
最近的一则新闻把一个原本在学术界的词汇——“后摩尔”拉升到了公众视野。
什么是“后摩尔”?为什么“后摩尔”要提升到国家战略程度?“后摩尔”技术包含哪些?本期矽说小编就来谈一谈我眼中的后摩尔,因为一直欠着大家一篇ISSCC 2021的review,正好有机会借着这个话题来一起讨论下。
历史上的摩尔定律,一般分为两个阶段,第一个阶段是从Gordon Moore提出摩尔定律开始,到2000年前后,这个阶段一般称为 Full Scaling或者恒定电场微缩阶段,这个阶段的摩尔定律是温馨且甜蜜的童话,所有的性能指标都微缩,单位面积上的发热量保持不变。
PPA(Power/Performance/Area),无论哪个都在有条不紊提升。
也正是这个时期开始,芯片厂商们意识到,押注摩尔定律稳赚不赔,就像投资北上广深的房价。
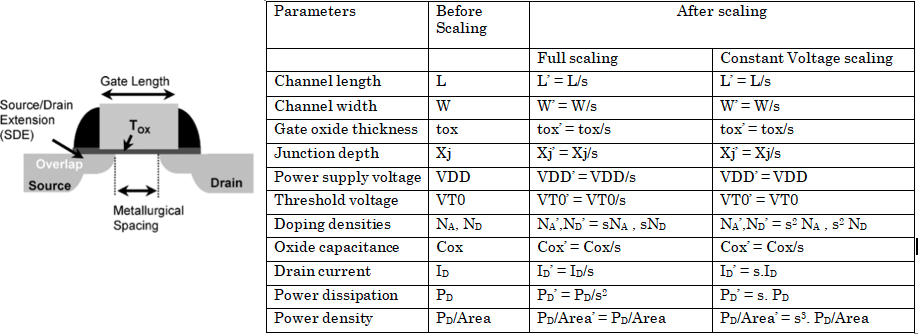
然而好景不长,由于晶体管的阈值电压在到100nm以后几乎无法下降,Full scale的摩尔定律遇到了阻碍。
于是一种新的摩尔定律产生——我们一般称为恒定电压微缩。
