
6月8日,在由AspenCore主办的2023国际AIoT生态发展大会上,安谋科技产品总监杨磊分享了安谋科技对于GPT这类AIGC的一些思考。

其实,“像美颜、瘦脸等传统AI应用目前都有点开始慢慢降温了。那么做AI的企业,未来在哪里?”他指出。好在今年年初GPT突然火爆出圈,其最主要的变革是大家认为GPT这种场景会改变人和机器交互的形式和方法。
可以设想一下,有个会议很重要,会后要写一个报告。我们现在可以怎么办呢?可以把手机掏出来,打开录音,放在桌上,就可以把全程演讲者的语言直接变成文字。再进一步,可以让它直接写出一个总结,直接写出一两页的PPT,周一直接把报告交上去了。它大大提升了我们工作和生活的效率!
还有一种场景,包括芯片开发,我们经常会写代码。当我们有了这样一些AIGC或AI的工具,可以怎么写代码呢?我们可以打开电脑,要求它写一个滤波器程序,它就能自动地把一段代码(比如Verilog的)生成出来。这样一种方式就能节省我们大量代码开发时间。
据估计,基于这样一种形式,工程师大概可以节省70%的工作时间。“因为代码的生成,不是100%准确或对的,还是需要工程师人工做一些修改调整,把它从70分变成真正100分的代码,最终提交到我们产品当中。”杨磊解释说。
通过这样两个小的例子可以看到,未来AIGC或大模型的场景会潜移默化地影响到我们生活的方方面面。
这个东西虽好,但它也带来很多新的实现挑战:
