
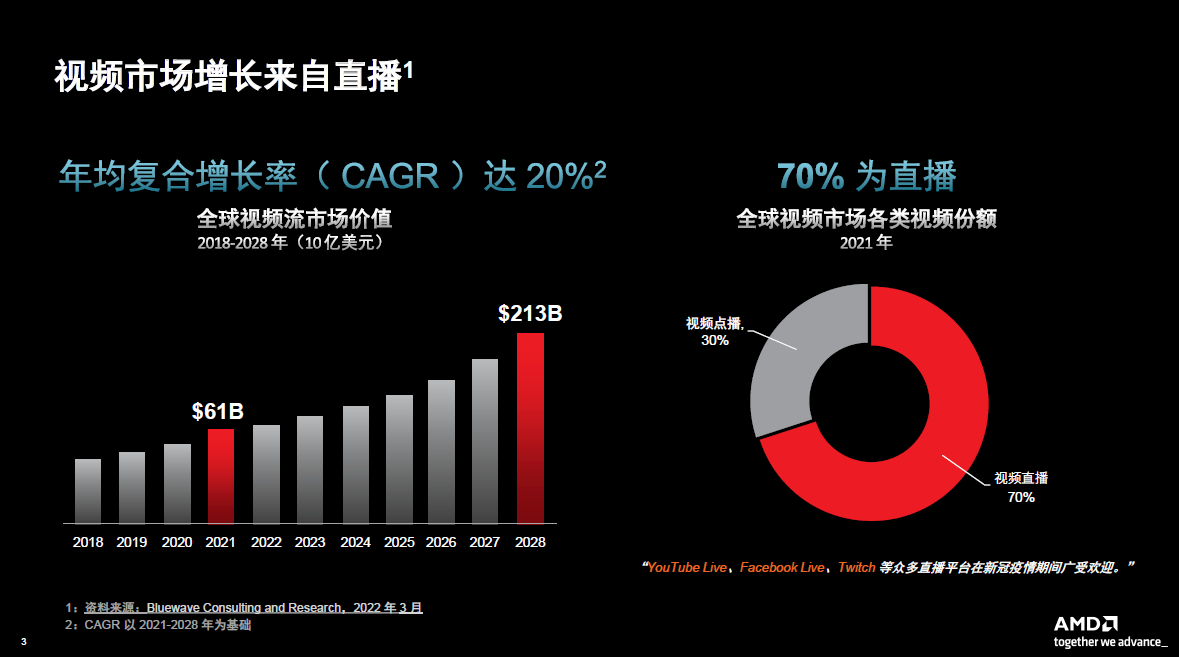
在实况直播市场,无论是在营收,还是在基础设施的部署方面,增长都非常迅速。2021年数据显示,全球视频市场超70%的份额由直播内容所主导。
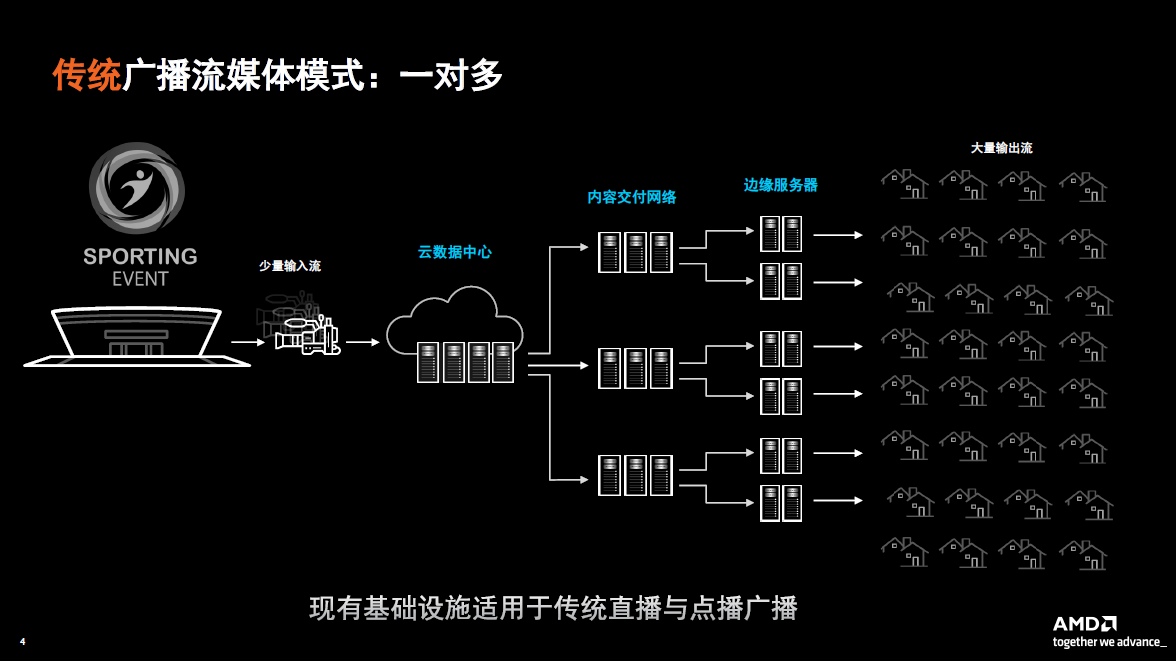
目前,传统的广播流媒体主要是由软件和CPU提供支持。传统的直播活动主要采取一对多的模式,由于视频流的数量比较少,同时时延比较可控,因而可以用比较传统的现有网络形式来支持直播服务。
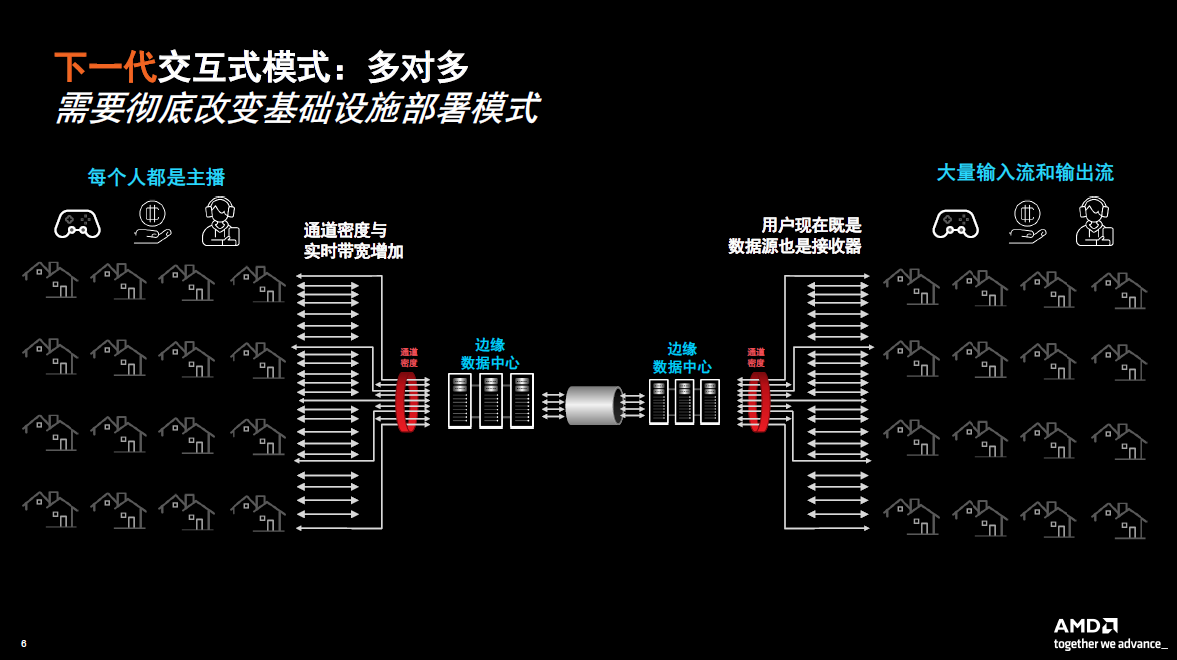
相较于传统的直播场景,下一代的直播场景则主要为多对多模式,即每个人都是主播,既是数据源也是接收器,这样的场景包括连线观赏、直播购物、在线拍卖和社交流媒体等。这样的应用场景要求对数据的处理更加贴近用户,要求把这样的处理转移到网络的边缘。在边缘来处理这些应用场景,意味着原来通过云集中的方式能够获得的经济效益已经不复存在了,因此也就需要彻底改变基础设施部署模式。

随着目前流媒体直播对时延的要求越来越高,而且部署在边缘的成本也在提高,这就驱使业界致力于开发新一代的实况交互式流媒体解决方案。这样的实时、交互式的流媒体应用场景要求低时延和大容量,新的架构才能够适应这些变化带来的成本压力。
