
2022年6月29日,在AspenCore举办的“2022国际AIoT生态发展大会”上,英特尔公司高级首席工程师、物联网事业部中国区首席技术官张宇博士通过视频方式分享了“边缘AI技术发展趋势与展望”主题演讲。
张宇认为,物联网的发展会经历互联、智能、自主三个阶段。这也就好比物联网领域的摩尔定律,“虽然物联网是一个碎片化的市场,包含着众多的行业,但是其发展也将遵循着这三个规律。”张宇表示。
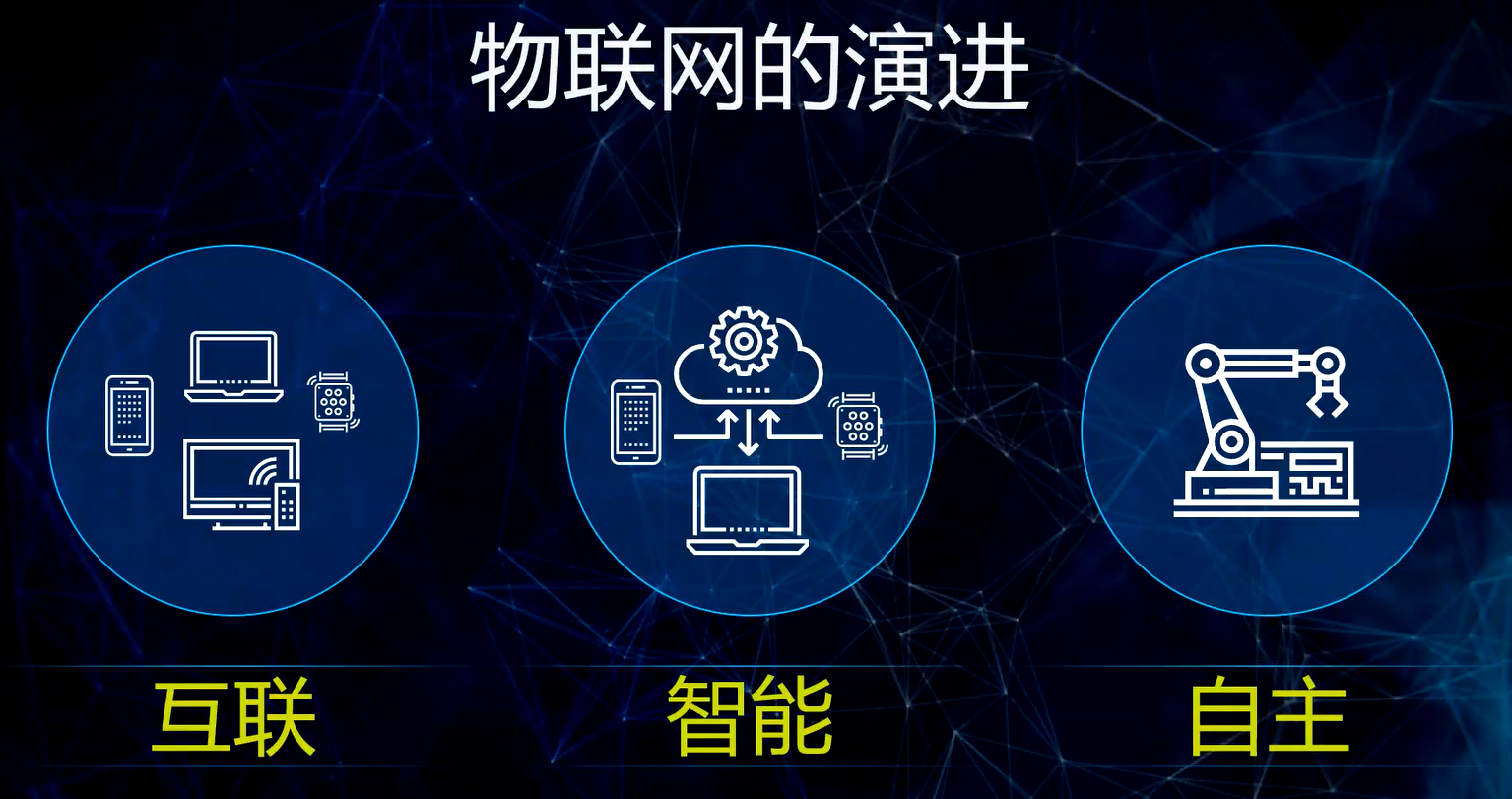
这三个阶段的第一个阶段是物物互联阶段。“我们之前谈感知中国,首先需要将数据从传感器通过各种有线或无线通信手段,比如Wi-Fi、蓝牙、NB-IoT、5G等,将数据传到数据中心或边缘计算节点进行汇总和处理。这将是物联网发展的初级阶段,也是进一步发展的基础。”张宇指出。
第二个阶段是智能化的系统阶段。在这个阶段,收集起来的数据将会根据预先设定的规则进行过滤。在发现异常的时候,能够产生及时的告警。比如在零售领域,智能货柜已经能够感知当前存放的商品的数量。当商品的数量低于一定阈值的时候,可以自动地去通知后台进行配货。
第三个阶段将是自主系统阶段。在这个阶段,人工智能的技术将被广泛地使用,整个物联网系统将能够根据使用者的意图实现自主化的管理。人将更多地去从事监督管理的工作,工作的负荷会极大地降低。比如汽车的自动驾驶、工业4.0中的无人工厂,这些都是自主系统的典范。“当下新冠疫情深刻影响了我们生活与工作的方式。我们注意到,在欧美已出现了劳动力短缺、供应链紧张等问题,所以他们对于利用自主系统来取代人工的需求越发的迫切。自主系统将会以软件为基础,软件定义的数字基础架构将成为今后的主流。软件定义将出现在数字基础设施的各个领域,不仅仅出现在边缘设备,也会出现在从接入网到核心网的各个节点。”张宇认为。
“在边缘设备中,随着芯片在计算、通信与存储能力方面不断地提高,边缘设备有了更多的能力来承载更多的负载。再加上像虚拟化与云原生技术的普及,使得传统单一功能的边缘设备正在被能够同时承载多个应用,甚至于不同操作系统应用的边缘设备所取代,我们称之为是负载整合。通过软件定义的方式,边缘服务提供商可以灵活地调整边缘设备所运行的负载,继而去构建边缘即服务(EaaS)等新的商业模式。”