第一,传统的AI算法,比如美颜,包括人脸识别、刷脸等,它都是一种卷积神经网络(CNN)的结构。像GPT这类模型则是基于Tranformer的结构,它的核心计算是大的矩阵图版,比如矩阵A×矩阵B的转置,再乘个C。另外,它还涉及大量的Softmax和Normalization等计算,所以它从底层计算类型角度来讲跟传统CNN算法是不太一样的。有人说,我以前做了一个适用于传统CNN或语音的NPU,专门做AI处理上的处理单元或硬件单元,它不一定擅长能够高效地计算AIGC类的模型。
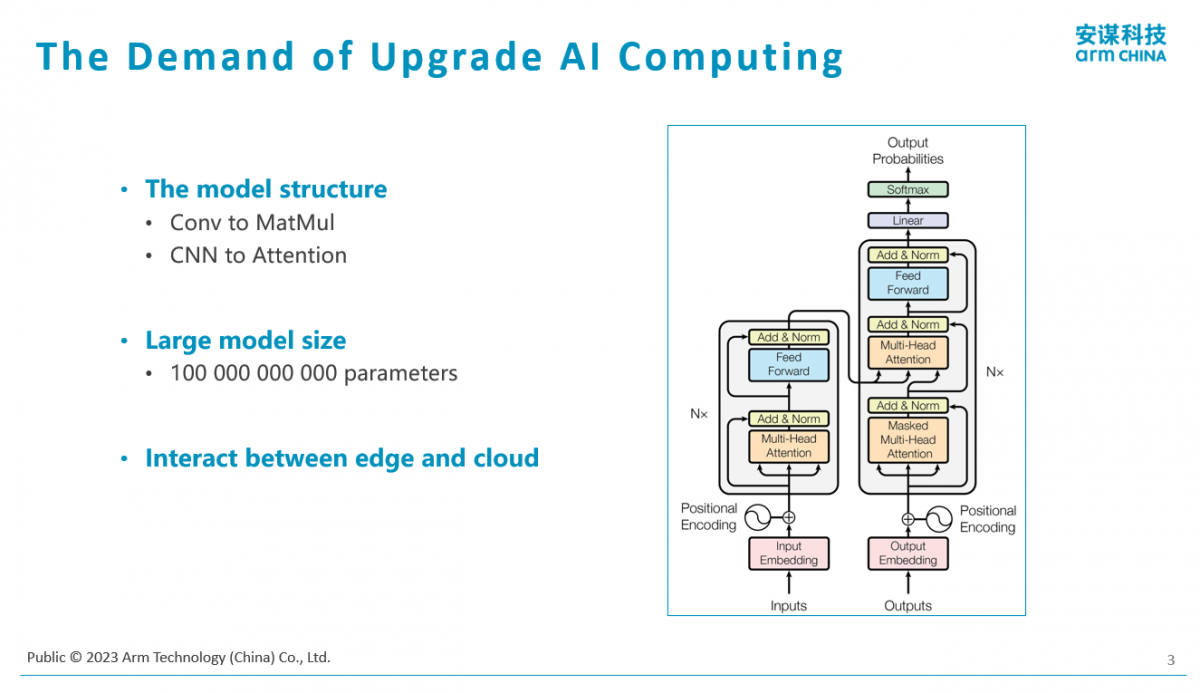
第二,既然叫大模型,它一个最大的特点是大。有多大呢?我们可以看GPT3.5,基本上是一千多亿个参数。“我们可以把它翻译成我们做芯片、做硬件更熟的语言,比如它需要把这个模型存下来,需要大概100GB,这是一个超级大的规模。比如我们做颗芯片,片内可能有1MB SRAM,相比之下,100GB就很大规模了。”他解释说,“并且我们跟很多做学术研究的人在交流,这个大到头了吗?其实还没有,因为大家觉得‘暴力出奇迹’,准确度也好,性能也好,预期会是这样一个曲线,到了某个节点就会收敛。但是我们现在还没有摸到那个头在哪儿。”
“比如现在新的模型都已经到了三千亿个参数,还在暴力地往上涨。但是,理论上它应该会到达一定的规模,就到头了。”