日前,AMD公司视频转码事业部推出了全新的媒体加速器卡Alveo MA35D,其中包括了从芯片到板,再到软件的解决方案。据AMD视频战略与市场开发主管 Sean Gardner介绍,Alveo MA35D针对一系列新的应用场景进行了优化。该产品的命名,MA代表媒体加速器(Media Accelerator),35代表Alveo U30后的新一代产品,D表示两个(dual)视频处理单元的意思。

Alveo MA35D媒体加速器卡具备两个5nm基于ASIC的、支持AV1压缩标准的视频处理单元(VPU),专为推动大规模直播互动流媒体服务新时代而打造。
Alveo MA35D能够大大改善经济性,从而使得新的应用场景变得商业可行。比如,它同时具有高密度、超低时延的处理单元以及人工智能的赋能。Alveo MA35D卡可以以每流1W的功率每卡提供多达32路1080p60转码密度。Alveo MA35D的4K编码时延最低8ms,仅为常规处理时间(16ms)的一半。Alveo MA35D具备22 TOPS AI算力(INT8),可以支持非常多的新的应用场景,可以很好的来满足我们的客户对于行业的期待。“同时,我们也必须要保证Alveo MA35D的成本效益,所以Alveo MA35D的建议零售价1595美元也非常有吸引力。”Gardner补充说。
通过和上一代产品Alveo U30的比较,可以看到,Alveo MA35D的通道密度提高了4倍、功耗降低了3倍、时延降低了4倍。Alveo MA35D在方方面面都有非常优异出色的表现,而且还有很多额外的功能和新的能力。