虽然尺寸还在变小,速度还在变快,但是恒定电压微缩下,单位面积下的发热量是随微缩节点平方率上升。
换言之,这样的摩尔定律一定带来芯片发热的爆炸。如果我们芯片充分利用微缩带来益处,小小芯片很可能其发热密度能赶上核电站甚至是火箭推进器。
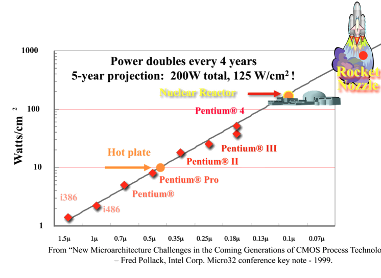
问题来了,20nm以下的工艺发展,且不论能否造出来,假设CMOS器件制造无碍,能否继续享受摩尔定律器件微缩带来的芯片性能的上升红利?
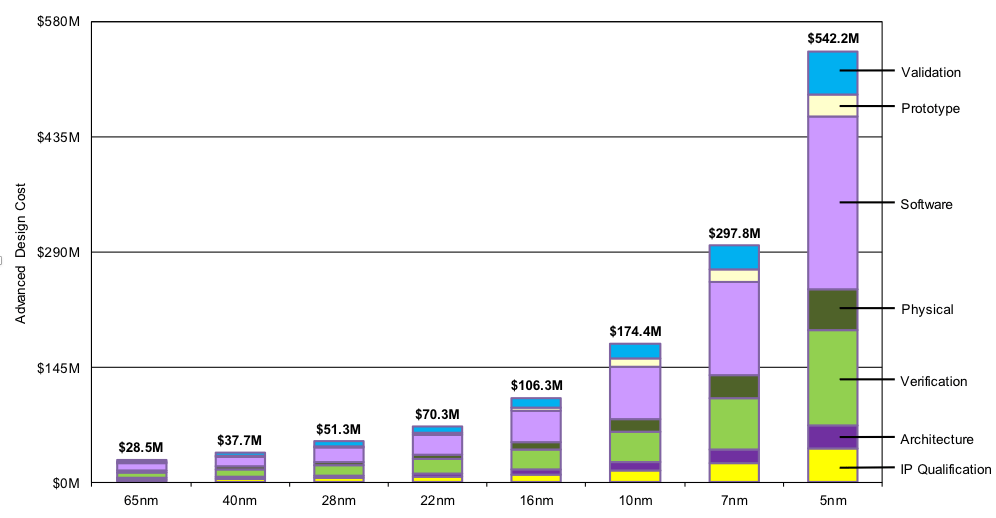
由于发热宛如小火炉现象,实际摩尔定律发展边际效应已然递减。而且,更现实的问题是设计成本。
20nm以下的工艺采用FinFET/GAA等立体结构,无论数字还是模拟电路,设计难度指数级上升,设计成本更是让一般的芯片公司望洋兴叹。
一颗5nm SoC的设计成本是28nm的10倍之多。相比之下,带来性能跃迁只有2、3倍。从经济的角度,除了少部分出货量超过100KK的芯片,大部分芯片的微缩已经停滞在了28nm节点上下。