“还有一类需求是,如果这么大的模型,其实只能在云上跑了,没办法在IoT领域实现。另外它太贵了。今年最新价格比什么?我有一万块英伟达的显卡、我有两万块英伟达的显卡,显卡一块怎么也得花一两万美金,所以光买设备就花了几亿美金,这只是生产工具,活还没干,消耗就这么大。”
“还有一个趋势是做精简。能不能结合一些特定的场景和应用,把这种模型往小了做,而使得它也能在端侧IoT场景上造福我们的生产生活?举一个简单例子,谷歌之前发布它的大模型PaL,分了四个尺寸,最小的尺寸其实可以在手机上运行。学术上,它有两个路径,有一类是想努力把它小型化,而使得它能够在手机、PC以及边缘设备和汽车等场景上去实现各种工作形式。”
“最后还有一个难点是,它对于存储和带宽也有很大的要求。比如一个100GB的模型,做一次推理,生成一个字,理论上需要100GB的带宽。一般旗舰型手机、高端手机也就是64GB到168GB带宽。如果不做任何优化,手机用满了也只能跑一个字,一秒钟只出一个字肯定是不够的。同样,带宽也是瓶颈。”
结合新的GPT的特点和一些小型化的场景,以及在端侧应用的诉求,安谋科技推出了一个专门面向AI处理的新一代NPU——“周易”X2 NPU。

这个新推出的NPU考虑到了新的AI结构的特点:
第一,它具有很好的灵活性和可编程性,它可以适应模型结构的变化和演进。它不单单适合于算传统CNN模型,它也很擅长算Tranformer类的模型结构。
