
2021年8月25日,中国上海——今天燧原科技在一年一度的Hot Chips大会上由首席架构师刘彦和资深芯片设计总监冯闯一起介绍了第一代云端训练芯片“邃思1.0”的架构细节。Hot Chips是全球高性能微处理器和集成电路相关的重要会议之一,芯片行业巨头每年都借此机会展示自己公司的最新成果,包括处理器体系结构,基础架构计算平台,内存处理等各类技术。
燧原科技第一代通用人工智能训练芯片“邃思1.0”封装示意图
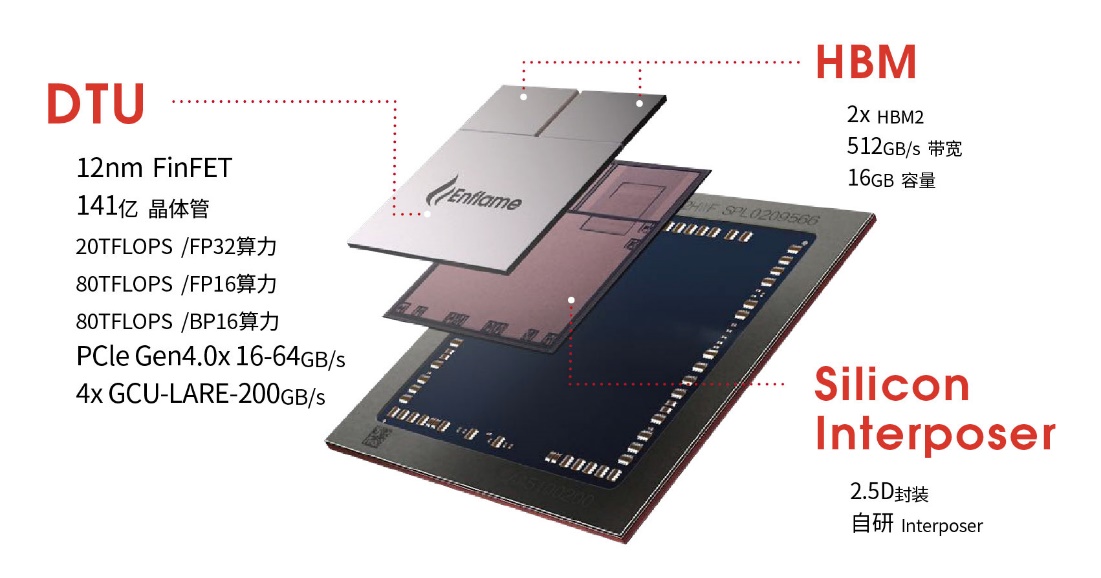
邃思1.0是燧原科技2019年12月发布的第一代云端AI训练芯片,采用众核结构,其计算核心采用了燧原科技自研的GCU-CARE计算引擎。整个SOC拥有32个GCU-CARE计算引擎,组成4个计算群组,全面支持常见AI张量数据格式(FP32/FP16/BF16, INT8/INT16/INT32),更全面地支撑客户业务。CARE还创新地通过复用张量核心,用最有效的晶体管效率提供了标量、向量、张量以及多种数据精度的计算能力。
GCU-DARE数据架构,面向数据流优化,在数据流动中进行处理。512GB/s的HBM和200GB/s的GCU-LARE互联,数倍于传统GPU、CPU;强劲的分布式片上共享缓存,提供10TB/s的超大带宽;可编程共享缓存,可控线程内、线程间数据常驻共享,消除不必要的IO访问,既降低了数据访问延时,又节约了宝贵的IO带宽;同时,DARE架构还提供数据异步加载接口,支持数据与运算的流水执行,提高运算并行度。
四路 GCU-LARE智能互联,200GB/s的高速低延时片间互联接口,灵活支持不同规模的计算需求,可支持千卡级规模集群,为大中小型数据中心提供基于不同需求的人工智能训练产品组合。

“邃思1.0”SOC
邃思1.0人工智能加速芯片专为云端训练场景设计,支持CNN、RNN、LSTM、BERT等常用人工训练模型,可用于图像、流数据、语音等训练场景。采用标准PCIe 4.0接口,广泛兼容主流AI服务器,可满足数据中心大规模部署的需求,且能效比领先。
演讲的最后部分,刘彦还介绍了上个月刚刚在世界人工智能大会上发布的“邃思2.0”训练芯片。经过全新升级迭代后,邃思2.0的计算能力、存储和带宽、互联能力较第一代训练产品有巨大提升,对超大规模的模型支持能力获得显著增强。由此,燧原科技成为国内首家发布第二代人工智能训练产品组合的公司。
邃思2.0进行了大规模的架构升级,针对人工智能计算的特性进行深度优化,夯实了支持通用异构计算的基础;支持全面的计算精度,涵盖从FP32、TF32、FP16、BF16到INT8,单精度FP32峰值算力达到40 TFLOPS,单精度张量TF32峰值算力达到160 TFLOPS。同时搭载了4颗HBM2E片上存储芯片,高配支持64 GB内存,带宽达1.8 TB/s。GCU-LARE也全面升级,提供双向300 GB/s互联带宽,支持数千张云燧CloudBlazer加速卡互联,实现优异的线性加速比。

燧原科技第二代通用人工智能训练芯片“邃思2.0”
而同步升级的驭算TopsRider软件平台,成为燧原科技构建原始创新软件生态的基石。通过软硬件协同架构设计,充分发挥邃思2.0的性能;基于算子泛化技术及图优化策略,支持主流深度学习框架下的各类模型训练;利用Horovod分布式训练框架与GCU-LARE互联技术相互配合,为超大规模集群的高效运行提供解决方案。开放升级的编程模型和可扩展的算子接口,为客户模型的优化提供了自定义的开发能力。
关于燧原科技
燧原科技专注人工智能领域云端算力平台,致力为人工智能产业发展提供普惠的基础设施解决方案,提供自主知识产权的高算力、高能效比、可编程的通用人工智能训练和推理产品。其创新性架构、互联方案和分布式计算及编程平台,可广泛应用于云数据中心、超算中心、互联网、金融及政务等多个人工智能场景。
燧原科技携手业内国际标准组织,秉承开源开放的宗旨,与产业伙伴一起促进人工智能产业发展。
 最前沿的电子设计资讯
最前沿的电子设计资讯
