
机器学习(ML)和人工智能(AI)技术,通常统称为AI技术,是现代投资最多的领域之一。据预测,在今后几年内,AI技术和功能将被集成到大量的边缘设备和自主系统中,基于云和生成式AI的服务也将不断增加。
然而,AI的蓬勃发展也并非完全一帆风顺。在许多方面,如大语言模型(LLM)、自然语言处理、语音识别、强化学习和其他系统背后的深度神经网络(DNN)技术都使用了大量的存储、内存和数据处理,来作为一种创造有效AI技术的捷径。
这里的前提是,与早期依赖数学上的效率和优化的ML/AI模型开发手段相比,可以使用更大的训练集和计算资源来更快地创建更准确、更有用的模型。OpenAI发布的一项分析报告显示,AI开发中使用的计算资源每3.4个月就会翻一番,而摩尔定律在计算能力方面的进步也只有每2年翻一番。因此,在某个时刻,计算能力的提高将无法满足当前AI训练和推理范式的需求。
为了保持竞争力并在边缘实现AI技术,这种方法需要做出折衷,以满足边缘系统的尺寸、重量、成本和能耗的要求。其中一些折衷包括降低数字AI模型中使用的数据的分辨率。此外,降低分辨率在节省AI能源和降低复杂性方面也存在实际限制。GPU已成为一种热门的选择,用于执行AI训练和推理任务所需的大型矩阵操作,因为GPU在执行大型矩阵计算方面比CPU更强大、更节能。
然而,对于基于冯·诺依曼结构的数字计算方法,这些系统的处理速度不可避免地在实际应用中存在限制。这是一种被称为冯·诺依曼瓶颈的现象,即处理速度受限于从内存到处理单元的数据传输速率。
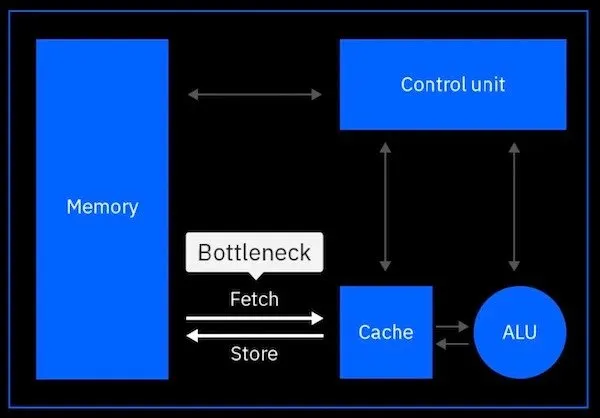
图1 显示了传统冯·诺依曼结构是怎么因为大量数据移动而成为瓶颈。资料来源:IBM
上述事实是IBM和其他AI技术公司如Mythic AI押注模拟AI作为未来边缘AI训练和推理的基础。有业内人士称,模拟AI技术的速度和效率可能比数字AI技术快数十至数百倍,这将使得能源受限的边缘设备的AI处理能力大幅提高。
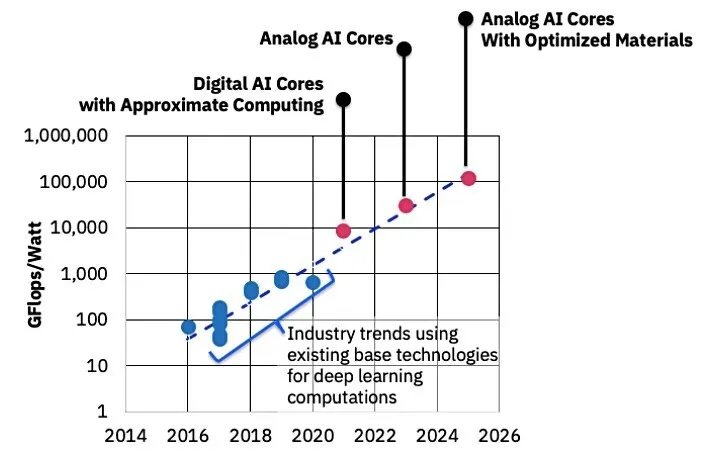
图2 该图比较了目前和未来几年的数字AI和模拟AI硬件技术及其每瓦性能,2014-2026。来源:IBM
数字处理技术依赖于封装为离散值的数据,每一比特都存储在指定的晶体管或存储单元中,而模拟处理技术可以利用存储在单个晶体管或存储单元中的连续信息。仅凭这一特点,模拟处理技术就能在更小的空间内存储更多的数据,但也会通过随机误差的引入牺牲存储数据的可变性。