第二,对于大的模型,它的计算精度(准确度)要求比以前要高。像以前做刷脸,一般都会把模型进行定点化,模型的真正计算都是定点8比特的计算。这样的好处是面积小、成本低,但是对于这种大模型,如果全部做8比特量化,其实它的精度就不可控了。最后的结果是,本来浮点场景下可能做到80%精度,但是做定点化之后就会掉得很厉害。因此,我们就需要折衷计算精度和成本,更好满足端侧场景。“因此,我们推出了混合精度,我们NPU既支持以往8比特的计算,也支持浮点半精度FP16计算,从而在部署AIGC模型,它是混合精度的部署。有一些对精度不敏感的计算,其实还是可以用高性价比的定点8比特甚至4比特去做计算的。对于计算精度敏感的,我们用半精度的FP16计算,这也是我们结构的特点。”杨磊补充说。
第三,因为是专门面向AI计算的引擎,所以它里面有针对AI计算的硬件加速单元。
下面是新一代NPU结构的框图。它是一个Scalable的结构。它的好处是可以做小,最小可以到1TOPS算力,这就很有机会跟高端或者超高端MCU合作。它还可以做得很大,通过多核的实现,可以做到上百TOPS算力。“我们通过可扩展的NPU结构,会覆盖到从边缘AIoT领域到手机、到PC、到汽车,甚至到云端加速卡的场景。这是我们的一大特点。”杨磊说。
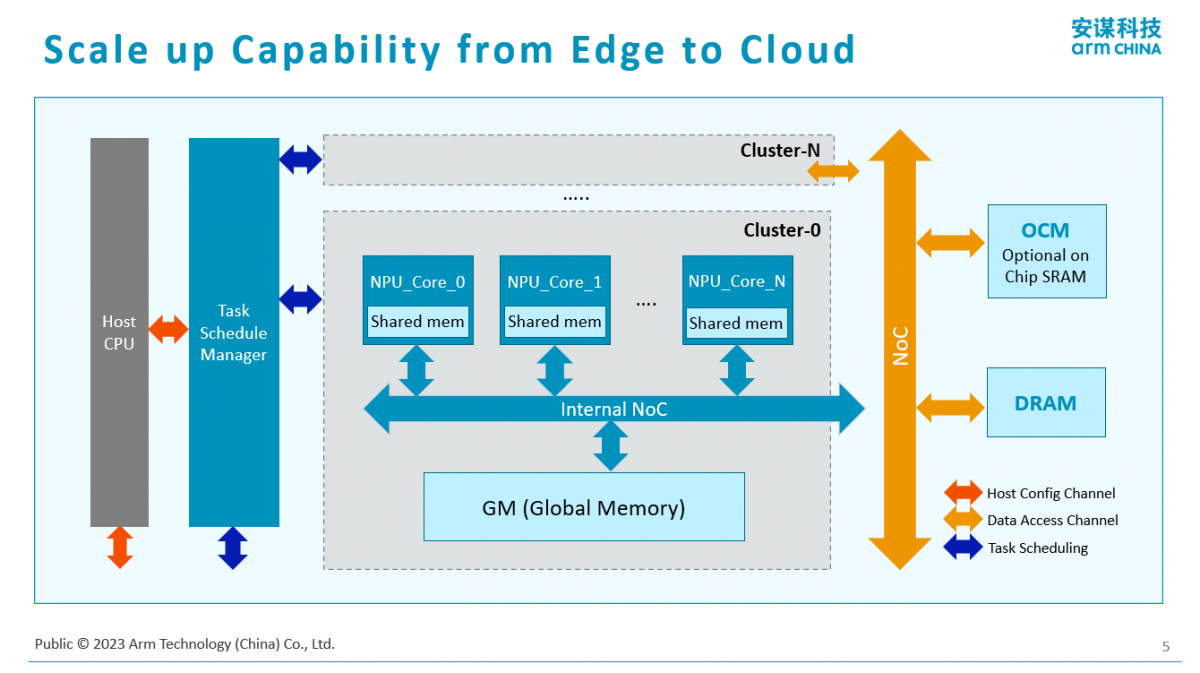
