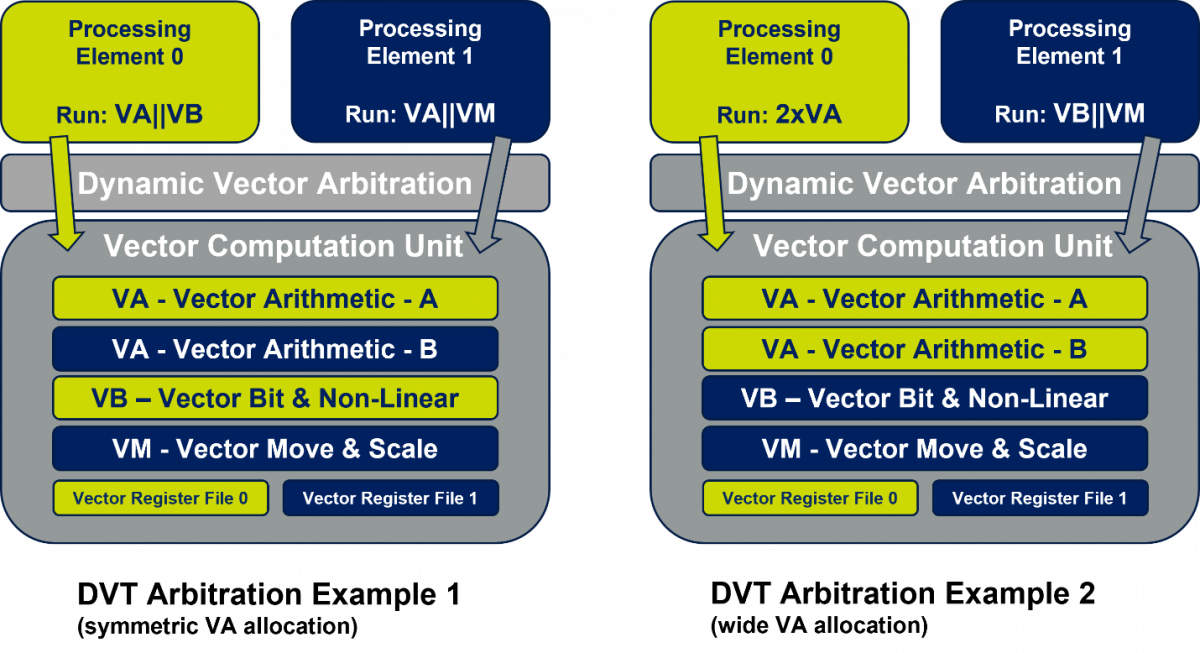
矢量处理一直处于瓶颈,因为矢量计算单元(VCU)占用矢量DSP中的大部分区域。尽可能高效地使用该资源对于实现虚拟化RAN容量最大化至关重要。将内核数量加倍以处理两个通道的默认方法要求每个通道使用单独VCU。但在任何情况下,一个通道中的软件都可能需要矢量算术运算的支持,而另一个通道可能正在运行标量操作;在这两个周期中,其中一个VCU处于空闲状态。换个思路,假设一个VCU同时为两个通道提供服务,并使用两种矢量算术运算和矢量寄存器文件。仲裁器可根据通道需求动态决定如何以最佳方式使用这些资源。如果两个通道在同一周期中都需要矢量算法,则这些通道将被定向至相应的矢量ALU和矢量寄存器文件。如果只有一个通道需要矢量支持,则可以跨两个矢量单位进行条带化计算,加速计算过程。这种在两个独立任务之间管理矢量操作的方法与执行线程非常相似,最大程度地利用固定计算资源同时处理一个或多个任务。
此技术便是动态矢量线程(DVT),会将每个周期的矢量操作分配给一个或两个高速算术单元(在此示例中)。您可以试想,将这一概念扩展到更多线程中,甚至可以进一步优化可变通道负载中的VCU利用率,因为独立线程中的矢量操作通常不同步。
支持DVT需要对传统矢量处理进行多个扩展。操作必须由广泛的矢量算术单元执行,才能允许每个周期进行128次或更多MAC操作。VCU还必须为每个线程提供矢量寄存器文件,才能单独存储各线程的矢量寄存器内容。矢量仲裁单元通过线程之间的竞争有效地安排矢量操作。
此功能如何支持虚拟化RAN?在绝对峰值负载下,此类平台上的信号处理要求将会继续得到如期的满足,因为它们位于双核DSP上(每个都具有单独的VCU)。当一个信道需要矢量算术运算,而另一个信道在标量处理中处于静止状态或被占用时,第一个信道通过使用全向量容量可以更快地完成矢量循环。与两个DSP内核相比,这样占用的空间更小,提供的平均吞吐量更高。
另一个关于DVT如何在基带处理中支持更高效率的示例可在5G-Advanced RRU中了解。这些设备必须支持大规模MIMO处理以促进波束成形。大型MIMO RRU预计将支持多达128个有源天线单元,包括对多用户和运营商提供支持。这意味着无线电设备具有大量计算要求,并在使用DVT时效率更高。在支持固定无线接入的UE、终端和CPE中,运营商聚合还可受益于DVT。DVT对蜂窝网络、基础设施和UE终端都大有裨益。
尽管人们倾向将大型通用处理器视为满足这些虚拟化需求的正解,但在信号处理路径中,这样的做法代表着倒退。我们不能忘记,基础设施设备制造商有充分的理由改用带有嵌入式DSP的ASIC。处理器价格昂贵、耗电且无法正确处理信号。富有竞争力的固定无线接入解决方案需要继续利用基于ASIC的DSP的优势,同时还需要利用对动态矢量线程的支持。
如果您想了解更多信息,请在CEVA联系我们。多年来,我们一直与基础设施硬件领域的众多知名公司合作,其中许多公司是我们无线产品的活跃客户。他们引导我们实现这一愿景,并帮助我们检验我们的XC-20系列架构和预发布产品。
(原文标题:Dynamic Vector Threading for High Efficiency in Fixed Wireless Access, vRAN & Massive MIMO Beamforming)
 最前沿的电子设计资讯
最前沿的电子设计资讯