当然,这种停滞还可能源于某些国际政治的因素。比如某西方大国不让我们的某实力大厂在某岛的代工厂上流14nm以下的工艺等。还有就是,2nm以下的芯片能不能造出来,大家也没啥谱。毕竟已经是十几个原子的事情了,现在基于量子力学的半导体物理理论管不管用还两说呢。
 总而言之,所谓“后摩尔”指的就是当摩尔定律对于大部分芯片设计公司来说已经停滞时,有没有什么颠覆性技术可以让芯片在没有尺寸微缩的前提下继续保持PPA的提升。
总而言之,所谓“后摩尔”指的就是当摩尔定律对于大部分芯片设计公司来说已经停滞时,有没有什么颠覆性技术可以让芯片在没有尺寸微缩的前提下继续保持PPA的提升。
简单而言,可以从器件、架构、集成方法的角度来讨论后摩尔的关键技术。
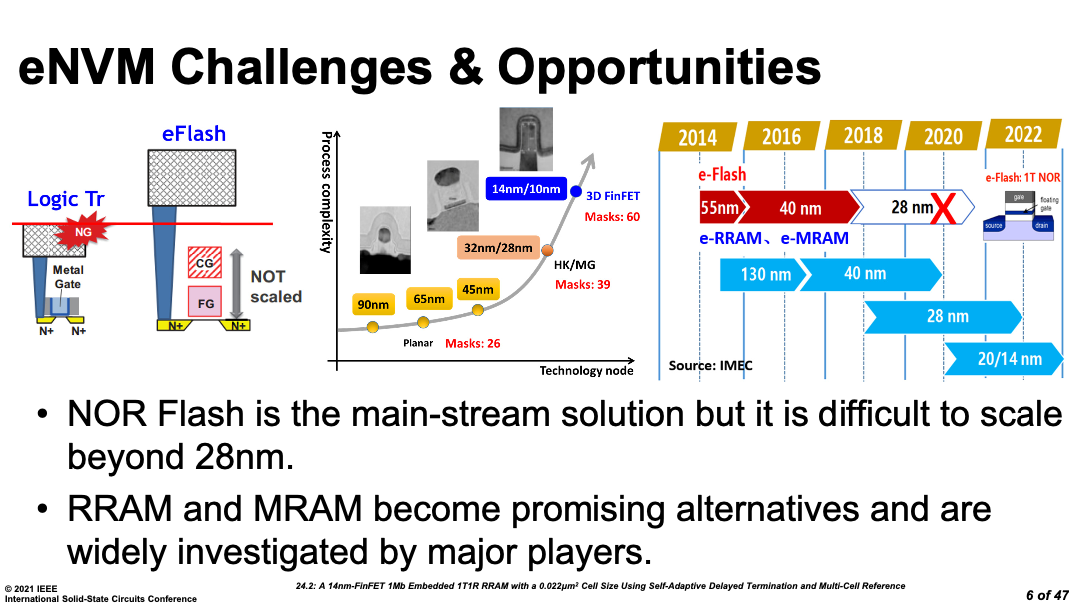
既然CMOS器件在先进节点已经如此挣扎,那“后摩尔”时期,是否可以找一些能和CMOS工艺的兼容的新器件代替传统的MOS器件呢?这一想法的率先在存储器中完成落地。
ISSCC 2021中,中科院微电子所在14nm FinFET工艺节点上,用忆阻器实现的阻变RAM(ReRAM)代替了传统的基于Flash 浮栅MOS管。
