
4月14日,腾讯云正式发布新一代HCC(High-Performance Computing Cluster)高性能计算集群。该集群采用腾讯云星星海自研服务器,搭载英伟达最新代次H800 GPU,服务器之间采用业界最高的3.2T超高互联带宽,为大模型训练、自动驾驶、科学计算等提供高性能、高带宽和低延迟的集群算力。
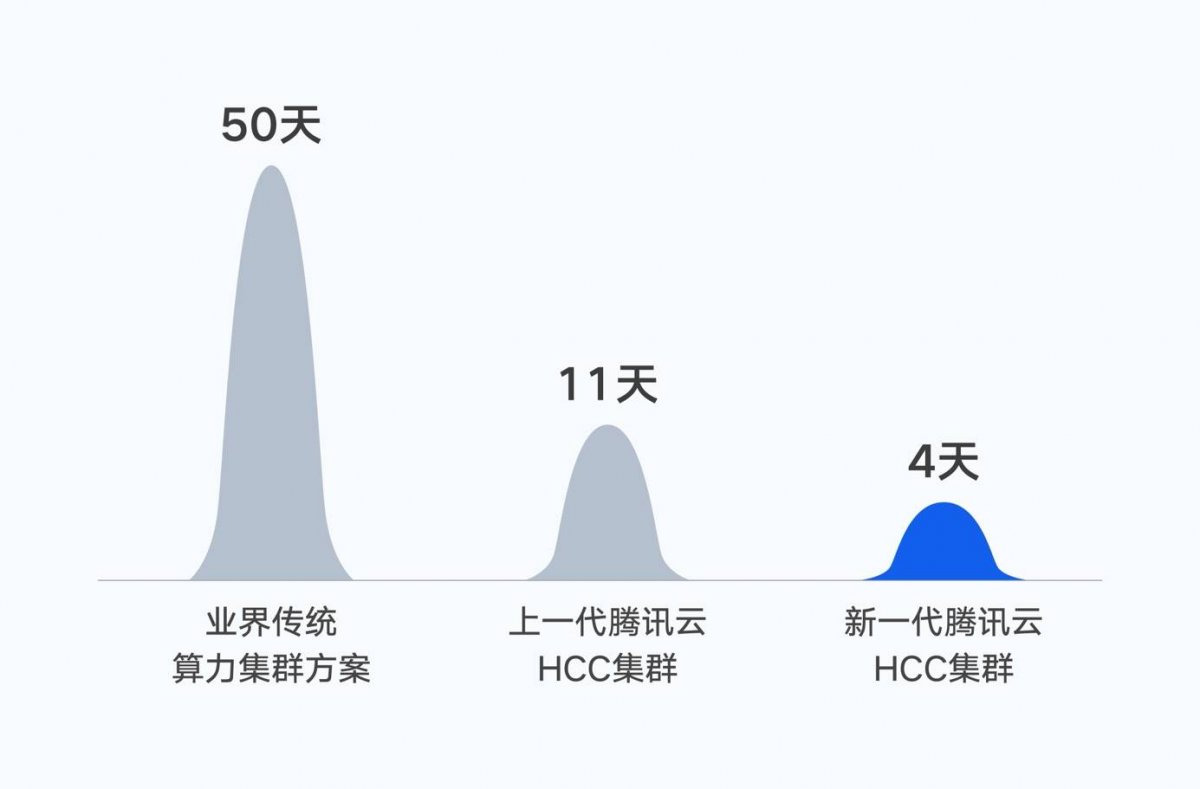
据EDN小编了解,2022年10月,腾讯完成了首个万亿参数的AI大模型混元NLP大模型的训练。基于腾讯自研的高性能计算集群、星脉网络和训练框架AngelPTM,在同等数据集下,将大模型训练时间由50天缩短到11天。
而人工智能大模型训练,离不开高性能的算力集群。腾讯称,此次腾讯云新一代集群通过对单机算力、网络架构和存储性能进行全面协同优化,能够为大模型训练提供高性能、高带宽、低延迟的智算能力支撑。如果基于此次发布的新一代集群,训练时间将进一步缩短至4天。
此次新一代HCC采用的腾讯自研的星脉网络,为新一代集群带来了业界最高的3.2T的超高通信带宽。实测结果显示,搭载同样的GPU卡,3.2T星脉网络相较前代网络,能让集群整体算力提升20%,使得超大算力集群仍然能保持优秀的通信开销比和吞吐性能。并提供单集群高达十万卡级别的组网规模,支持更大规模的大模型训练及推理。