“在接入侧,随着5G技术的普及,我们拥有了更高的带宽,但是如何有效地管理这些带宽是我们当下需要考虑的问题。服务提供商希望能够根据应用对于服务质量的要求以及用户的级别来实现这种差异化服务,而这些要求往往是动态变化的,因此也只有通过软件定义的方式才能够满足服务对个性化配置的要求。”
“在核心网,传统的核心路由器与交换机是基于专有的芯片进行实现的,灵活度相对较差。随着用户对于差异化服务的要求越来越高,利用这种可编程的芯片来实现软件定义的核心网络已经成为业界的趋势。比如,我们国家正在构建的未来网络试验设施(CENI),它的核心就是建设以软件定义为基础的服务定制化的网络。”
从物联网的演进规律可以看到,人工智能技术在智能与自主阶段将发挥越来越大的作用。那么,人工智能尤其是边缘人工智能又将如何发展呢?首先,可以看到,在整个人类历史的发展过程中,已经经历了好几次人工智能的高潮(现在这个高潮并不是第一次)。本次人工智能高潮的起点是2012年,当时一个标志性的事件是一个叫Alex Krizhevsky的学生,设计了一个被称为AlexNet的深度卷积神经网络,并且将这个网络运用于ImageNet分类大赛,取得了冠军,而且其准确度远远超过了以往冠军的准确度。在这之后,以深度卷积神经网络为代表的深度学习技术被广泛地应用到了各个领域,比如交通领域的车号识别、零售领域的刷脸支付以及自然语言处理等等。其中,利用深度学习进行图像处理是当下应用得最为广泛的人工智能的应用,包括之前围棋领域的Alpha Go,它也是将围棋的布局当作一个19×19的图像,利用卷积神经网络对这个图像进行处理,来得到下一步行棋的策略。
但是,卷积神经网络是不是推动本轮人工智能发展最关键的技术呢?张宇认为,答案是否定的,因为在上世纪90年代,在上次人工智能发展高潮的时候已经有人开始尝试使用这一技术。在上世纪90年代,贝尔实验室的研究人员Yann Lecun就发明了一个卷积神经网络,被称为LeNet,用于识别支票上的字符。Yann目前是Meta的首席AI科学家,也是2018年度的图灵奖得主。因此,卷积神经网络并不是一种新的技术。张宇认为,推动本次人工智能发展的关键要素主要有两个:一个是大量可供训练的数据,另外一个是我们所拥有的算力得到了极大的提升。