针对Tranformer这样的结构,该NPU有专门的优化实现。第一类是对于矩阵乘,像GPT的模型,它核心的计算是矩阵的乘法,这种专门做了硬件加速。第二部分是对于激活包括均衡做了优化,典型的Softmax计算和Normalization计算。通过硬件优化手段,使得这一代产品与上一代产品相比,针对像Tranformer这样的大模型,它相同的寿命计算效率会有10倍的一个数量级的提升。
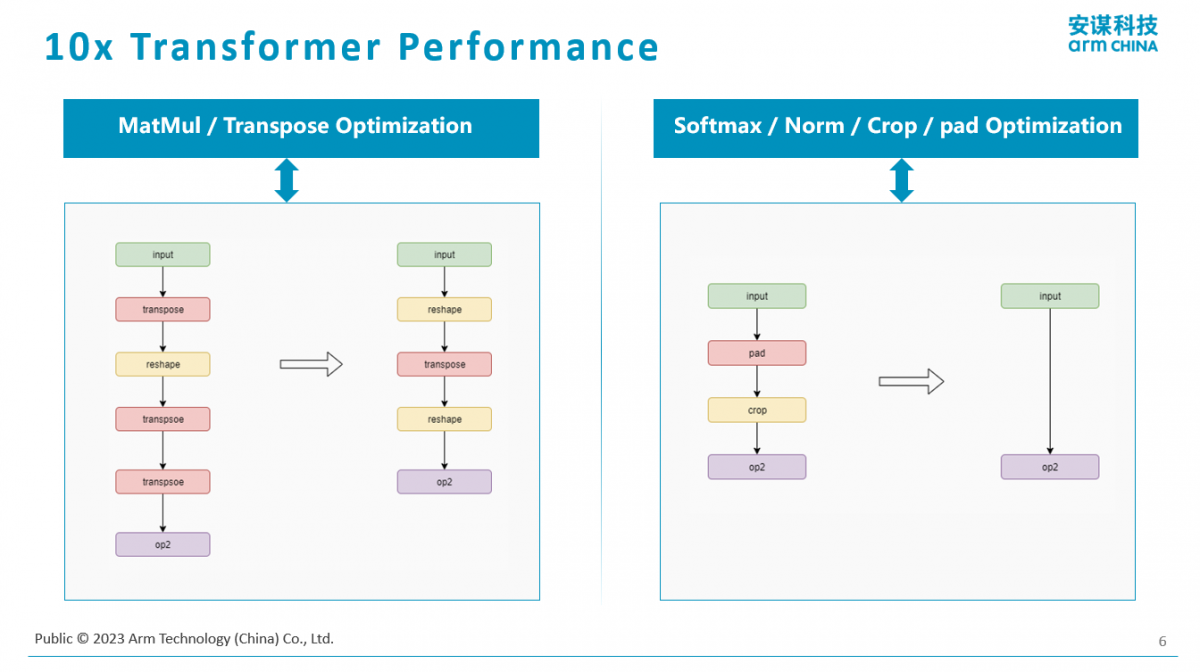
其实模型大了,无论是在存储还是带宽上都有特别大的压力,所以Arm在此推出了一种Tiling的技术,就是把大模型拆成小块,切4刀、切16刀甚至切128刀。每个小块的计算量是很小的,另外,每个小块的存储和带宽的需求也是极其小的。最终通过这样一系列的手段,就使得我们做一次推理的带宽可以减少90%以上,也即使带宽需求降低了一个数量级。
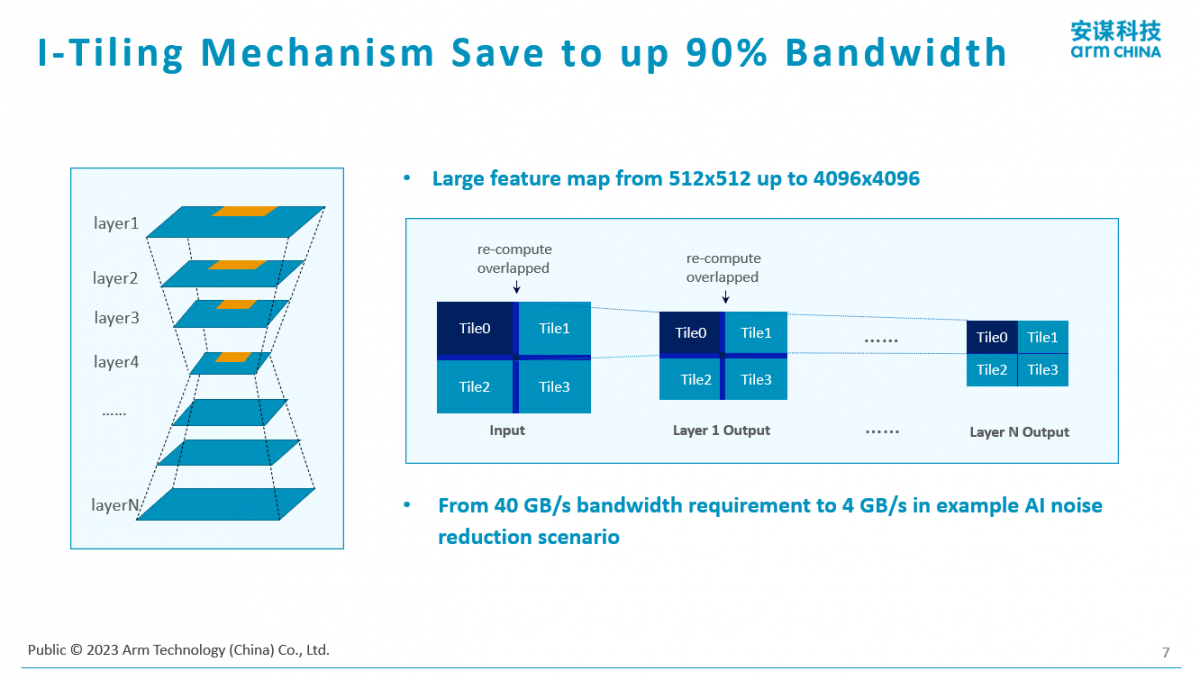
另外是关于精度的思考。大模型纯靠定点做的精度是不满足需求的,所以Arm也推出了混合精度的实现。“并不是说计算全部是定点或者全部是浮点,通过混合的精度方式达到一种最优的性价比。在不敏感的时候,我用定点的4比特、8比特或者16比特。对于精度敏感的就用半精度敏感的浮点16比特做计算。”杨磊解释说。
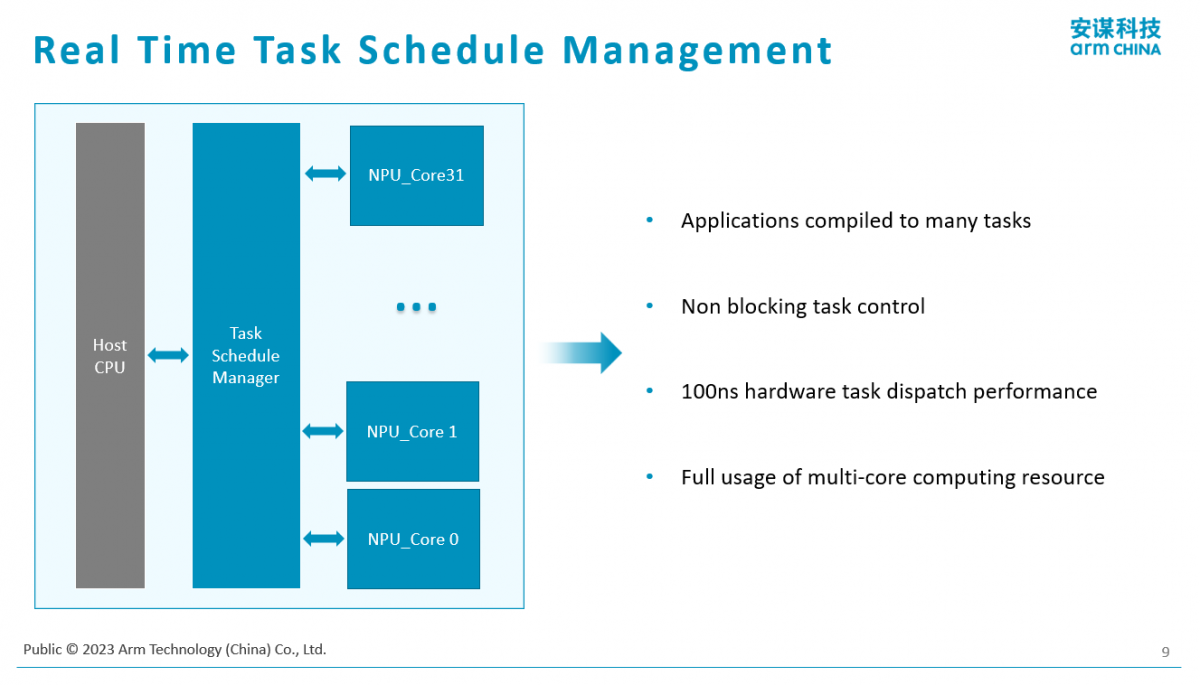