同时,通过腾讯云自研的文件存储、对象存储架构,让HCC具备了TB级的吞吐能力和千万级IOPS,充分满足了大模型训练的大数据量存储要求。加之针对大模型训练场景,新一代集群集成了腾讯云自研的TACO Train训练加速引擎,对网络协议、通信策略、AI框架、模型编译进行大量系统级优化,大幅节约了训练调优和算力成本。腾讯的新一代HCC在在网络、存储和底层架构方面都得到了极大的突破。

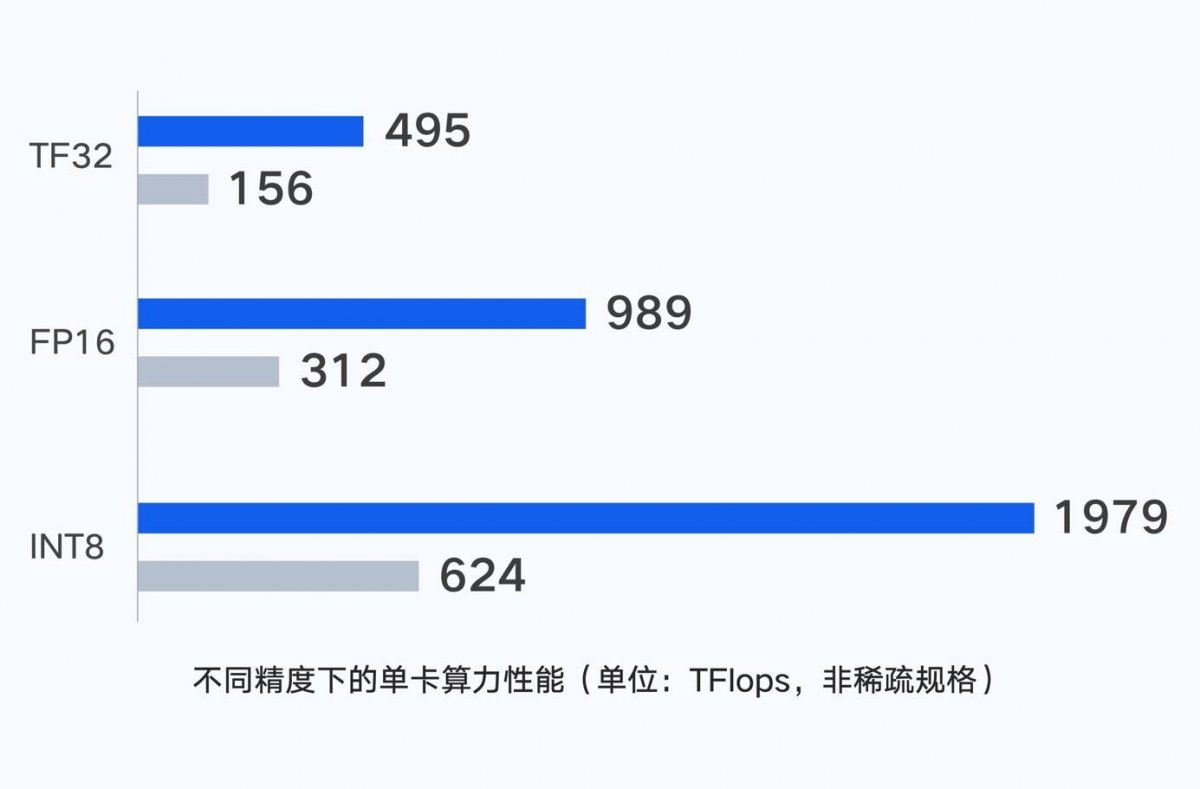
而在芯片方面,腾讯采用了国内首发的H800,这是英伟达的新代次处理器,基于Hopper架构,对跑深度推荐系统、大型AI语言模型、基因组学、复杂数字孪生等任务的效率提升明显。与A800相比,H800的性能提升了3倍,在显存带宽上有明显的提高,达到3TB/s。
目前,腾讯混元AI大模型,已经完整覆盖了NLP(自然语言处理)、CV(计算机视觉)、多模态等基础模型和众多行业模型。其背后的训练框架AngelPTM,也已通过腾讯云对外提供服务,帮助企业加速大模型落地。腾讯表示,正以新一代HCC为标志,基于自研芯片、自研服务器等方式,软硬一体,打造面向AIGC的高性能智算网络。
 最前沿的电子设计资讯
最前沿的电子设计资讯