首先,让我们看一组算力的数据。我们知道,最能体现人类计算能力的领域就是超算,每年全球超级计算机500强榜单颁布的时候都会引起人们广泛的关注。这个榜单的第一次颁布是在1994年,当时排名首位的超级计算机每秒钟浮点运算的峰值速度达到了131Gigaflop/s。而在最新一期(今年5月底6月初颁布的)榜单上,人类第一次跨越了百亿亿次的计算门槛,达到了1.10Exaflop/s的能力。这一数字已经是上世纪90年代超算的800多万倍了,所以在摩尔定律的推动下,我们所拥有的算力得到了极大的提升。算力的提升可以使我们更快地得到处理的结果,或者实现更加复杂的算法模型。
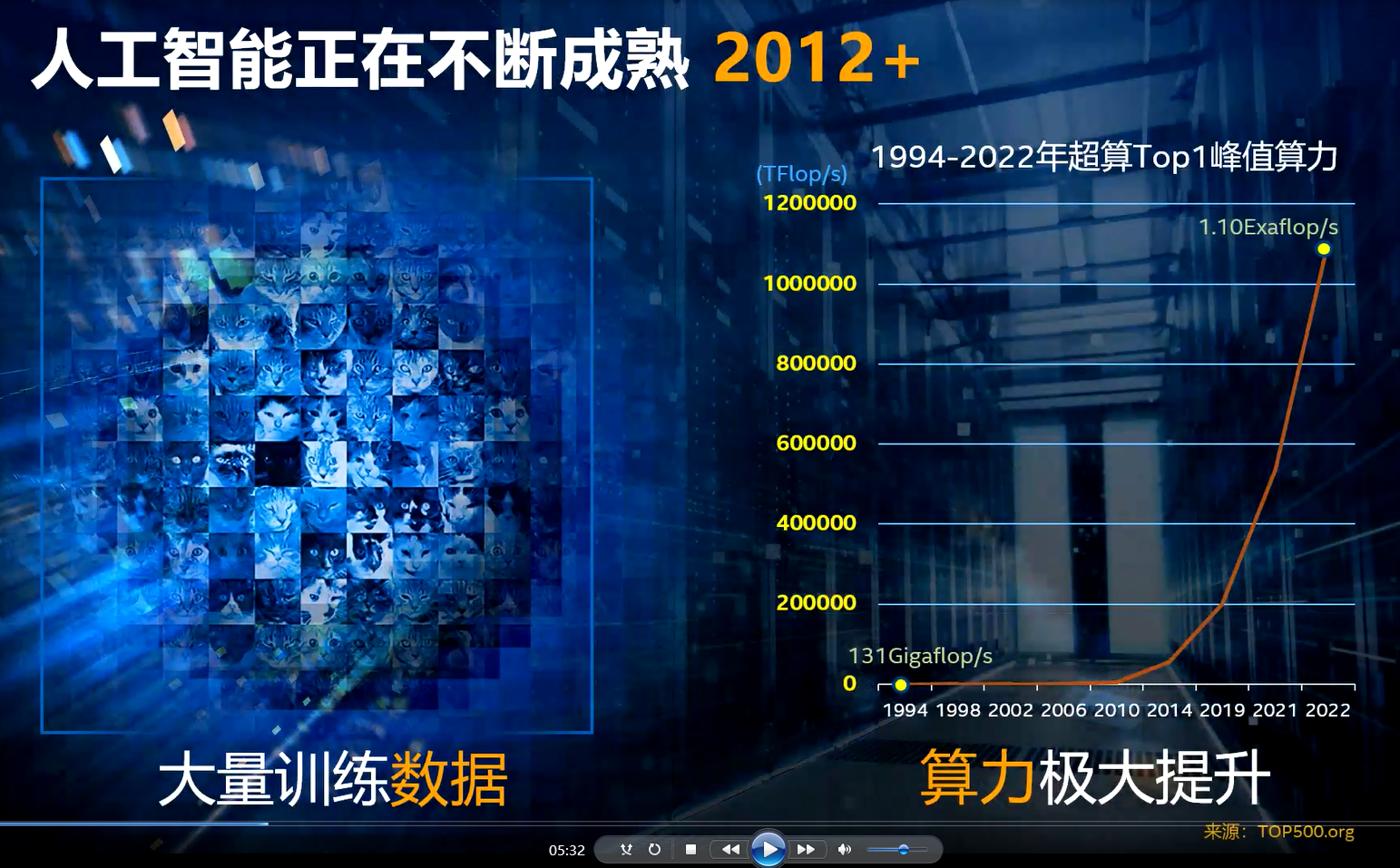
“原来完成一个人工智能网络模型的训练可能需要几个月的时间,而现在可能只需要几个小时。原来去做人工智能的推理,可能需要等上一个小时,现在可能只需要几毫秒。所以我们才能看到有越来越多带有人工智能能力的智能摄像头、智能视频服务器的出现。算力的提升,大大地拉近了人工智能技术与商业诉求之间的距离,促进了技术的落地。”张宇指出。
当今,超算500强榜单中有超过77%的超算使用的是英特尔处理器。在同期发布的体现超算效率的预测超算500强榜单中,同样有77%的超算使用的是英特尔产品。可见,英特尔在提升算力方面做出了很大的贡献。
另一方面,人工智能的发展又离不开数据,只有通过大量数据的训练才能得到一个理想的人工智能网络模型。在数据方面,如果以ImageNet为例,其中包含了超过1400万张被标注的图片,这些图片可以帮助开发人员进行图像分类的训练。但是,这些数据量积累的背后实际上是离不开我们在存储与通信技术方面能力的提升的。
回想一下上世纪90年代,当时我们所使用的移动存储介质是磁盘,当时有两种规格的磁盘,一种是3寸盘,一种是5寸盘,3寸盘的容量大概是1.44MB,5寸盘的容量是1.2MB。那个时候硬盘的容量也不过就是几百MB。而如今,我们所使用的移动硬盘,它的容量都是上TB的,我们所拥有的存储能力也有了超过百万倍的提升。