如果是一个单核的小场景,比如IoT设备,在家电、网关这些场景里,一般是单个单核NPU实现,因为它的算力基本是几TOPS的水平。对于一些能力强的会涉及到多核的实现。现在的智能手机,尤其是旗舰型手机,它的算力已经达到30TOPS了,这就是相当大的算力。如果看一些厂商的目标,明年我们的手机或笔记本电脑的算力就会达到45TOPS。相信在不久的将来,手持设备的算力能达到100TOPS的算力。这样的算力,就涉及到多核的实现。“多核实现最复杂的其实是对于多核的使用、调度,在这块我们有专门硬件加速的实现支持多核多任务的实时调度,这也是我们这一代的特点。但这个应用特点主要更多的是面向高端的边缘应用,像汽车、云的应用。对于IoT场景来讲,我们看到的一些实现主要是单核的实现,拼的是在一个小场景下设计的精度和效率。”杨磊指出。
下面是Arm做的一个GPT的Demo。“既然是面向大模型的优化,我们已经把一些开源的AIGC模型在NPU上做了一个部署。GPT 2就是开源的。因为3、3.5和4已经是闭源了,并没有开源,所以我们跑的是老一点的。”他解释说,“老一点有好处,它的模型比较小,只有340MB。虽然跟1000亿比少了很多,但本质上还是很大的。像我一开始举的例子,我们做美颜的时候,那个模型一般比它小一个数量级,一般是二三十MB,这个模型相对而言还是比较大的。我们现在可以用一个单核、用一个很小的MPU实现GPT2的实时部署。什么叫实时部署?它跑一次会吐出一个字,咱们一般人说话一秒钟也就是几个字的水平,我们可以做到一秒钟算50个字,所以远远达到实时性的要求。”