“我们在开发Alveo MA35D的过程当中,从概念到算法到设计,再到卡到解决方案,都和有关的客户进行了非常密切的合作。通过协作,我们希望能够确保在大多数应用场景下,都能够实现产品所体现出来的种种效益。”Gardner表示。
要实现Alveo MA35D的相关的优势,也需要通过流媒体的供应商在部署下一代应用的过程当中来实现。“在卡的层面上,我们在设计和优化的过程当中预见到Alveo MA35D会对于客户如何看待我们的解决方案产生怎样的影响。客户在部署的过程中的基础设施是固定的,比如说占地面积,处理的功耗是一定的。所以我们也对32路通道都做了优化。”Gardner表示。
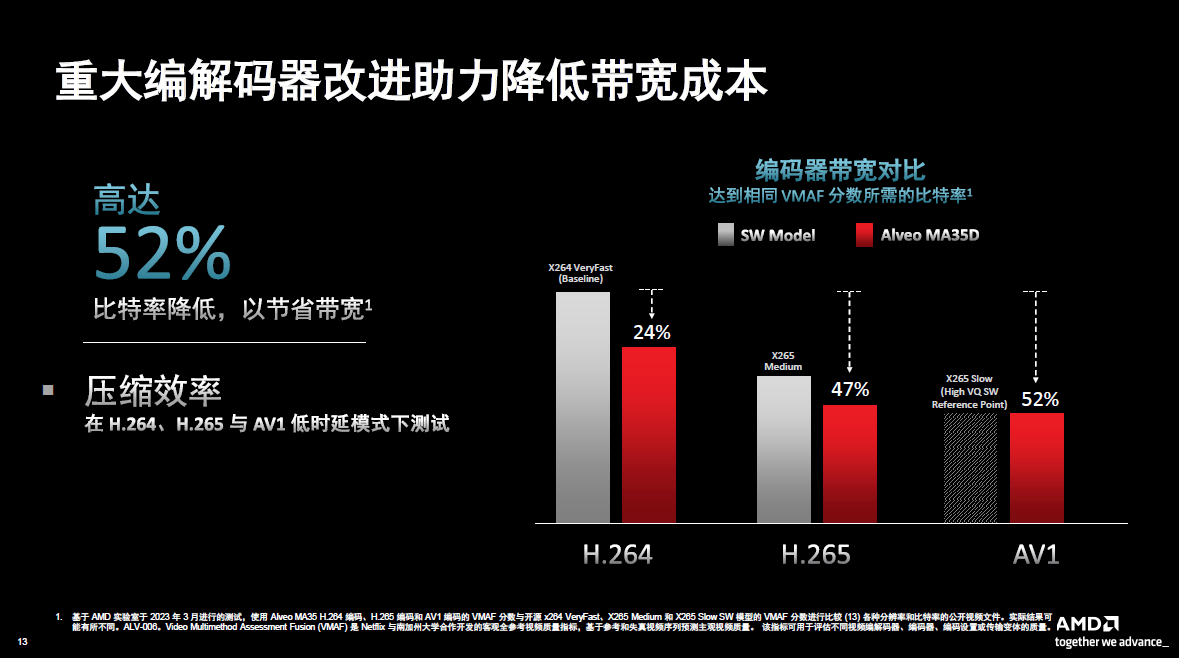
“配备8张卡的1U机架式服务器可提供256个通道,以实现每服务器、每机架或每数据中心转码密度最大化。数据显示,每个通道的成本是50美元,每通道的功耗是1W。由于我们采用非常先进的编码解码器,每个通道可节省高达52%的带宽。客户在评估效率的时候主要看的是每平方占地面积的成本,以及每个通道的功耗。我们这个解决方案从价格和性能来说性价比非常显著。”


Alveo MA35D如何实现上述卓越性能