在CMOS兼容的工艺里,采用新原理器件实现了FinFet工艺的非易失存储。
相比之下,Flash工艺在28nm,甚至40nm就已经达到了工艺微缩的极限。
不仅用于存储,由于ReRAM的器件具有电阻特性,与电流、电压可通过欧姆定律、基尔霍夫定律实现乘和累加的物理关系,因此可被广泛用于并行模拟计算电路中,这种电路也被称为存算一体。
ISSCC 2021中,台湾清华大学通过数模混合的计算电路,首次基于ReRAM的实现8位的存算一体电路,且能效保持在11TOPS/W。
其电路模块结构如下所示:
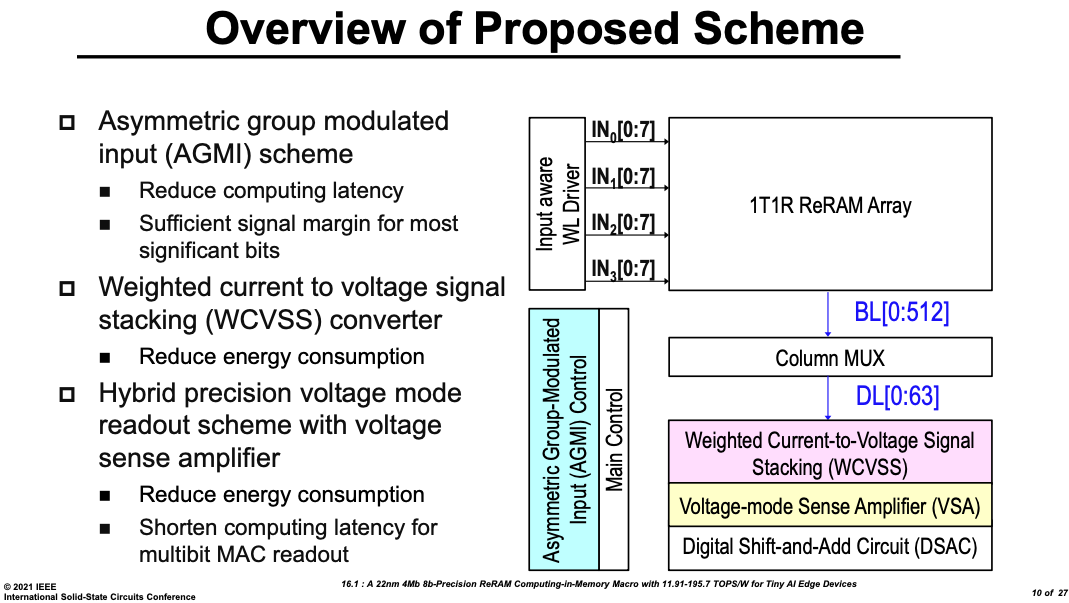
除了器件本身,“后摩尔”的另一潜力的来源是其专用性。
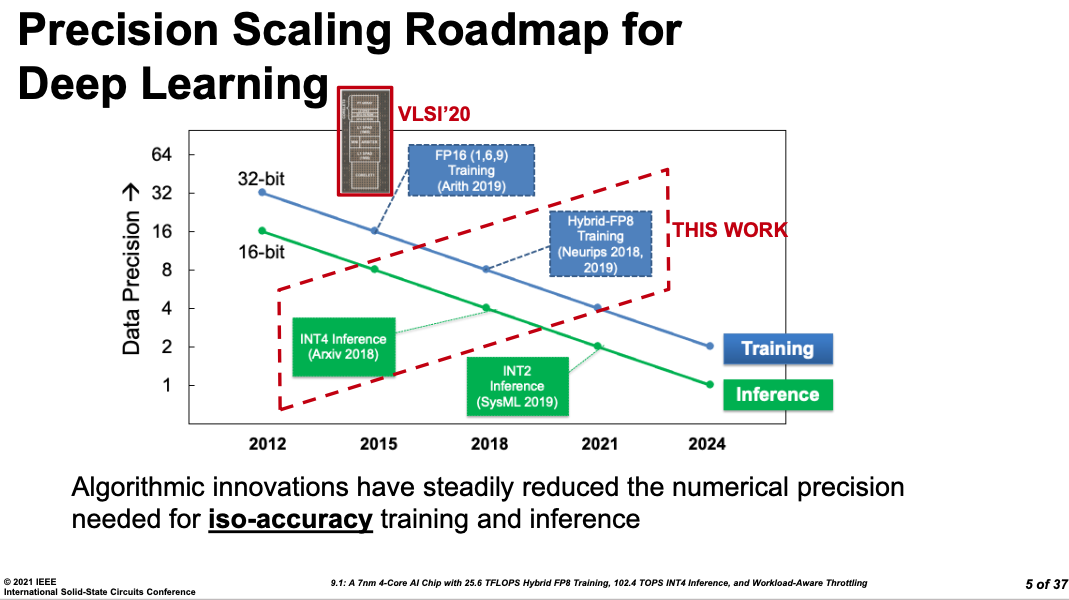
传统的通用电路性能饱和,所以这两年“领域专用”的设计如火如荼。ISSCC自然也不能缺席。特别是在人工智能芯片领域。目前AI算法发展速度是每3.4个月算力翻倍,而摩尔定律最快也得1.5年单位面积上的尺寸翻倍。
若要能稍稍赶上这一发展速度,就得联合算法寻找新的契机。
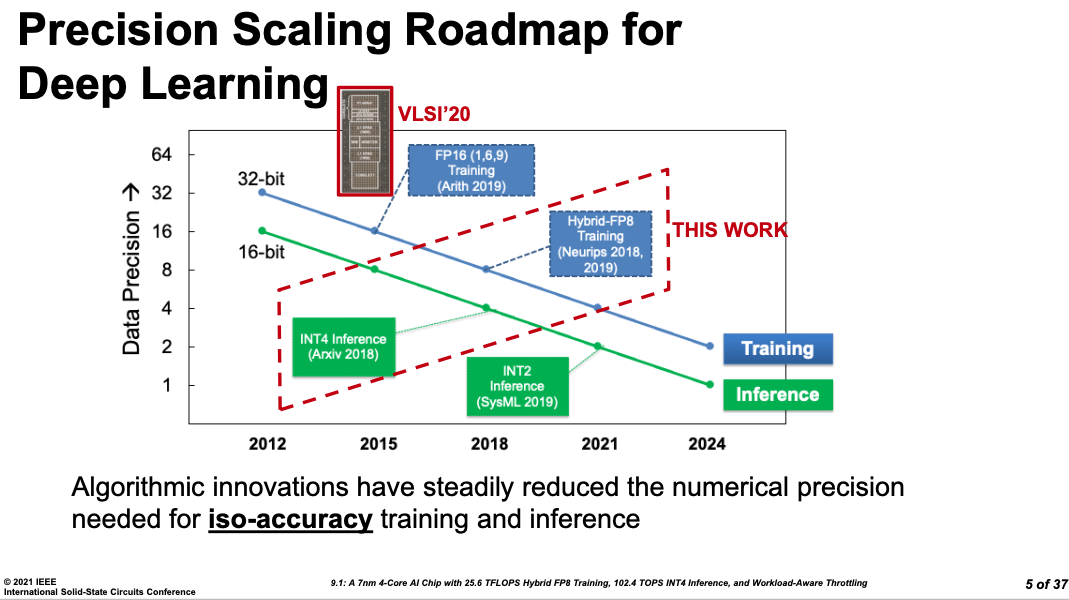
