
据EDN电子技术设计报道,在最新一轮的 MLPerf 测试中,运行于DGX H100系统中的NVIDIA H100 Tensor Core GPU在每个人工智能推论测试中均实现了最高性能。
MLCommons每6个月发布新一轮人工智能推理处理基准测试。英伟达及其合作伙伴在MLPerf 3.0中运行并提交了基准测试,包括图像分类、对象检测、推荐、语音识别、NLP(自然语言处理)和3D分割。
这一轮MLPerf的新测试成员分别是致力于边缘图像分类和数据中心的美国机器学习初创公司SiMa.ai和美国AI解决方案提供创企Neuchips。

英伟达H100 Tensor Core GPU在每次AI推理测试中都展现出最高性能。得益于软件优化,该GPU的性能比去年9月份首次亮相时提高了54%。英伟达拥有比硬件工程师更多的软件工程师是有原因的。
在医疗保健领域,H100 GPU自9月以来在医疗成像的MLPerf基准3D-UNet (医学图像分割)上实现了31% 的效能增长。
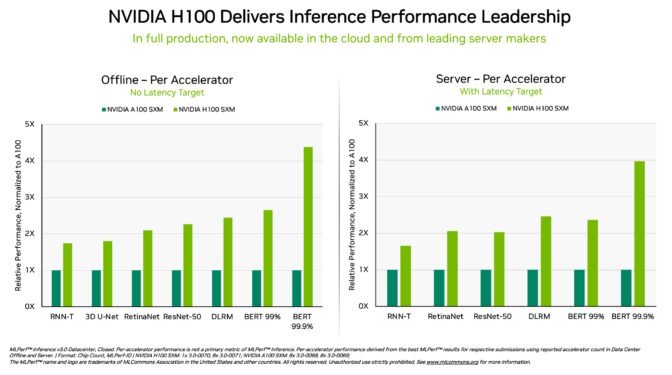
凭借其Transformer 引擎,基于Hopper 架构的H100 GPU 在BERT 方面表现优异,BERT 是基于Transformer 的大型语言模型,是现今生成式人工智能获得广泛应用的关键基础。
生成式人工智能能让使用者能够快速创建文本、图像、3D 模型等等,这种能力从新创企业到云服务提供商都在快速采用,以开创新的商业模式并加速现有商业模式的发展。目前数亿人正在使用像ChatGPT 这样的生成式人工智能工具(也是一种Transformer 模型),期望获得即时回应。
在这个人工智能的iPhone 时代,推论的效能至关重要。深度学习现在几乎被应用到各个领域,从工厂到线上推荐系统,对推理效能有着永无止境的需求。
NVIDIA L4 Tensor Core GPU在MLPerf 测试中首次亮相,其速度是上一代T4 GPU 的3倍以上。这些加速器采用低调外形封装,其设计旨在为几乎所有伺服器提供高吞吐量和低延迟。
L4 GPU 运行所有MLPerf 工作负载。由于他们支援关键的FP8 格式,他们在效能要求极高的BERT 模型上的结果尤其令人惊叹。
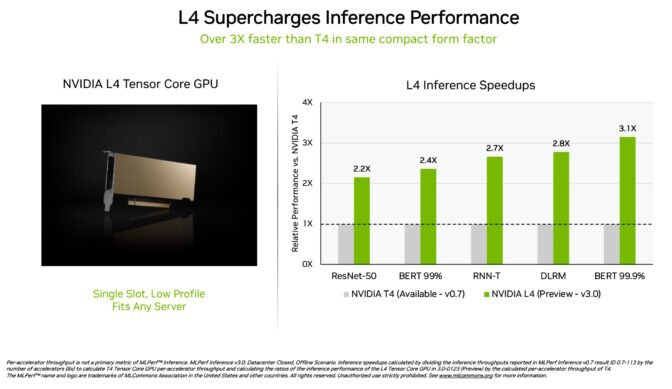
除了出色的人工智能效能外,L4 GPU 还能提供高达10 倍更快的图像解码速度,高达3.2 倍更快的影片处理速度以及超过4 倍更快的图形和即时渲染效能。
两周前的GTC上即宣布,已可从主要系统制造商和云端服务供应商获得这些加速器。L4 GPU 是NVIDIA 在GTC 推出的最新人工智能推理平台产品组合的最新成员。
在BERT测试中,远端NVIDIA DGX A100系统的表现达到了其最大本地性能的96%,速度变慢的部分原因是它们需要等待CPU 完成某些任务。而在仅由GPU 处理的ResNet-50 电脑视觉测试中,它们达到了100% 的最佳表现。这两个结果在很大程度上要归功于NVIDIA Quantum Infiniband网络、NVIDIA ConnectX SmartNIC和NVIDIA GPUDirect等软件。
另外,NVIDIA Jetson AGX Orin 系统模组的能效和性能表现,与前一年的结果相较,分别提高了63% 和81%。Jetson AGX Orin 可在有限空间以低功率水平(包括仅由电池供电的系统)提供人工智能推论。
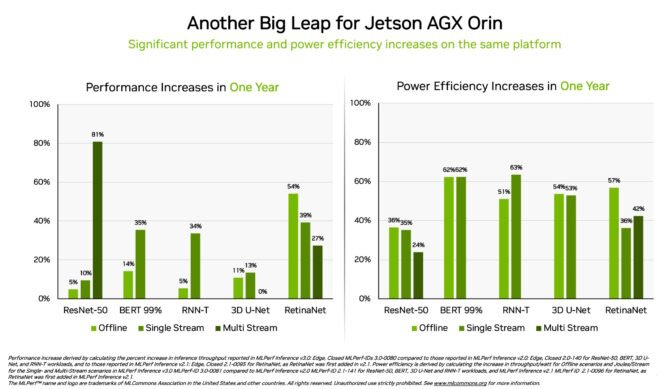
对于需要更小模块且功耗更低的应用,Jetson Orin NX 16G 在其首次亮相的基准测试中表现出色。它提供的性能比上一代Jetson Xavier NX 处理器高出多达3.2 倍。
从MLPerf 的测试结果便能看出NVIDIA AI 获得业界最广泛的机器学习生态系支持。
本轮有10 家公司在基于NVIDIA 平台上提交了结果。他们来自Microsoft Azure 云端服务和系统制造商,包括像是由华硕(ASUS)、戴尔科技集团(Dell Technologies)、技嘉(GIGABYTE)、新华三集团(H3C)、联想(Lenovo)、宁畅信息产业(北京)有限公司(Nettrix)、美超微(Supermicro)和超聚变数字技术有限公司(xFusion)。
它们的测试结果显示,无论是在云端或在用户自己的资料中心伺服器上,使用NVIDIA AI 获得绝佳效能。
 最前沿的电子设计资讯
最前沿的电子设计资讯