首先,得益于Alveo MA35D新的专用视频处理单元(VPU)。在芯片四角有四个分离的支持AV1压缩标准的编码器(MP)单元模块。这使得客户在部署应用的时候,能够享受最大的灵活性。使得客户部署新的压缩标准时,可以一边用旧的标准,一边加入新的标准。在优化和开发编码器算法的时候,也要确保能够优化加速,从而使处理性能能够适应整个视频的处理过程。在现在和未来很多的应用场景中都会涉及到解码缩放和合成,所有这些都要通过Alveo MA35D的硬件加速来确保每个通道拥有最高的密度、最低的功耗和最低的成本。另外,它还叠加了人工智能和机器学习模块,通过这样的工具就能够确保在做视频处理的时候在降低比特率的同时提高视频质量。
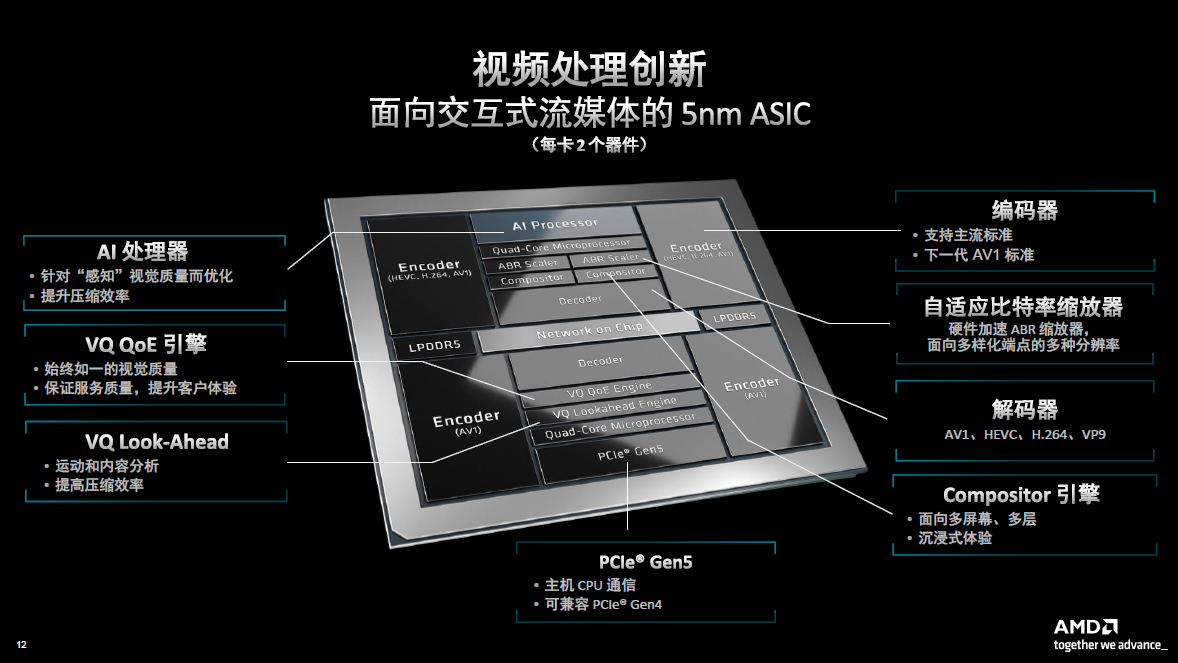
Gardner指出,客户希望能够以最低的成本,以及最低的每通道功耗,来实现最高的处理效率,因此Alveo MA35D对于客户来说非常有吸引力,尤其是相较于市场上其他的处理方案。下图展示了其非常先进的视频处理过程,借此即可支持未来的各种应用场景。
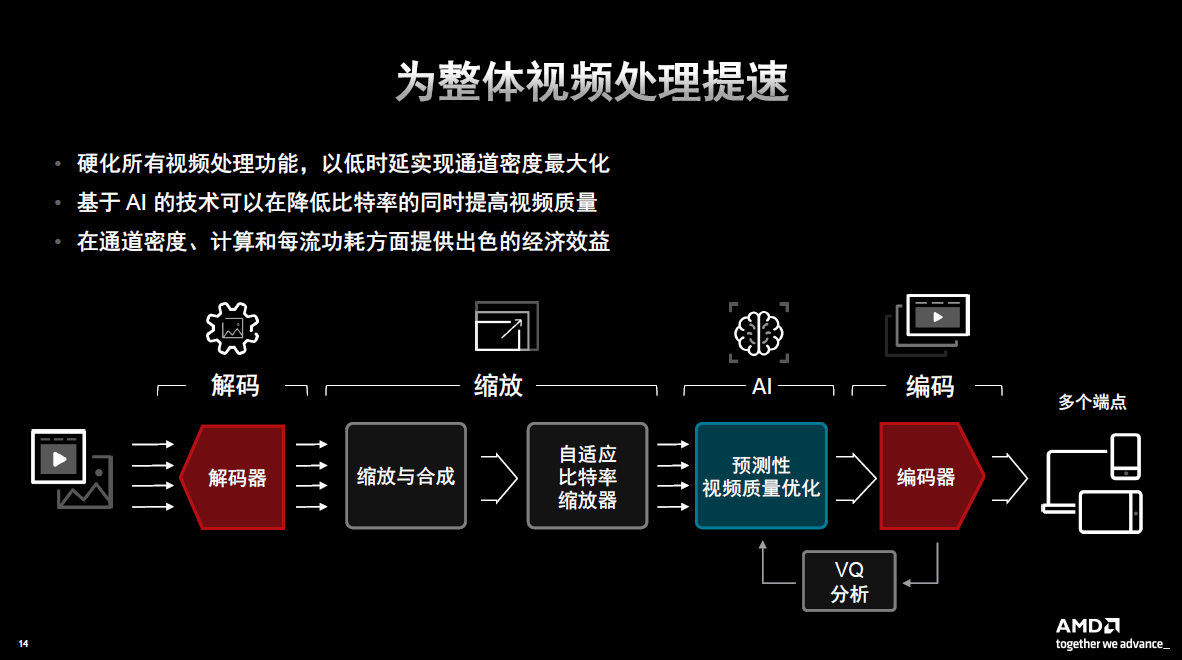
所有的这些处理都是在芯片和卡上完成的,也能够确保维持最高的密度,为客户实现最高的效率和经济性。
据Gardner介绍,传统的视频处理方案,无论是在设置还是在部署上,假设的都是最糟糕的情形,也就是说,如果它能够处理所假设的最糟糕的情形,那么稍好一些的情形就不会是问题。但是这种设计或者部署最糟糕情形和条件的方法的问题是效率非常低,而且成本会很高。