
在8月10日发表在《自然电子》杂志上的一篇题为《用于深度神经网络推理的基于相变存储器的64核混合信号内存计算芯片》的论文中,IBM研究人员表示,他们为最先进的混合信号人工智能芯片应用了一种新方法,该芯片在执行深度神经网络(dnn)的复杂计算方面表现出卓越的效率和准确性。

深度神经网络正在产生生成人工智能带来的许多令人兴奋的进展,但在传统的数字计算架构上执行神经网络的传统方法在性能和能效方面存在局限性,架构依赖于虚拟减速带的配置,从而确保无法获得最大效率。此外,这些系统由单独的存储和处理单元构成,对两个组件之间的通信系统资源有着巨大的需求,这导致了速度变慢和效率降低。
IBM研究公司想出了一个更好的主意,它转向了一个完美的模型,以获得更高效的数字大脑的灵感:人脑。
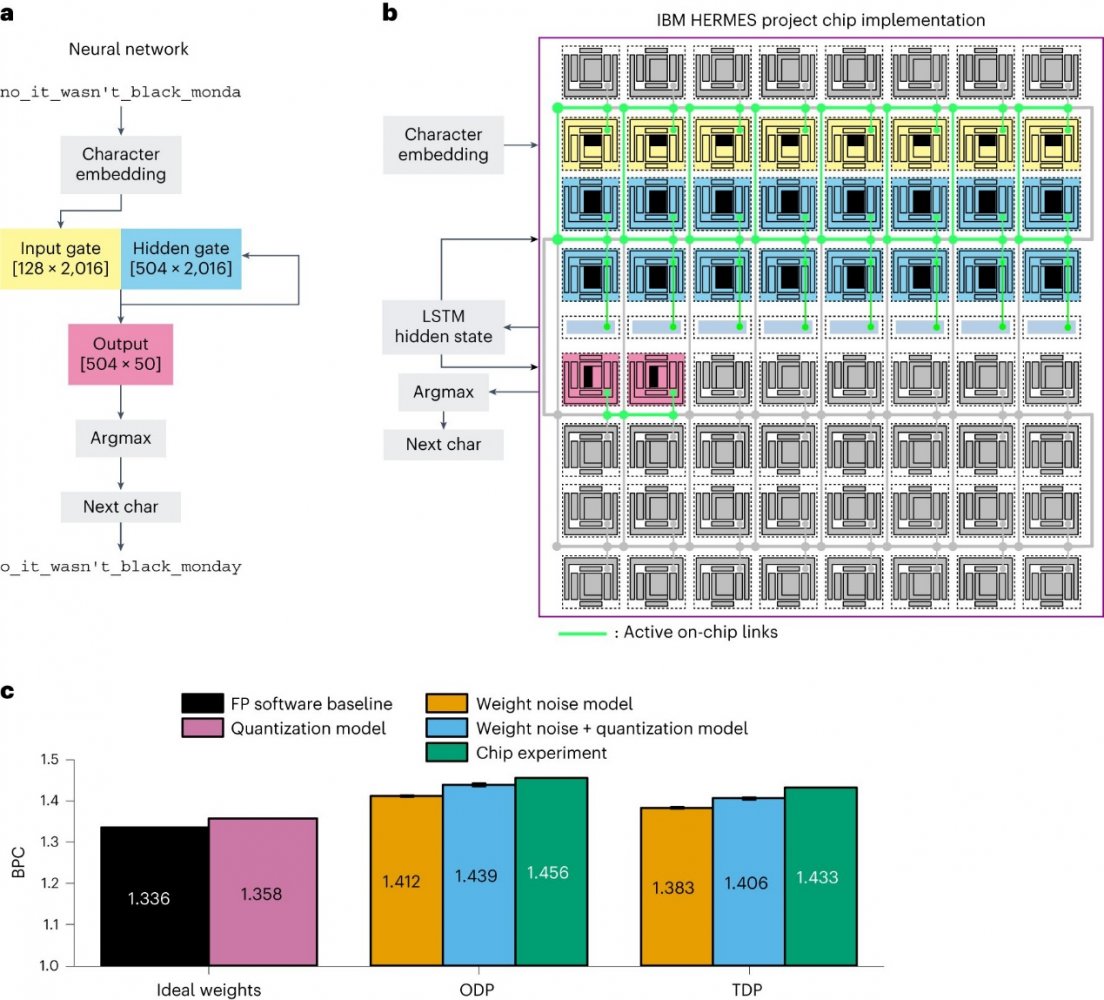
LSTM用于字符预测测量结果。图片来源:《自然电子》 (2023)。DOI:10.1038/s41928-023-01010-1
IBM的混合信号芯片以类似于突触在大脑中相互作用的方式工作,具有64个模拟内存核心,每个核心都有一系列突触细胞单元。转换器可确保模拟和数字状态之间的平稳转换。
根据IBM的数据,这些芯片在CIFAR-10数据集上的准确率为92.81%,CIFAR-10是一种广泛使用的用于机器学习训练的图像集合。
该研究的合著者之一、瑞士苏黎世 IBM 研究实验室的 Thanos Vasilopoulos说:“我们用ResNet和长短期记忆网络证明了接近软件等效的推理精度。ResNet,残差神经网络的缩写,是一种深度学习模型,可以在不影响性能的情况下在数千层神经网络上进行训练。
Vasilopoulos表示:“为了实现延迟和能耗的端到端改进,AIMC必须与片上数字操作和片上通信相结合。在这里,我们报道了一种采用14 nm互补金属-氧化物-半导体技术设计和制造的多核AIMC芯片,该芯片具有后端集成相变存储器。”
Vasilopoulos说:“随着性能的提高,可以在低功耗或电池受限的环境中执行更大、更复杂的工作负载。这将包括手机、汽车和相机。此外,云提供商将能够使用这些芯片来降低能源成本和碳足迹。”
IBM表示,随着数字电路的未来改进,允许在本地存储器中进行层到层的激活传输和中间激活存储,将允许在这些芯片上执行完全流水线化的端到端推理工作负载。
Vasilopoulos在他的个人博客上讨论了IBM的最新成就,他说:“通过这项工作,完全实现模拟人工智能的承诺所需的许多组件,即高性能和节能的人工智能,都经过了硅验证。”
 最前沿的电子设计资讯
最前沿的电子设计资讯