在通信方面,5G技术正在部署,它提高了数据传输的速度,降低了传输的延迟。因此,可以说,推动人工智能发展真正的要素是计算、通信与存储技术飞速的发展。
人工智能已经被应用到了边缘计算,并且在工业物联网等领域得到了应用,但是边缘人工智能离成熟还有很长的路要走。目前边缘人工智能的应用都集中在人工智能的推理阶段,人工智能网络模型的训练还是要依赖于数据中心的训练服务器进行完成的,这就不可避免地限制了模型更新的频率。而在工业物联网等领域,它有着快速更新模型的需求。比如在废品回收行业,现在已经开始利用机器人完成废品的分拣。由于废品的种类很多,形态各异,很难用已有的单一模型涵盖所有可能出现的废品,因此需要更智能化的技术来实现边缘的训练。因此,边缘训练将是边缘人工智能发展的第二个阶段。
但是边缘的训练并不是将数据中心训练的手段照搬到边缘来进行实现的。边缘的训练面临着一些独特的挑战,比如在边缘,参与操作的人员往往是产线的工作人员,这些人往往是缺乏人工智能专业的知识,也没有精力去从事数据的标注等与训练相关的工作。因此,边缘的训练就需要有更自动化的标注工具。另外,边缘训练往往是利用异常的样本进行训练的,比如带有瑕疵的样品,但在正常的产线上可供训练的带有瑕疵的样本的数量往往是非常有限的。因此,如何通过增强训练等手段来增加训练样本的数量,是边缘训练要解决的问题。
另外,用户对于数据隐私保护的需求越来越高,相应的法令法规在不断地出台。因此,如何利用联邦学习等方法来保护数据隐私,在这些保护隐私的前提下来完成模型训练的工作,这些都是边缘训练阶段需要考虑和解决的问题。
除此之外,目前人工智能的方案,其实还是非常依赖于人的参与的。虽然可以利用大量的数据以及巨大的算力来完成一个模型训练的工作,但是网络模型的结构还是需要人来进行设计的。在今后,边缘人工智能应该实现自主化的学习,这也就是现在业界大家常说的自动机器学习。在这个阶段,人工智能系统将能够根据对人的意图的理解自主地设计和选择适宜的人工智能网络的模型,利用适宜的数据来训练这些网络模型,同时能够自主地实现模型的部署与更新。