因此AMD在Alveo MA35D创新的过程当中,引入了人工智能分析视频的内容。再加上Alveo MA35D人工智能和机器学习的能力,就能够更好地理解视频的特点,比如视频复杂程度如何、类型如何,是合成的电脑游戏,还是一些自然的内容。
有了人工智能和机器学习获得的洞见和智能,就能以更高的效率把这种动态的内容传导给编码器。通过这样的方式就可以在做动态视频处理的时候,降低带宽和存储要求同时提高效率。
举一个晚间新闻的例子,在一般的晚间新闻当中,都会有一个主持人以大头像的形式向大家进行播音,但是在这个过程当中,可能会切换到比如说汽车赛事等体育赛事,就会产生有非常多的动态,然后再切换回主持人的画面。正如刚才所介绍的那样,当主持人主持画面的时候,人工智能就能够配置编码器,降低带宽,但是在切换到体育赛事的时候,可以进行实时的动态调整。所以创造的是高度智能动态和优化的视频处理过程,可以规模很大而功耗和成本很低。
但是,人工智能并不完美,所以在做动态调整的时候,有可能会出现一些不准确,或者是判断失误的情况。所以AMD所做的一个创新就是VQ分析IP模块。该IP模块在人工智能进行动态调整和变化的过程中,会形成一个反馈环,来确保所做的决策不是错误的。通过VQ分析可以确保视频每一帧的质量,一旦出现错误都可以及时调整。“尽管类似的方案中已经在传统的模式中得以应用,但我们仍然很高兴地看到这个方案得以在这种实时的并且是非常低时延的应用场景中实现。”Gardner补充说。