在ISSCC的AI芯片Session中,几乎所有芯片设计都紧紧拥抱了算法,基于协同设计催化出更好的性能。
例如,IBM提出的基于混合8位浮点的AI训练芯片。通过自定义FP8的数据格式,完成训练。精度上,和标准32位浮点的训练精度相差不超过1%,同时功耗又能保持在3TOPS/W以上,避免GPU百瓦级的耗电与发热。
还有清华大学在ISSCC 2021报告的两篇存算一体SoC的论文。
第一篇通过利用传统Cache一致性机制中的Set Associative技术,存算一体系统芯片中的再发明,完成了对稀疏输入的高效读写与计算,用更小的硬件代价完成更大规模的计算。
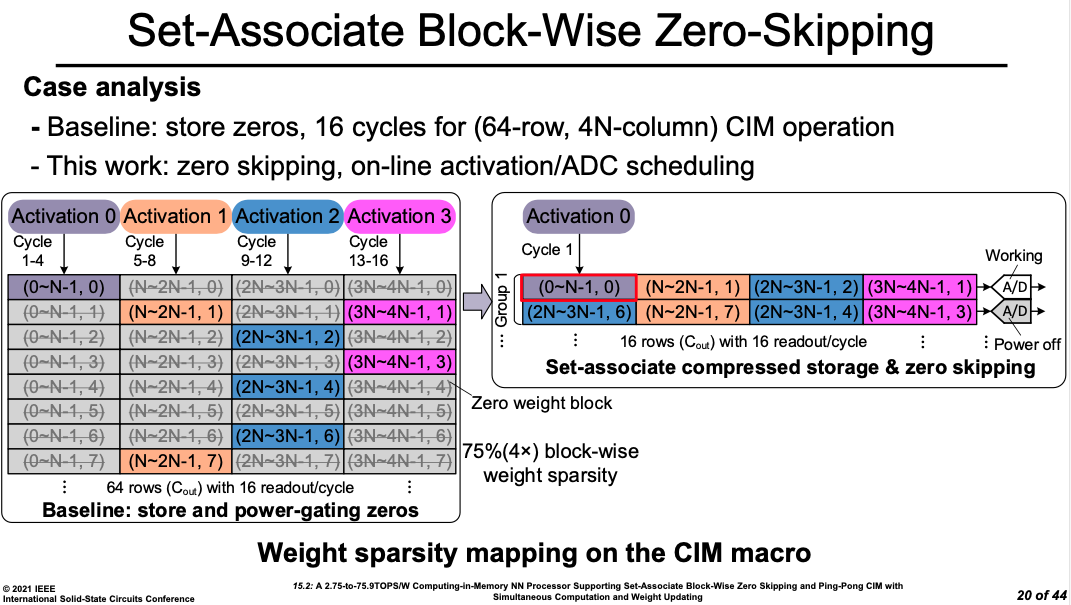
第二篇通过利用In-tensor decomposition train算法将最占据存储空间的神经网络权重最大的三维卷积核 分解为多个小向量的乘积,通过仅存储这些小向量的方式,结合量化和稀疏性优化实现高性能片上存储空间。
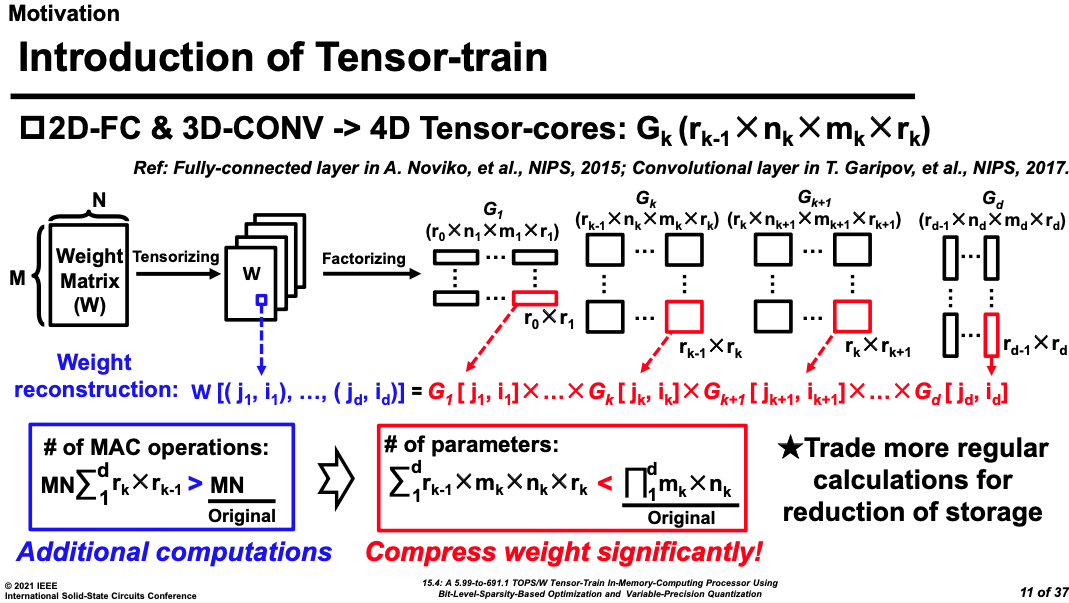
