
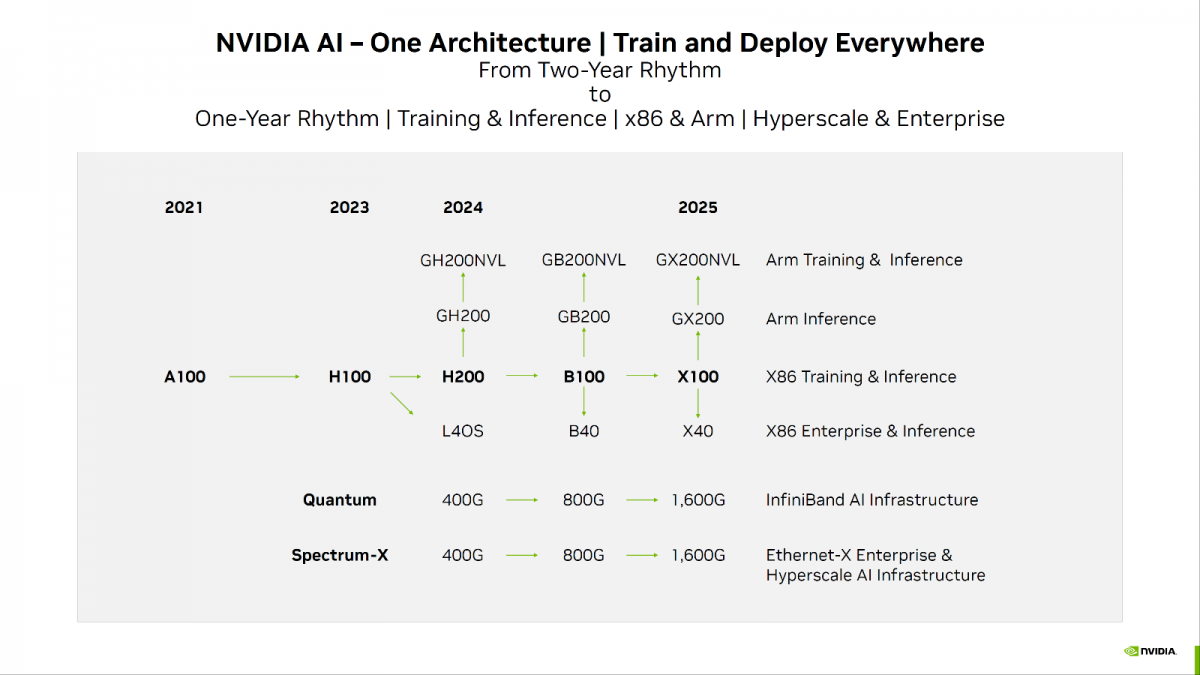
据EDN电子技术设计报道,NVIDIA宣布推出全新 H200 Hopper GPU,是目前用于训练最先进的大型语言模型H100芯片的升级版,据介绍,在执行推理或生成问题答案时,H200的性能比H100提升了60%至90%。
除了新的人工智能平台之外,NVIDIA 还宣布凭借 Grace Hopper 超级芯片赢得超级计算机重大胜利,该芯片现已为 Exaflop Jupiter 超级计算机提供动力。
据了解,H200基于“Hopper”架构,是该公司首款采用HBM3e内存的芯片,能够以每秒4.8TB的速度提供141GB的容量,相比于A100,其容量几乎翻了一倍,带宽提高了2.4倍。

在 Llama 2(700 亿参数 LLM)等应用中,这种新的内存解决方案使 NVIDIA 的 AI 推理性能比 H100 GPU 提高了近一倍。
在解决方案方面,NVIDIA H200 GPU 将广泛应用于具有 4 路和 8 路 GPU 配置的 HGX H200 服务器中。HGX 系统中 H200 GPU 的 8 路配置将提供高达 32 PetaFLOP 的 FP8 计算性能和 1.1 TB 的内存容量。
GPU还将与现有的HGX H100系统兼容,使客户能够更轻松地升级其平台。华硕、华擎 Rack、戴尔、Eviden、技嘉、慧与、鸿毅科技、联想、QCT、纬颖科技、超微和纬创等 NVIDIA 合作伙伴将在 H200 GPU 于 2024 年第二季度上市时提供更新的解决方案。
预计H200将于2024年第二季度上市,届时将与AMD的MI300X GPU展开竞争。与H200相似,AMD的新芯片相比前代产品拥有更多内存,这对运行大型语言模型的推理计算有帮助。
英伟达还表示,H200将与H100兼容,这意味着那些已经在使用H100进行训练的AI公司无需更改他们的服务器系统或软件即可适应H200。