带宽的消耗对于流媒体客户来说是非常大的一项运营开支。AMD也致力于改善其编码解码器。如下图中的柱状图所示,左边为基准,低于这一条线说明有节约带宽。当然,在这个过程中,都有一个假设的标准,也就是视频的质量,是能够达到通常的水平。所以通过这些参照的对比,就可以看到AV1的编码器可以达到同等的视觉质量,但是它在带宽的节省则高达52%。
在了解了人工智能和机器学习如何可以在视频的质量分析方面提供解决方案,现在再来看一种新的优势。下图中的两张图像都是按照同样的比特率进行的压缩,但是没有使用人工智能技术的图像有更多的瑕疵,也不那么清晰。如果这两个图像使用的都是同样的带宽,右边这张的质量就明显优于另一张。

通过人工智能技术可以找到人脸,然后在人脸这个重点区域分配更多的比特,在其他区域减少比特的配置。在这张图中,人脸的部分就被叫做重点区域。通过人工智能我们可以得知哪些是重点区域,并且在处理的时候,配置不同的资源。这就使得客户或者是流媒体的服务供应商可以做更加激进的压缩,并且降低比特率,同时还能够保证质量。重点区域不仅仅是人脸,有时候比如文本的测试和探知也同样重要。对于一个视频来说,有一部分小字,是非常重要的,这样也就可以保证其清晰度,Gardner表示。
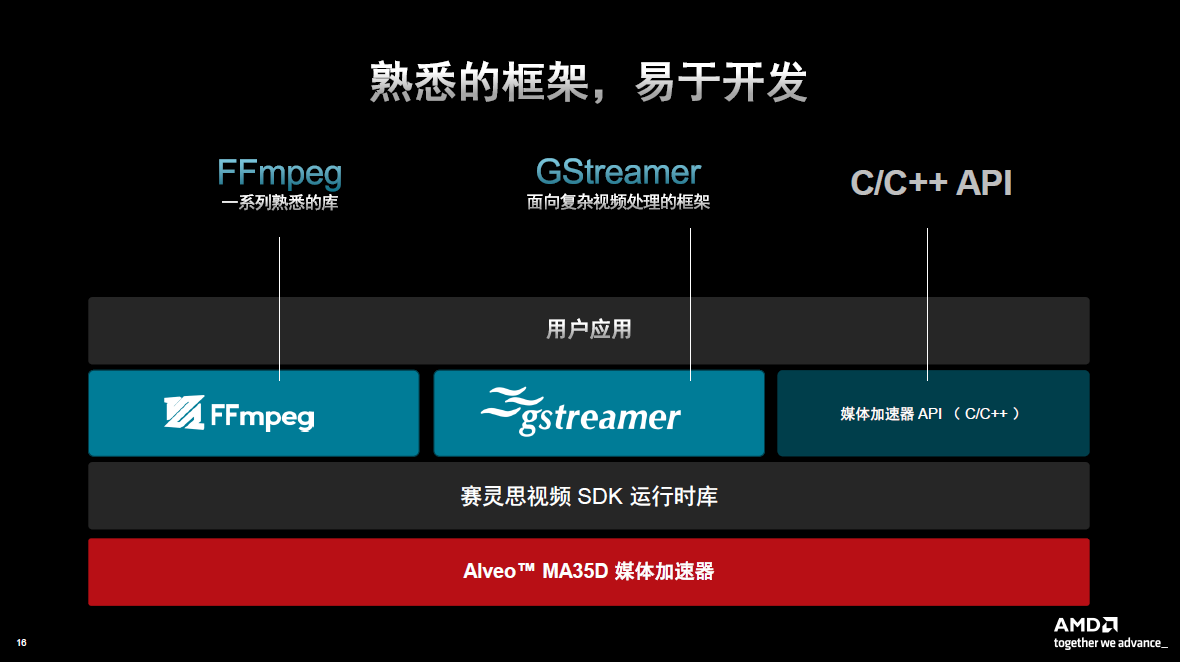