因此,边缘人工智能的发展将沿着边缘推理、边缘训练到自主学习的轨迹发展,张宇认为。“如果我们用攀登珠穆朗玛峰来进行类比,边缘推理只是让我们站在了珠穆朗玛峰的山脚,而实现的边缘训练相当于我们达到山腰,也只有完成了自主的学习,才代表我们站在了高山之巅。”他指出。

也许有人会认为边缘训练和自主学习还有些遥不可及,其实业界已经进行了相关研究的工作,并启动了相关标准的制定。“比如在去年人工智能的顶会ICLR上就有一篇满分的论文是关于自动机器学习的。在标准方面,IEEE也已经开始制定边缘继续学习的标准,我也参与其中,负责客户节点与训练节点之的间职能划分和通信协议的定义。”张宇介绍说。
总之,人工智能在边缘的应用已经起步,并且沿着从推理到训练、再到自主学习的轨迹前进。当然,可以预见,这个过程是曲折和艰苦的,张宇指出。
人工智能的发展离不开在计算、通信和存储技术方面的提升,而英特尔作为一家数据公司,其产品恰恰是涵盖了计算、通信和存储的各个方面。在人工智能的计算方面,英特尔提供了包括CPU、GPU、FPGA和人工智能加速芯片等在内的多种产品来满足用户对于算力多样化的需求。“在近日举办的英特尔On产业创新峰会上,英特尔公司旗下的Habana Labs正式发布了用于深度学习训练的第二代Gaudi处理器Gaudi2。Habana的Gaudi2处理器大幅提升了训练的性能,在训练主要用于机器视觉、自然语言处理等神经网络模型的时候,Gody2 AI训练的性能相较于英伟达的V100提升了2倍。”张宇表示。
另外,英特尔致力于不同计算架构的融合,通过构建具有异构计算能力的芯片来满足用户对于计算多样性的需求。“比如,我们所提供的凌动处理器和酷睿处理器,已经不再是传统意义上的CPU了,它们在提供强大CPU算力的同时还融合了集成显卡GPU的功能。利用集成显卡,我们可以实现高性能的媒体的编码、解码以及转码的工作,甚至于人工智能的推理,来满足游戏、视频会议等等应用对于媒体处理及边缘人工智能的需求。”张宇表示。
在通信方面,英特尔面向5G网络基础设施发布了一系列的硬件和软件的产品,以及包括智能网卡和用于以太网可编程交换机的ASIC芯片,用来实现高速软件定义的网络。在存储方面,英特尔提供的奥腾持久内存提高了数据的存储容量和读写的速度。英特尔致力于帮助用户构建一个具有人工智能的端到端解决方案,通过AI、5G、智能边缘三者的交织将智能推向一个新的发展的拐点。”他补充说。