此外,据美国金融机构Raymond James透露,H100芯片的成本仅为3320美元,但英伟达对其客户的批量价格却高达2.5万至4万美元。这使得H100的利润率可能高达1000%,成为有史以来最赚钱的芯片之一。
除了发布 H200 GPU 之外,NVIDIA还宣布了一项由其 Grace Hopper 超级芯片(GH200)驱动的大型超级计算机项目。

这台超级计算机被称为"木星"(Jupiter),位于德国尤利希研究中心(Forschungszentrum Jülich),是欧洲高性能计算联合项目(EuroHPC Joint Undertaking)的一部分,由 Eviden 和 ParTec 公司承包。这台超级计算机将用于材料科学、气候研究、药物发现等领域。这也是英伟达于11月发布的第二台超级计算机,上一台是Isambard-AI,可提供高达21 Exaflops的人工智能性能。
配置方面,Jupiter超级计算机基于Eviden的BullSequana XH3000,采用全液冷架构。它拥有总共 24,000 个 NVIDIA GH200 Grace Hopper 超级芯片,这些芯片通过该公司的 Quantum-2 Infiniband 互连。考虑到每个 Grace CPU 包含 288 个 Neoverse 核心,我们认为仅 Jupiter 的 CPU 端就有近 700 万个 ARM 核心(准确地说是 6,912,000 个)。
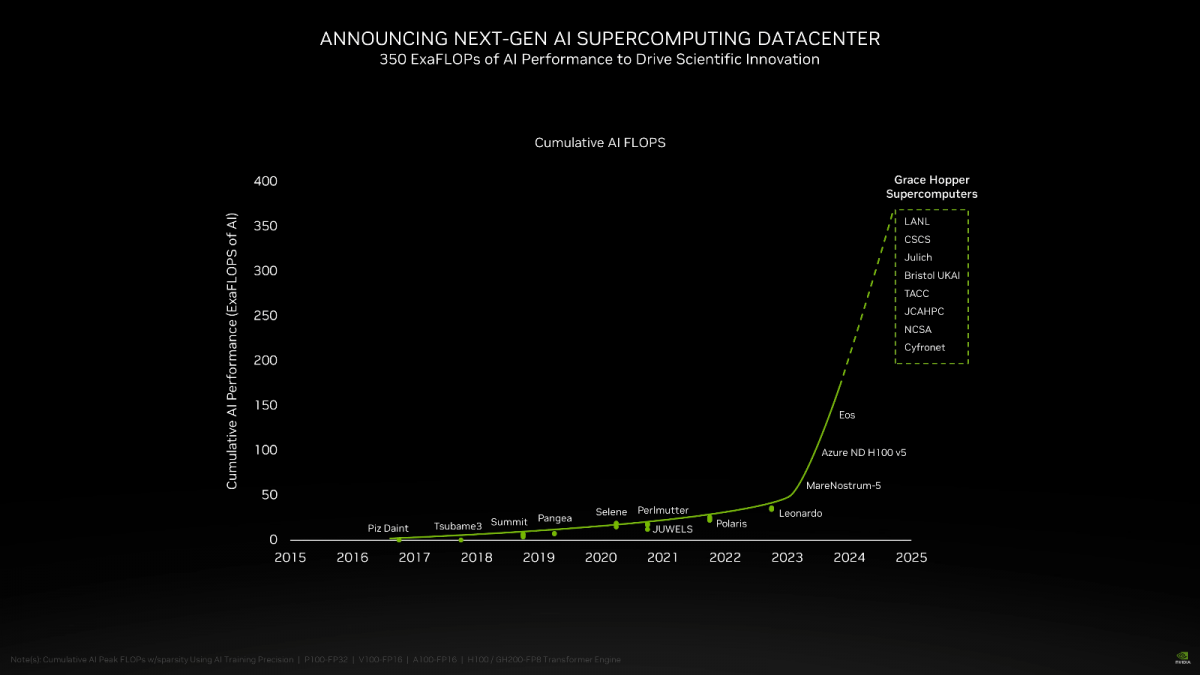
性能指标包括 90 Exaflops 的人工智能训练和 1 Exaflops 的高性能计算。该超级计算机预计将于 2024 年安装。总体而言,这些是 NVIDIA 凭借强大的硬件和软件技术继续引领 AI 世界的一些重大更新。
 最前沿的电子设计资讯
最前沿的电子设计资讯