在做视频处理的时候,能够确保成本效益固然重要,但是最重要的是要能够使用这一技术。该平台可通过 AMD 媒体加速软件开发套件(SDK)访问,支持广泛使用的FFmpeg和Gstreamer视频框架,易于开发。有些客户有自己的框架,他们也会与AMD的媒体加速器API进行一个接口的连接。
Alveo MA35D对于AMD的CPU和GPU并非竞品,而是补充性的产品。所有这些产品都各有所长,而且效率都非常高。CPU可以提供非常高性能的压缩。但是如果要处理的是几百万个流视频,那么经济性就不高了。如果要要求图像的呈现的应用场景的话,GPU就是最好的一个工具。也有一些应用需要三者协作来提供非常具有成本效益和高性能的解决方案。例如云电竞或云游戏,GPU尽可能多的去呈现游戏内容,Alveo MA35D完成所有的低时延高质量的编码,EPYC CPU可以完成所有的应用级的系统处理。这样的组合能够给客户提供最高的密度,同时以非常优惠的价位和很低的功耗来实现。

下图进一步解释了EPYC CPU对于某一类型的APP是非常出色的,Alveo MA35D对于其他类型的应用是非常适用的。总的来说,软件和CPU适用于数量比较少的流视频,Alveo MA35D适用于有几百万个流视频的交互场景。

Alveo MA35D 媒体加速器卡现已提供样品,预计在第三季度量产出货。最后,总的来说,Alveo MA35D是AMD从头研发的,针对的是大容量、交互式流媒体的优化,目的是希望无论是在资本支出还是运营支出方面都实现很高的成本效益。

 最前沿的电子设计资讯
最前沿的电子设计资讯

