
据EDN电子技术设计报道,Meta近期开源了一个人工智能项目"Animated Drawings",任何人都能把他们的涂鸦变成动画。近日,西安交通大学也开源了类似的人工智能项目。
据EDN了解,该项目为SadTalker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片+音频就能生成高质量的视频。

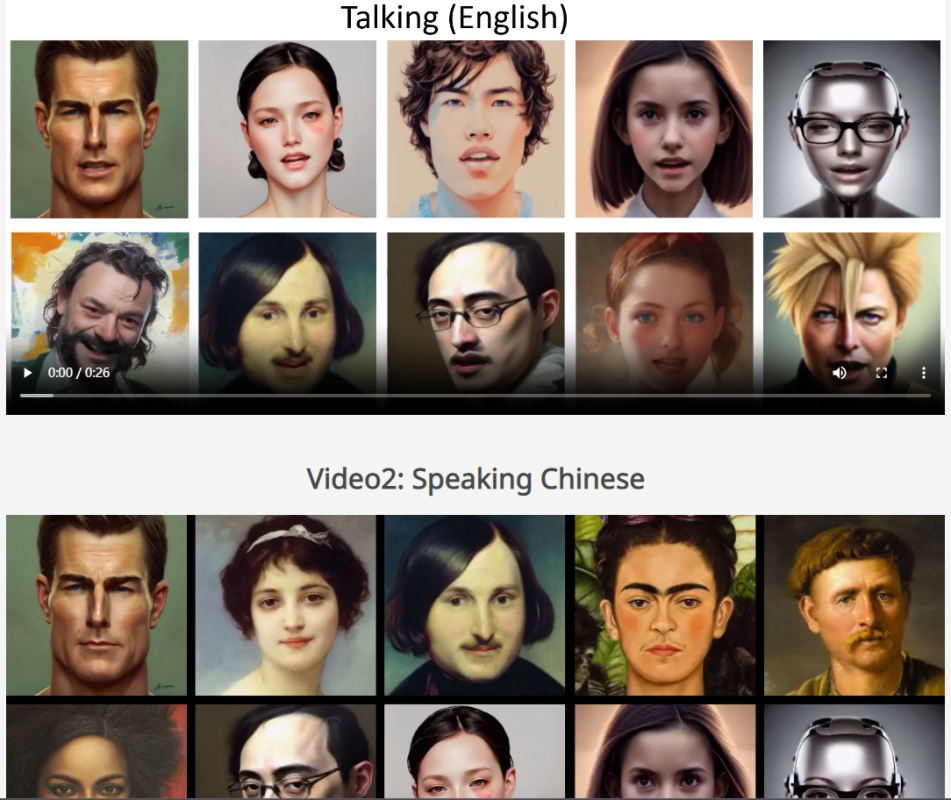
最后使用生成的三维运动系数被映射到人脸渲染的无监督三维关键点空间,并合成最终视频。
音频可以是英文、中文、歌曲,视频里的人物还可以控制眨眼频率!
研究天对进行了广泛的实验,以证明该方法在运动和视频质量方面的优越性。SadTalker模型的出现解决了生成视频的质量不自然、面部表情扭曲等问题。该技术可以应用于数字人创作、视频会议等多个领域。
论文链接:https://arxiv.org/pdf/2211.12194.pdf
项目主页:https://sadtalker.github.io/
 最前沿的电子设计资讯
最前沿的电子设计资讯
