
上周二,AMD的高管在旧金山举行的一次活动中展示了他们对AI的愿景,包括新的数据中心CPU和GPU产品。他们展示了公司产品组合中几乎所有能够运行AI的产品,并推出一个又一个超大规模(hyperscale)的客户,以表明他们在超级计算机和超大规模领域取得的成功。但大家真正想知道的是:AMD的新GPU能否与竞争对手Nvidia(英伟达)的旗舰H100 GPU相抗衡?虽然它看起来在原始性能上击败了H100,但这就足够了吗?

AMD首席执行官Lisa Su(苏姿丰)展示了MI300X。(来源:AMD)
“人工智能是塑造下一代计算的决定性技术,”AMD首席执行官苏姿丰在活动中表示,“坦率地说,这是AMD最大、最具战略意义的增长机会。”
据报道,由于对ChatGPT等大语言模型(LLM)的训练和推理需求增加,目前H100供不应求,现在是宣布一个可靠的H100竞争对手的最佳时机。
AMD的数据中心GPU产品线包括之前宣布的MI300A,它将用于劳伦斯利弗莫尔国家实验室目前正在调试的2 ExaFLOP的El Capitan超级计算机。MI300A使用了13个小芯片,混合了CPU和GPU芯片,这是HPC(高性能计算)的一种流行的组合。
在AMD的活动中,苏姿丰发布了新MI300X的详细信息(MI300A的纯GPU版,将MI300A的三个CPU小芯片替换为两个GPU小芯片)。还增加了更多HBM内存和内存带宽,专门针对LLM和其他AI工作负载进行优化。GPU小芯片采用AMD的第三代CDNA 3架构,与MI250和早期产品相比,该架构具有新的计算引擎和对AI友好的数据格式。

AMD的12芯片组MI300X GPU直接与Nvidia的H100竞争。(来源:AMD)
总的来说,新的旗舰GPU有十几个5纳米和6纳米的小芯片,总共有1530亿个晶体管。它具有192GB HBM3内存和5.2TB/s内存带宽。相比之下,Nvidia的H100有一个带有80GB HBM2e的版本,总带宽为3.3TB/s。这让MI300X拥有2.4倍的HBM密度和1.6倍的HBM带宽。
“有了所有这些额外的容量,我们在更大的模型上就有了优势,因为你可以直接在内存中运行更大的模型,” 苏姿丰说,“对于最大的模型,这会减少您需要的GPU数量,加快了性能——尤其是推理——并降低了(总拥有成本,TCO)。”
换句话说,忘记“the more you buy, the more you save,”(根据Nvidia首席执行官黄仁勋2018年的演讲,大意为买的越多,省的越多),AMD表示,如果你愿意,你可以使用更少的GPU。总体效果是云服务提供商可以在每个GPU上运行更多的推理任务,降低LLM的成本,使其更容易被生态所接受。它还减少了部署所需的开发时间,苏姿丰说。
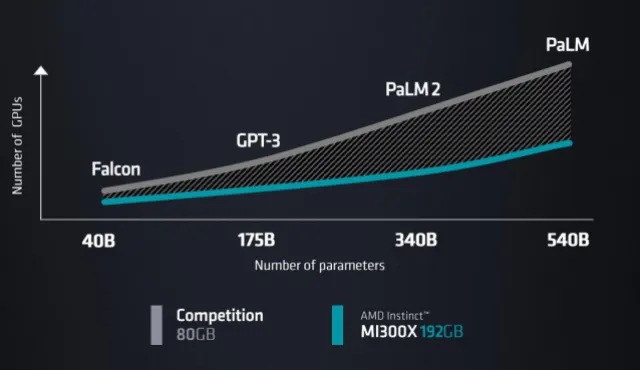
根据AMD的计算,与具有80GB内存(推测为Nvidia H100-80GB)的竞争对手GPU相比,各种LLM的FP16精度的推理需要更少的MI300X。Falcon-40B模型需要1个AMD的GPU或2个竞争对手的GPU。PaLM 540B模型需要7个AMD的GPU或15个竞争者的GPU。(来源:AMD)
AMD还展示了AMD Instinct平台,这是一个8xMI300X的系统(带有2个AMD Genoa主机CPU),类似于Nvidia的HGX-H100,采用OCP兼容格式。该系统旨在快速轻松地融入现有基础设施。它将在第三季度向主要客户提供样品。
Nvidia皇冠上的明珠是其成熟的AI和HPC软件栈CUDA。这通常被认为是AI芯片初创公司难以从它这一领导者手中夺取市场份额的关键原因之一。
“毫无疑问,软件对于使我们的硬件能够得到广泛部署非常重要,” 苏姿丰说,并承认软件是“a journey(一段旅程)”。
AMD的AI软件栈称为ROCm(“Rock-'em”),苏姿丰说去年取得了“巨大”进展。
AMD总裁Victor Peng表示,与Nvidia的CUDA相比,ROCm的“很大一部分”是开放的。开放部分包括驱动程序、语言、运行时刻、AMD的调试器和分析器等工具以及库。ROCm还支持开放框架、模型和工具,以及针对HPC和AI优化的内核。AMD一直在与PyTorch合作,以确保对PyTorch 2.0的零日支持,并测试PyTorch-ROCm堆栈是否能如约运作。
AMD还宣布了与HuggingFace的新合作。HuggingFace将为AMD Instinct加速器以及AMD边缘产品组合中的其他部分优化其数千个模型。
HuggingFace首席执行官Clem Delangue上台谈论人工智能的民主化和LLM。
“当人工智能发展时,硬件不要成为它的瓶颈或守门员,这一点非常重要,”他说,“我们正在努力做的是扩大人工智能建设者在训练和推理方面的选择范围。得益于(MI300X)的内存容量和带宽优势,我们对AMD为数据中心的LLM提供支持的能力感到非常兴奋。”
虽然MI300X看起来在原始性能上击败了H100,但Nvidia有一些技巧,包括“transformer engine”(转换器引擎),这是一种软件功能,可以对LLM进行混合精度训练以提高吞吐量。在软件方面,尽管AMD在ROCm上取得了进展,并做出了像OpenAI的Triton这样的努力,但Nvidia的CUDA仍然占据主导地位。软件成熟度一直是该领域初创企业面临的巨大挑战。
然后是时间问题。Nvidia H100现已上市(如果你能买到的话),但MI300X直到第四季度才会开始量产。Nvidia预计将在2024年推出其新一代GPU架构,这可能会让MI300X再次处于不利地位。这种节奏意味着AMD将永远跟随,而不是领先。
未来的AMD GPU可能会继续利用其小芯片技术,而尽管英伟达拥有Grace Hopper超级芯片等多芯片产品,但它尚未以同样的方式转向小芯片。
更早转向小芯片是否会对AMD有利?似乎不可避免的是,Nvidia最终将不得不转向小芯片(继英特尔和AMD之后),但这将在多长时间内发生仍不清楚。
MI300X是否足以从Nvidia手中夺取至少一部分数据中心AI市场份额?考虑到AMD在HPC和数据中心CPU方面的现有客户群,它看起来确实是这样——与初创公司相比,这是一个巨大的优势。
有一件事是肯定的:这个市场对两个玩家来说足够大。
(原文刊登于EDN姊妹网站EE Times,参考原文:Can AMD’s MI300X Take On Nvidia’s H100?,由Ricardo Xie编译。)
 最前沿的电子设计资讯
最前沿的电子设计资讯