模拟存储的可变性可能导致前向传播(推理)失配误差,以及反向传播(训练计算误差)。这两种情况都不可取,但可以使用数字电路和模拟电路来解决这种误差,以确保误差最小,还可以使用其他AI训练技术来减少反向传播误差。
对于人工神经网络(ANN),现在可以管理这种可变性。从历史上看,模拟存储的可变性是半个多世纪前数字计算技术最初取代模拟计算技术的原因,因为大多数计算系统都需要更高的精度。
用于ANN的模拟计算的其他优势包括乘法累加运算,这是ANN计算中最常见的运算,可以使用电动力学中的物理特性来完成,例如欧姆定律的乘法运算和基尔霍夫定律的累加运算。这样,模拟计算机就可以将输入作为数组进行处理,并行执行全矩阵运算。这比使用CPU甚至GPU进行矩阵计算更加快速高效。
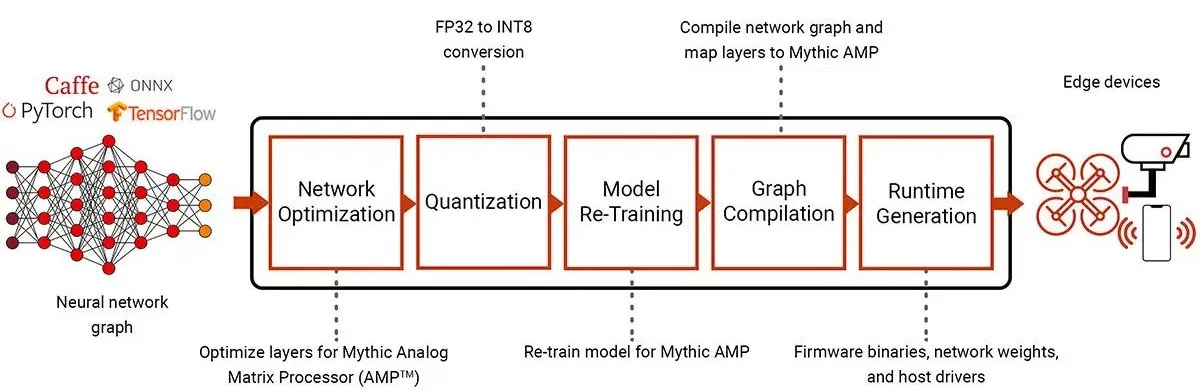
图3 使用模拟矩阵处理器部署围绕Pytorch、Caffe和TensorFlow等标准框架构建的AI工作流。来源:Mythic
模拟计算技术的另一个优势是,这些解决方案可以利用不同的存储单元技术,例如相变材料(PCM)和作为可变电阻器而不是开关运行的数字闪存。这些模拟存储方法允许在同一位置进行计算和存储,而不需要持续使用电力来维持数据存储。
这些因素意味着模拟计算/存储中不存在冯·诺依曼瓶颈,并且模拟数据存储本质上是被动的,长期耗能远远低于主动数字数据存储。例如,PCM的工作原理是材料的电导率是PCM存储单元内非晶态与晶态比率的函数。
对于IBM的PCM技术,较低的编程电流状态会导致较低的电阻和更多的晶体结构,而较高的编程电流则会产生电阻较高的非晶材料。这就是PCM数据存储相对非易失性的原因,也是ANN突触权重可以在单个PCM单元的电导上限和下限之间连续存储的原因,而不是在多个晶体管或其他数字存储单元上存储比特。
因此,对于能源/处理受限系统上的边缘计算推理和AI训练而言,模拟AI技术的出现不足为奇,因为这种解决方案可以带来DNN的优势,而无需访问广泛的云AI基础设施和互联网连接。这将带来响应速度更快、效率更高、能力更强的边缘AI,更适合机器人、全自动驾驶、安全工作甚至认知无线电/通信(Cognitive radio/communications)等自主应用。
(原文刊登于EDN姊妹网站Planet Analog,参考链接:What’s analog AI and what impact it will have,由Ricardo Xie编译。)
 最前沿的电子设计资讯
最前沿的电子设计资讯