现在的计算效率已经是足够高的,甚至还有空间把它拆到更小,小到在现在的IoT设备里尝试部署一些跟GPT应用相关的计算。其实它改变的是人机交互的形式。不单单以前是靠手一摁或者是老一点的语音交互,其实并不是太智能。
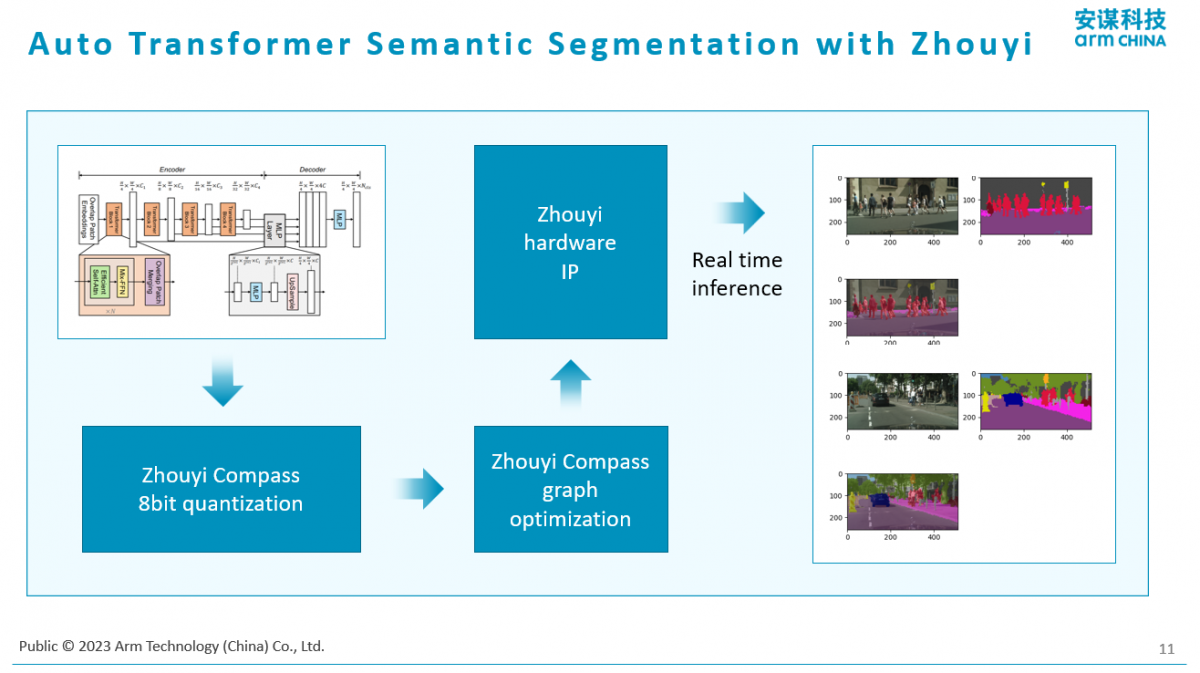
下面是面向汽车的场景,跑的也是Tranformer。既然是讲GPT,所以这里跑的也是Tranformer。这是一个基于视觉的ViT Tranformer的实现,它主要是做一个分割。它把视频的画面根据不同的路径做了分割,这是汽车里最常见的一种场景。也可以高效部署ViT Tranformer的结构,而不单单是GPT这种语音的,他补充说。
下面是一个典型的例子。“我们现在基本上如果想做边缘的计算平台或者做PC、平板,我们最想推荐的是3核X2的实现。这个例子,单个核心是10TOPS算力,三个核加起来是30TOPS算力的规格。基本上在目前看,应该算边缘侧的顶配,它可以部署像前面所提到的,像GPT2类型的,包括像画图这样风格的模型。当然还有裁小的空间,它的计算能力超过了实时性的要求,可以做到单个核,甚至把核再减一半也是可以的。”杨磊说。

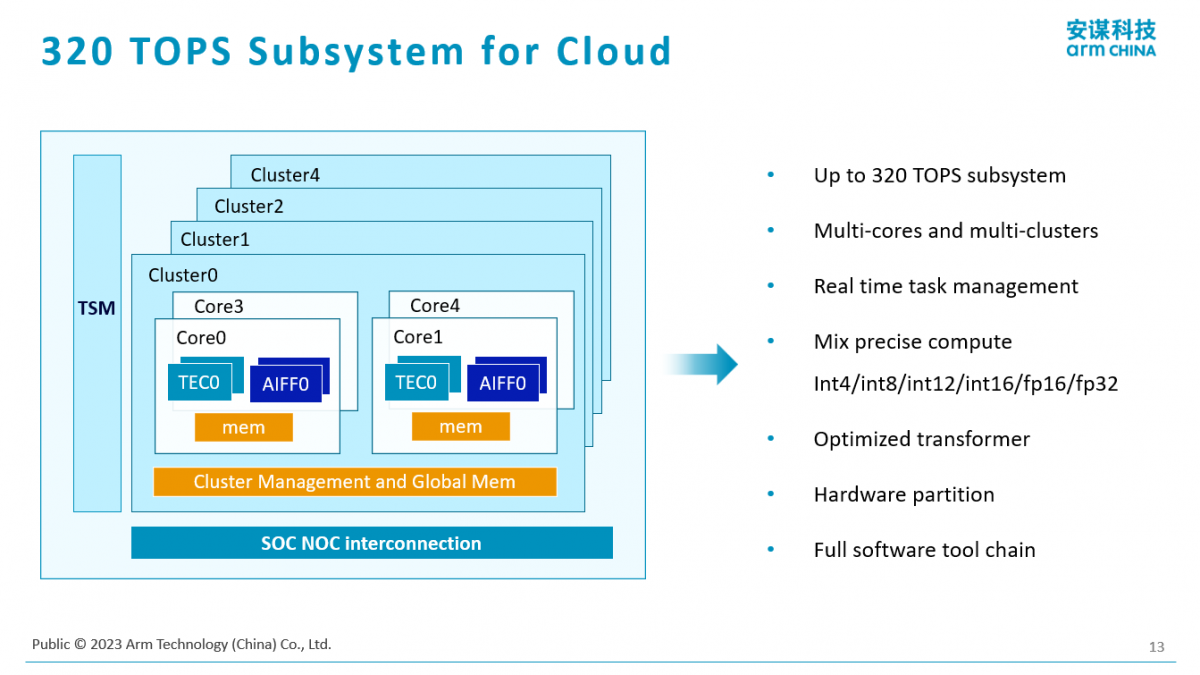
“这是更大的,刚才谈到是边云一体的,其实我们有更大的配置,这个配置可以到320T算力。”