在边缘人工智能方面,英特尔提供了各种软件和硬件的产品,这些产品不仅提供了人工智能的能力,同时还提供了功能安全、时间敏感网络、虚拟化等多样化的能力。同时其所提供的是一种可扩展的人工智能解决方案。英特尔提供的人工智能处理的芯片可应用于从智能摄像机到智能网络视频、存储器NVR到智能视频服务器等各种设备中,张宇说。

为了帮助合作伙伴快速地开发适于部署在边缘人工智能硬件的产品,英特尔的视频部门开发了各种配置的AI计算盒参考设计,包括硬件和软件两部分。硬件部分,基于其第11代Tiger Lake和第12代Alder Lake酷睿处理器。在软件方面,则提供了从视频解码到人工智能推理等完整的参考实现,而且这些软件的实现都针对英特尔平台进行了优化,充分利用英特尔处理器平台集成的显卡和硬件的能力达到了更高的性能。
利用英特尔所提供的软件和硬件的参考设计,可以快速便捷地实现边缘人工智能的解决方案。它可以实现从2路到32路以上视频的分析,多达64路的高清解码以及快速可靠的存储。“我们还可以基于硬件信任根安全技术来帮助减少网络攻击漏洞。更重要的是,英特尔产品提供了长达15年的产品生命周期,保证了长期可靠的供货。”张宇补充说。

除了用于计算、通信和存储的硬件产品,英特尔还提供了大量软件开发工具和软件的解决方案。为了帮助开发者进行机器视觉和深度学习应用的开发,英特尔发布了OpenVINO工具套件,OpenVINO可以将开发者训练好的神经网络模型部署到目标平台之上,实现深度学习推理的操作。它可以帮助开发者完成从模型到快速的构建,到模型的优化,再到模型的部署的完整流程。
OpenVINO从2018年第一次发布以来,保持了大约一个季度一个新版本的速度不断地更新和迭代。目前,OpenVINO已经开源服务于全球超过数十万的开发人员,张宇说。