可见,上述方法的性能提升及其背后的新架构探索,都不适用于通用计算,但是通过算法与电路的更紧密结合,突破目前“摩尔时期”通用模块的性能瓶颈的效果显著。
摩尔定律的“初心”判断标准是单位面积上的晶体管数量的增长速度。
在过去的很多年里,摩尔定律关心的都是二维平面上CMOS器件的尺寸微缩。但在后摩尔时代,如果二维的增长饱和了,为什么不考虑三维呢?ISSCC 2021上有多篇从3D视角切入的芯片可以提供讨论。
首先是来自Sony的智能CIS传感芯片。由于人工智能应用的兴起,进传感器侧的AI芯片一直是CIS领域的热门话题。
Sony通过三维封装与Cu-Cu互联,将一个CMOS图像传感器阵列与模拟前端、AI芯片集成在一个封装内。利用Cu-Cu互联高带宽避免了额外的传感器与处理器数据通信瓶颈。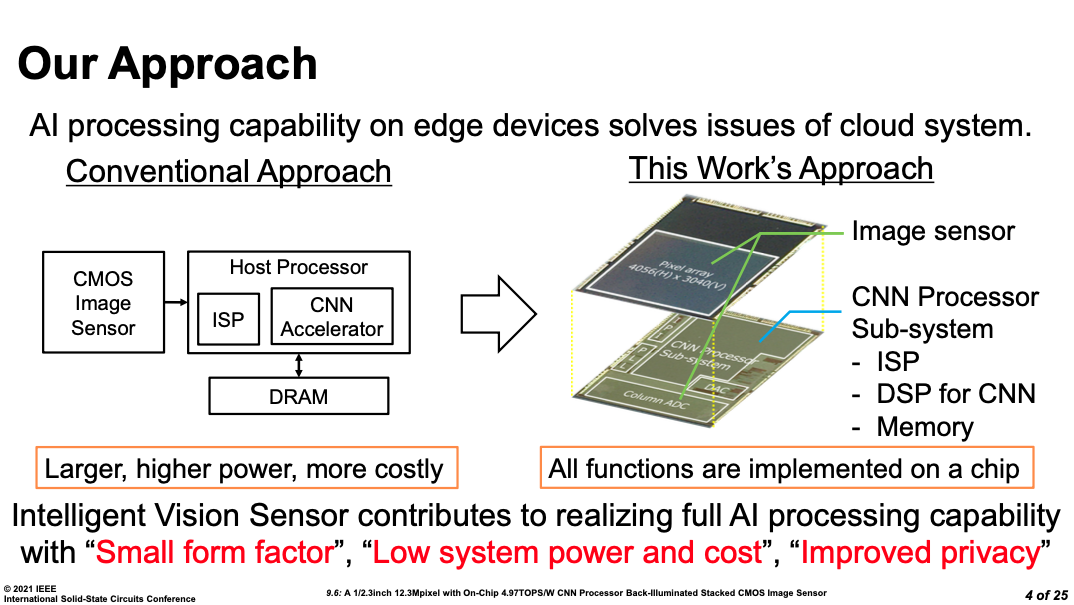
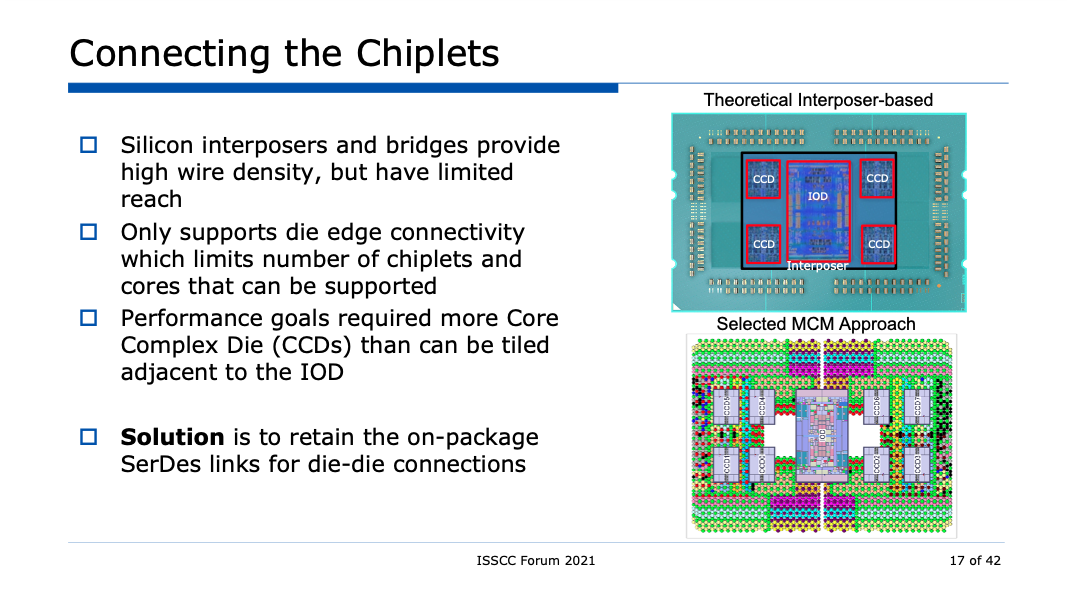
此外,三维封装的另一个火热话题是Chiplet。虽然ISSCC 2021的论文中未有太多的Chiplet paper,但是在forum上,也披露了不少已发表的Chiplet高性能处理器的设计细节。
