
目前,亚1nm芯片技术已经在望。欧洲微电子研究中心(imec)在比利时安特卫普所举办的ITF World大会,让我们得以一窥面向亚1nm的主要工艺节点和晶体管架构,并且该时间线将一直持续到2036年。根据Tom's Hardware网站上发布的一篇新闻报道,虽然晶体管数量将继续按照摩尔定律的轨迹翻倍,但在imec看来,人工智能(AI)和机器学习(ML)应用所需的原始计算能力大约每六个月就会翻一番。

图1:在比利时安特卫普举行的ITF World大会,展示了到2036年处理器节点和晶体管架构的路线图。(图片来源:imec)
该活动还强调,除了尖端的硅片工艺节点外,基础问题也越来越成为每一代新芯片的棘手问题。例如,互连带宽的限制严重滞后于现代CPU和GPU的计算能力。这阻碍了性能并限制了这些硅片器件中额外晶体管的有效性。
该活动中所概述的路线图强调了互连的持续缩小,这与3D堆叠芯片设计一起,将对为亚1nm硅片铺平道路至关重要。以下是主导imec亚1nm芯片技术路线图的四个突出亮点,它们将推动新型互连和工艺节点的进步。
虽然标准的FinFET晶体管将持续到3nm工艺节点,但新的环栅(GAA)纳米片制造技术将在2024年接管2nm芯片的大批量生产。GAA技术使用了与多个鳍片相同的驱动电流,有助于提高晶体管密度和性能。
此外,GAA晶体管通过让栅极完全包围沟道,显著减少了漏电。然后,根据imec的路线图,叉片晶体管——GAA在其最基本级别的更密集版本——将从2nm节点接过接力棒,并持续到0.7nm节点。

图2:芯片制造技术可能在近十年内从FinFET发展到CFET。(图片来源:imec)
接下来,imec预计互补FET(CFET)技术在2028年左右到达时将进一步缩小晶体管尺寸,从而创建1nm节点,进而实现更密集的标准单元库。CFET晶体管将NMOS和PMOS堆叠在一起,以便实现更高的密度。随后的突破将包括具有原子沟道的CFET版本,进而使性能和可扩展性得到进一步提高,同时达到0.5nm和0.2nm节点。
系统技术协同优化(STCO)是一种设计方法,它通过对系统和目标应用的需求建模来重新组织IC设计过程,然后在创建芯片时使用这些知识来做出明智的决策。简而言之,它分解了单片芯片的功能单元——例如缓存、I/O和电力传输——并将它们拆分为单独的单元,以使用不同的晶体管优化每个单元,从而获得所需的性能特性。
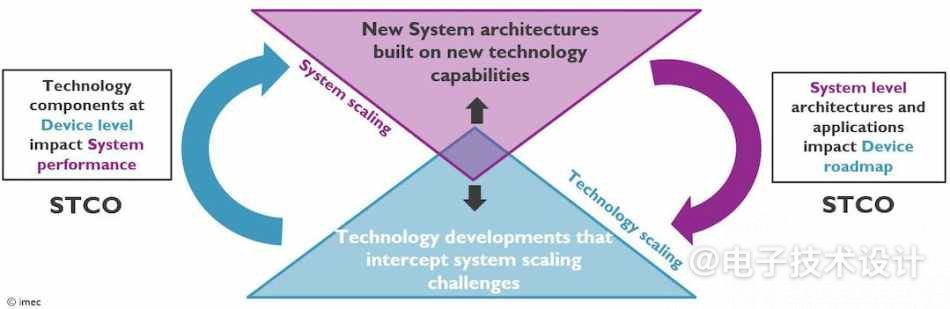
图3:STCO框架示意图——STCO旨在打破未来芯片设计中的性能、功耗和密度缩放障碍。(图片来源:imec)
分解标准芯片设计的目标之一,是将高速缓存和内存拆分为3D堆叠设计中的不同层。这反过来又要求显著降低IC堆栈顶部的复杂性。在此,imec建议改进后端生产线(BEOL)流程,重点关注将晶体管连接在一起,同时在芯片上实现通信(信号)和电力传输。
这就将我们带到了imec亚1nm硅片路线图中的下一个重要方法。
背面供电网络通过晶体管的背面路由所有电力,它实际上会随着2024年2nm节点的出现而首次亮相。它将电源电路和数据传输互连分开,从而改善电压下降特性并允许在芯片顶部进行更密集的信号路由。信号完整性是简化布线的另一个受益者——简化布线有助于实现更快的布线,并能降低电阻和电容。
BPDN技术将电力传输分配到晶体管的背面,而数据传输互连则保留在另一侧的传统位置。接下来,将电力传输网络移至芯片底部,即可更轻松地在裸片顶部进行晶圆间键合,从而在内存上实现逻辑堆叠。

图4:BPDN实现示意图,显示了纳米片通过硅通孔(TSV)连接到晶圆背面的位置。(图片来源:imec)
台积电计划在2026年在其2nm节点的量产中实施BPDN,而英特尔则计划在2024年推出的2nm节点中实施该技术。英特尔将其BPDN技术称为PowerVIA,预计该公司将在今年晚些时候提供有关该技术的更多详细信息。三星是该纳米竞赛的另一个主要参与者,它也有望将BPDN纳入其2nm芯片制造节点。
CMOS 2.0是imec今年在比利时所举办大会的一个突出主题,它在很大程度上依赖于BPDN方法。它的目标是将芯片分解成更小的部分,同时将高速缓存和内存拆分成具有不同晶体管的独立单元。然后将这些较小的部分以3D排列堆叠在其他芯片功能上。
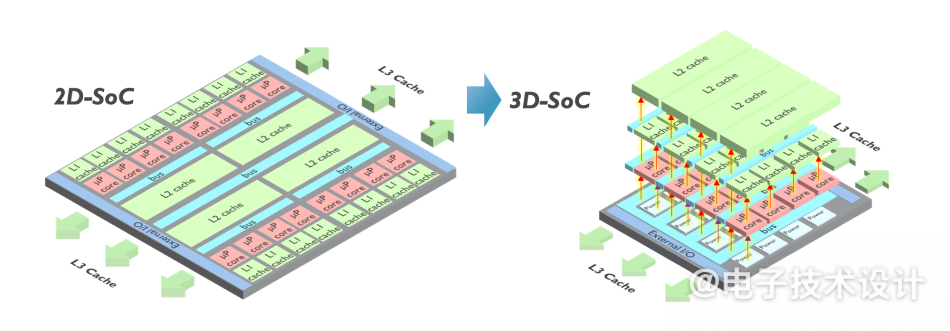
图5:片上系统(SoC)设计的3D功能分区,将该器件分解为多个级别的内存、逻辑和I/O。(图片来源:imec)
值得一提的是,3D芯片设计已经上线,例如AMD的第二代3D V-Cache将L3内存堆叠在处理器之上以提高内存容量。然而,imec想要通过将整个缓存层次结构包含在其自己的层中来将其提升到一个新的水平。换句话说,它想将L1、L2和L3缓存垂直堆叠在它们自己的裸片上而位于构成处理内核的晶体管上方。
因此,当每一级缓存都采用最适合任务的晶体管创建时,就可以用较老的节点来扩展速度变得非常慢的SRAM。反过来,这种缩放问题会导致缓存占用更高比例的裸片,从而导致每MB成本增加。3D堆叠的使用可实现缓存大幅增加,并且还能解决与缓存变大相关的延迟问题。
 最前沿的电子设计资讯
最前沿的电子设计资讯