OpenVINO工具套件提供了300多个英特尔预训练的网络模型,涵盖了目标检测、目标识别、语义分割、机器翻译等等,可以用于学习和演示的模拟,或者也可以用于开发深度学习的软件。这个深度学习的部署工具套件提供两个关键的组件:一个是模型优化器(简称MO),另外一个是推理引擎(简称IE)。模型优化器可以对开发者在不同的人工智能开放框架上。比如Tensorflow、Caffe、Pytorch以及百度的PaddlePaddle,在这些人工智能框架上所开发的神经网络模型,在保证精度的前提下进行简化,并且将简化的结果转换成中间表述文件。推理引擎可以读取这些中间表述文件,并且通过特定的硬件插件将中间表述文件运行到不同的目标平台之上。“目前我们所能提供的插件包括CPU的插件、GPU的插件、FPGA的插件和VPU的插件,开发者可以在代码不变的情况下将程序跑在不同的硬件平台上,从而可以极大地降低开发的成本。”张宇表示。
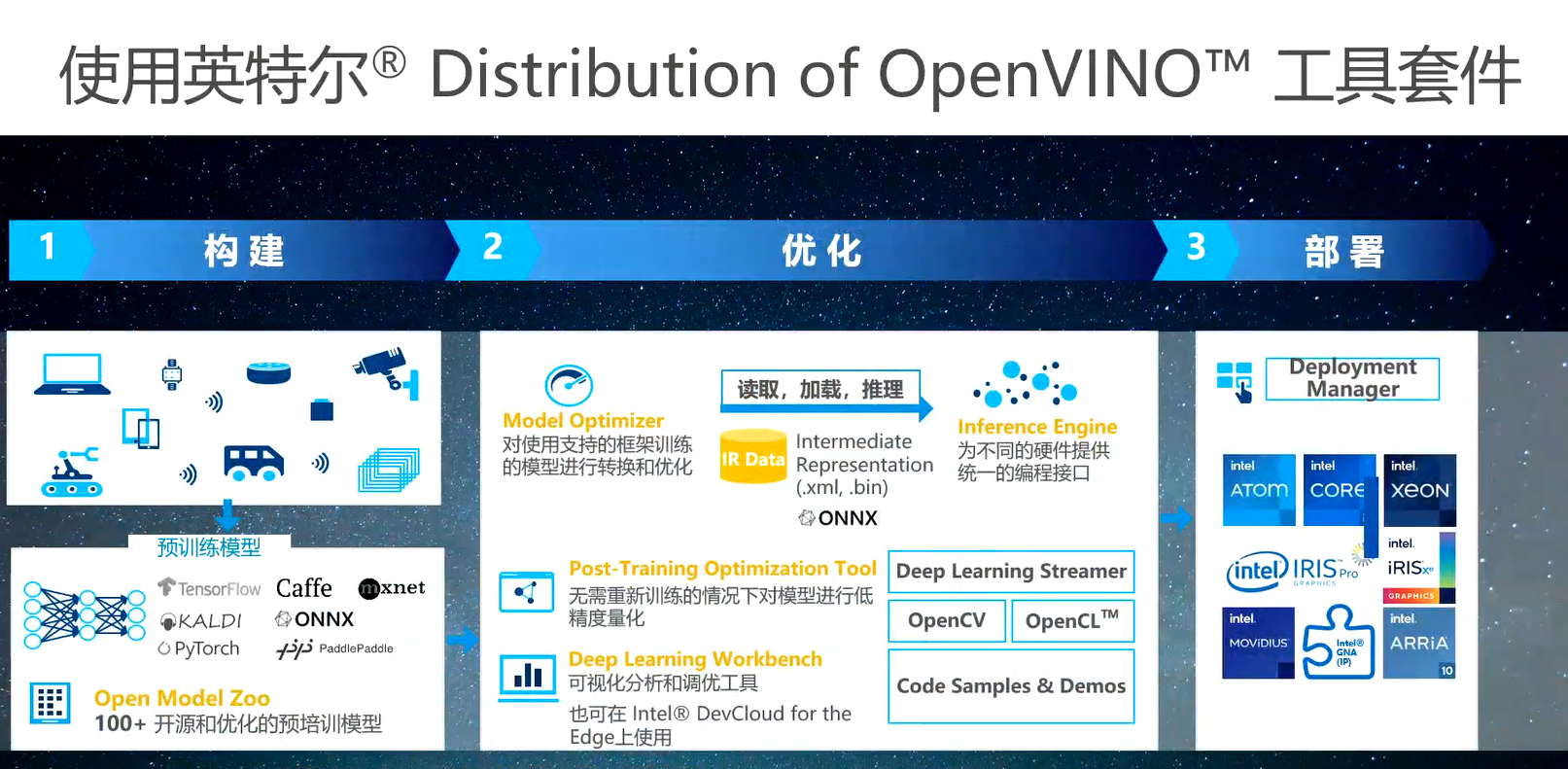
OpenVINO自发布以后不断地进行更新和迭代,在不久之前刚刚发布了2022.1的版本。2022.1的版本是OpenVINO近三年半以来最大的一次版本的更新与迭代,它的更新主要集中在三个方面:更新、更简洁的API接口;对模型有了更广泛的支持;同时还提供了更加出色的可移植性和性能。
英特尔还非常重视中国人工智能开发者的需求。“比如,我们对中国人工智能框架百度的飞浆(PaddlePaddle)人工框架有了更好的支持。飞浆与OpenVINO,我们已经在Open Model Zoo领域有了深度的合作,共同去支持开源社区的一些工作。”张宇指出,“OpenVINO将适配更多更新的PaddlePaddle的模型,通过Open Model Zoo来加速开发者项目的落地,让OpenVINO的开发者有机会去尝试更多优质的预训练的模型。我们跟百度已经从目标检测、语义分割和图像分类入手选定了一些优质的预训练模型进行适配。同时,今后我们还会有更多的模型加入到这样适配的计划。”
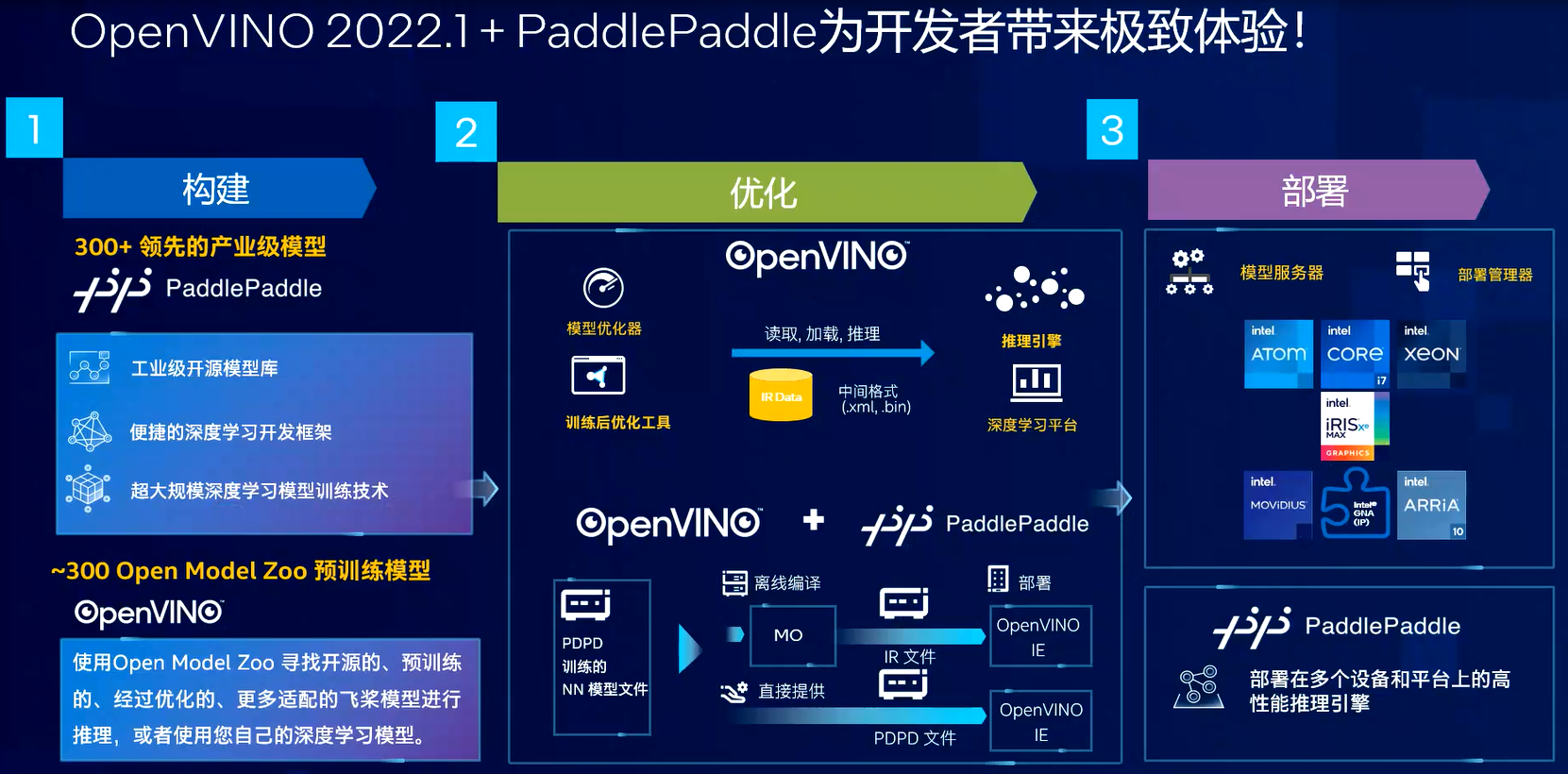
“在模型的优化阶段,原本的OpenVINO对于飞浆的框架并没有直接的支持,对于飞浆的模型需要首先转换成ONNX格式,才能够使用英特尔的模型优化器工具进行模型的优化和IR格式的转换,这样会对模型的精度等相关的属性造成一定的损失,并且增加了产品开发的时间。对于开发者而言,操作也相对来说比较烦琐。随着飞浆和OpenVINO产品合作的展开,在2022.1的版本中,前端的框架可以直接支持飞浆的模型。开发者现在无需中间格式的转换,可以将飞浆模型通过MO直接转换成IR格式,并将飞浆的模型直接作为OpenVINO推理引擎的输入,为开发者提供了更为简洁的人工智能推理的体验。”