光有一个硬件在使用端不方便,所以Arm还提供了一套完整的软件工具链配合用户部署一些算法。在这样的平台上,也是有自己的编译器、调试器,调试器又包括调试是否正确,包括调试性能。还有软件的仿真器,在做软件开发和部署的时候,即使没有硬件的板子或者设备,也可以直接在PC上去模拟AI的功能,去看算法的精确度、算法的性能等等。
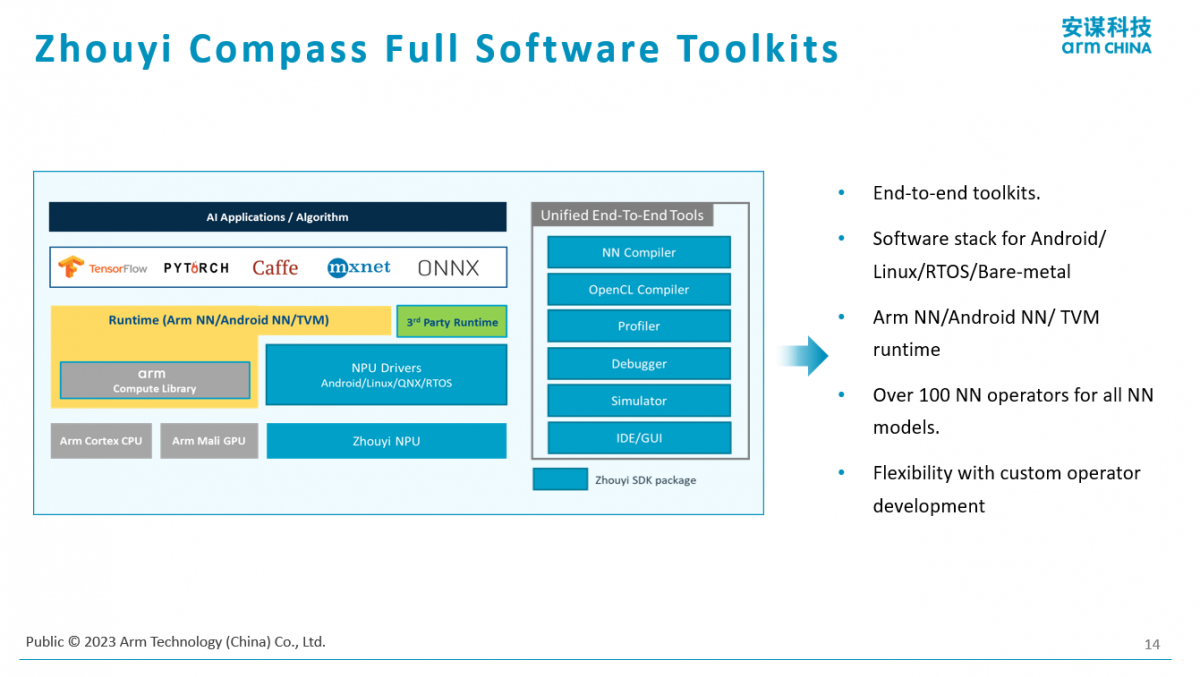
这是一个典型的使用场景。首先是有一个算法,这个算法怎么部署到硬件上?用前面提到的编译器,就会把它编译成一个NPU的可执行文件,其实用起来有点像CPU,首先是有程序,用编译器把它编译程二进制代码,这个二进制代码可以部署到真正的芯片硬件上,也可以部署到软件仿真器上,去做具体的计算效果、计算性能等实现。
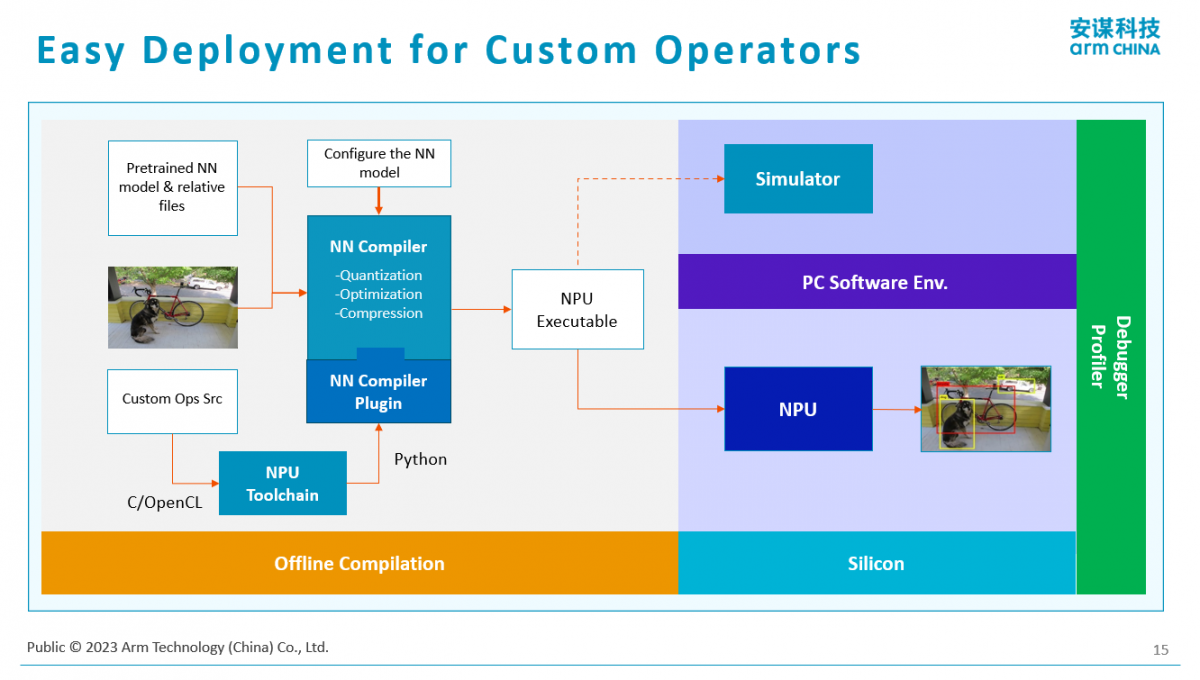
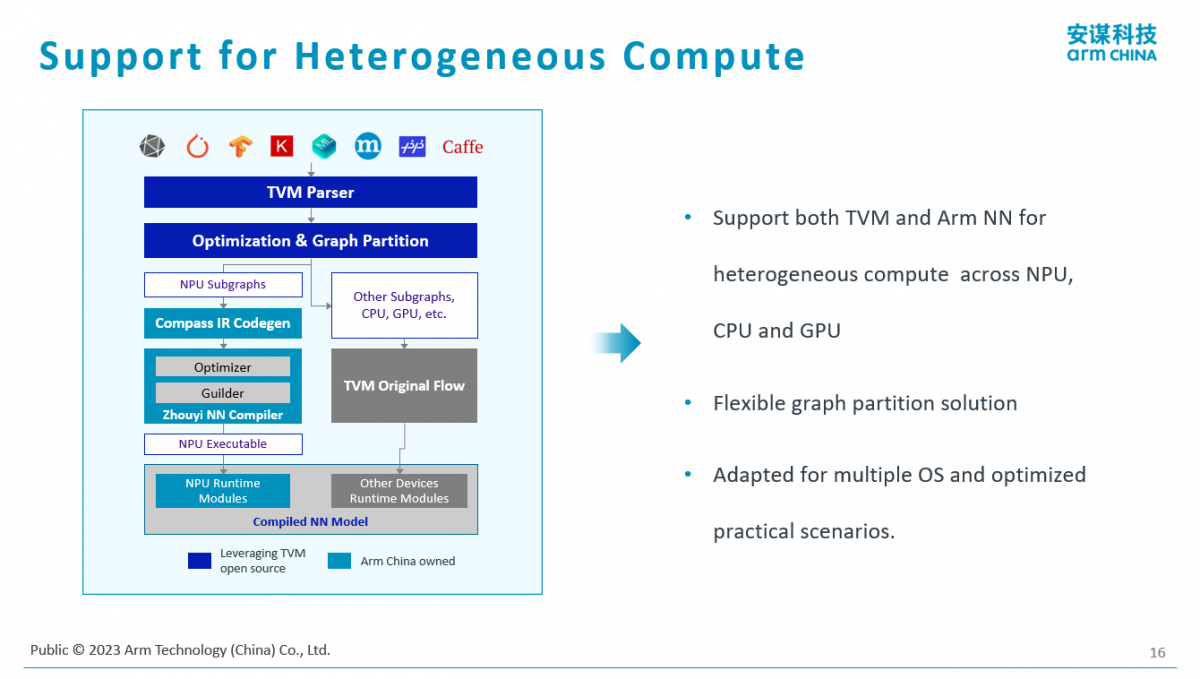
Arm不仅支持自己的一套软件工具,也支持开源的AI编译结构,比如TVM的框架。基于TVM的实现,它有个好处是能够比较好地支持异构计算。“当我们计算的平台当中有CPU、有GPU、有NPU,甚至是不同架构的CPU,我们都是可以通过这样开源的异构计算方案把它兜起来。”杨磊说。
最后,他表示,这一代X2产品已经准备好了。Arm的合作伙伴也很快会有基于这个方案的芯片面世。同时也很希望以后能在超高端的MCU领域上有所合作。
 最前沿的电子设计资讯
最前沿的电子设计资讯

