
据EDN电子技术设计报道,业内消息称NVIDIA计划为中国市场推出至少三款新的AI GPU,这三款新芯片被命名为H20、L20和L2。此前,国内媒体曾透露,这三款芯片为HGX H20、L20 PCle和L2 PCle,由H100改良而来。据称,这些芯片基于Hopper和Ada架构,最高理论性能可达296 TFLOP,适用于云端训练、云端推理以及边缘推理。
这些芯片的 GPU 配置的具体规格尚不清楚,但Hopper H20 SMX具有96 GB内存容量,运行速度高达4.0 Tb/s,计算能力为296 TFLOPs,使用GH100芯片,性能密度为2.9 TFLOPs/die,而H100为19.4。根据所列表格,H100 SXM比H20 SXM快6.68倍,但这是FP16张量核FLOPs(带稀疏性),而不是INT8或FP8 FLOPs。GPU的TDP为400瓦,在HGX解决方案中采用8路配置。它保留了900 GB/s NVLINK连接,还提供7路 MIG(多实例GPU功能。

L20 配备了 48 GB 内存和 239 TFLOPs 的峰值计算性能,而 L2 则配置了 24 GB 内存和 193 TFLOPs 的峰值计算能力。GPU 采用 PCIe 外形,是办公室工作站和服务器的可行解决方案。与中国客户之前购买的 H800 和 A800 相比,这些配置要精简得多,但对于其中一些客户来说,英伟达用于 AI 和 HPC 的软件栈似乎太有价值了,他们不愿意放弃,因此愿意降低规格,以获得这些现代的 Hopper 架构。
此外,虽然从传统的计算角度来看,H20 SXM 的性能有所下降,但报告指出,在 LLM 推断方面,H20 SXM 实际上会比 H100 更快,因为它与明年的 H200 有相似之处。这表明至少 GPU 的一部分与芯片的其他部分相比并没有被削减。英伟达 HGX H20 SXM 芯片和 L20 PCIe GPU 预计将于 2023 年 12 月上市,而 L2 PCIe 加速器将于 2024 年 1 月上市。产品出样将比发布提前一个月开始。
外媒SemiAnalysis表示:其中一款中国专用 GPU 的 LLM 推理速度比 H100 快 20% 以上,与 Nvidia 明年初推出的新 GPU 更为相似,而不是 H100!
知情人士称,与英伟达之前在中国销售的专供芯片(A800、H800)相比,这些芯片的整体性能有所下降。
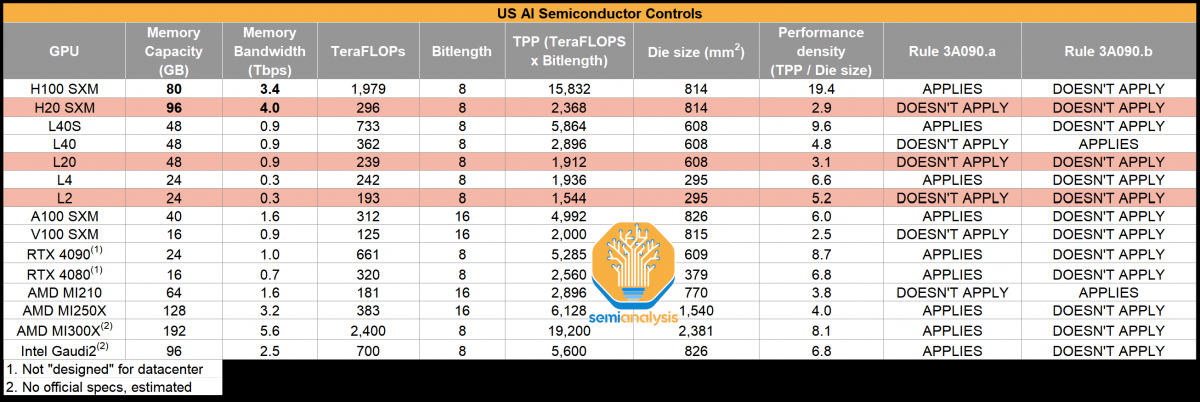
英伟达HGX H20、L20、L2与其他产品的性能参数对比
众所周知,H100/H800是目前算力集群的主流实践方案。其中,H100理论极限在5万张卡集群,最多达到10万P算力;H800最大实践集群在2万-3万张卡,共计4万P算力;A100最大实践集群为1.6万张卡,最多为9600P算力。
然而,如今新的H20芯片,理论极限在5万张卡集群,但每张卡算力为0.148P,共计近为7400P算力,低于H100/H800、A100。因此,H20集群规模远达不到H100的理论规模,基于算力与通信均衡度预估,合理的整体算力中位数为3000P左右,需增加更多成本、扩展更多算力才能完成千亿级参数模型训练。
知情人士透露,英伟达新款定制芯片的制造工艺不像A800和H800那么复杂。SemiAnalysis分析师表示“阉割”的原因在于:“英伟达的这些新芯片完美兼顾了峰值性能和性能密度的界限,使得它们能够遵守美国的新规定。”
目前,英伟达已经将芯片样品寄给客户进行测试,这表明该公司预计很快就会开始大规模生产。根据国内媒体稍早前透露的消息,英伟达最快或将于本月16号之后公布新款芯片,国内厂商最快将在这几天拿到产品。
 最前沿的电子设计资讯
最前沿的电子设计资讯