边缘人工智能的发展离不开生态合作伙伴共同的努力。英特尔积极创建了人工智能的生态,与包括ODM、OEM、ISV和SI等众多合作伙伴共同构建了OpenVINO的生态系统。为了推动国内边缘智能的发展,还在国内推动成立了OpenVINO中文社区,为广大开发者创建了一个相互交流和学习的平台。
同时,英特尔与全球超过1200个生态合作伙伴共同推出了超过300个边缘解决方案,服务于全球超过1万个用户。这些应用服务于在工业领域的像预测性维护、机器人,医疗领域的医疗成像、远程医护的护理,在零售领域比如智能零售,以及在消费领域云游、CDN和最新的元宇宙等等场景。
为了推动人工智能技术的落地,英特尔与合作伙伴一道进行了很多应用实践。例如在刚刚过去的北京冬奥会上,英特尔的3DAT(三维运动员追踪)技术,就被运用到了冬奥会中。这一技术是基于运动视频,通过人工智能和计算机视觉的算法,可以从标准的视频源中提取出运动员的骨骼和肌肉的形状以及运动的轨迹,重建运动员2D和3D的骨骼运动姿态及轨迹的模型,并且能够生成生物力学的数据。

在建立模型的同时,3DAT技术还能够输出运动表现分析。这一技术被运动到了速度滑冰和越野滑雪的运动员训练,提高了备战的效率。这一技术也创造性地应用到了冬奥会的开幕式中,基于运行在英特尔第三代至强可扩展处理器之上的3DAT技术,在冬奥会开幕式上的《致敬人民》和《雪花》两个环节中,实现了演员和鸟巢地面大屏系统完美的实时的互动,给全世界的观众留下深刻的印象。
“类似的科技向善的例子,今后还会做得越来越多。人工智能的发展离不开生态伙伴的共同努力,英特尔以‘水滴万物而不争’的生态之道,积极创造人工智能的生态。我们将不断地推动智能科技的创新,持续深化产业的合作,用我们的技术与产品来助力基于边缘智能的发展,为人类创造更多的福祉。”张宇总结道。
 最前沿的电子设计资讯
最前沿的电子设计资讯