比如AMD 二代EPYC架构服务器处理器芯片中基于Chiplet、无源连接基板和有源硅互联芯片的协同设计方法,阐述了其从芯片级到板级到系统级的考虑。
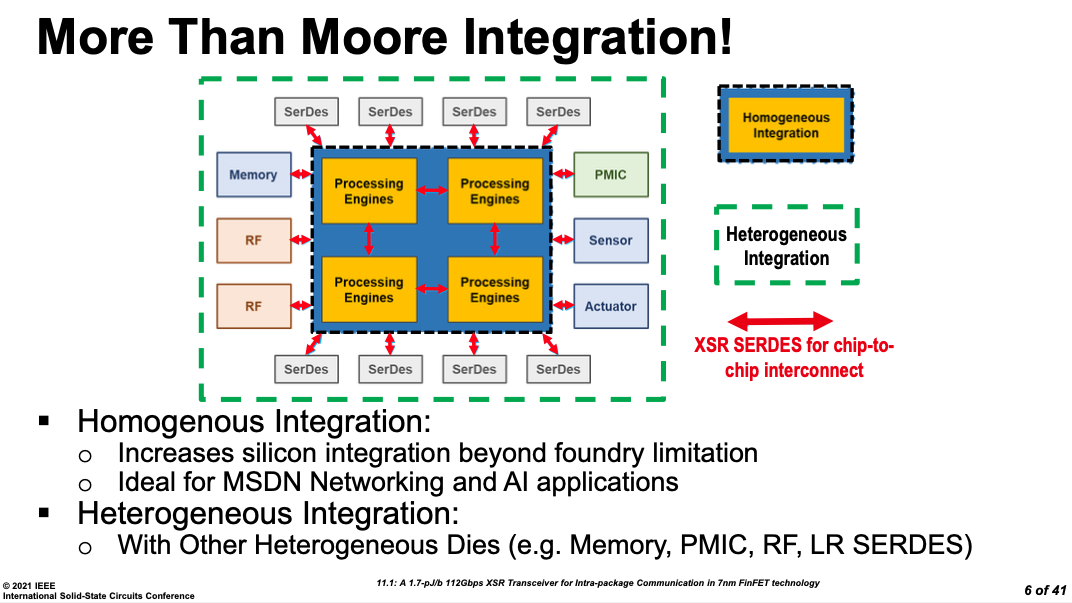
还有Nvidia的Chiplet多AI加速器MCM集成芯片,进一步讨论了其互联与软件部署算法的系统设计考虑。这种场景下,芯片的设计视角需要跳脱单芯片的局部优化,而走向超大规模算力集成下的软硬件协同优化。
有可能,我们即将来到一个3D封装重新定义单芯片的新格局。

在这一背景下,大厂们也开始积极布局面向Die-to-Die的互联电路,Wireline session中Samsung、Cadence都有高性能片间互联的新电路设计。但目前为止,还是经典的Serdes的高能效设计,能否有颠覆性技术出现让我们拭目以待。
其实还有很多ISSCC 的好paper难以穷举,你眼中的后摩尔技术还有什么呢?
(本文授权转载自公众号矽说,版权归矽说所有,转载请联系矽说)责编:胡安
 最前沿的电子设计资讯
最前沿的电子设计资讯
