
作者:毓
2019 年的 Autonomous Day 上,特斯拉带来了首款车企自研的自动驾驶计算方案;2020 年的 Battery Day,马斯克又发布了号称续航提升 54% 的 4680 电池+一体式底盘。
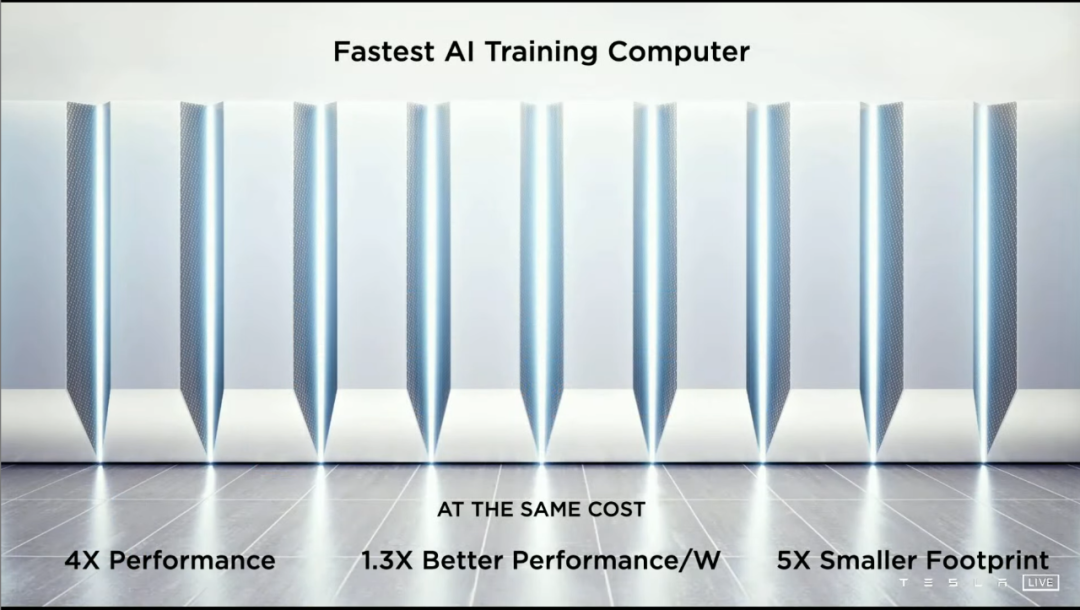
而今年的 AI Day,特斯拉正式兑现了马斯克承诺的「一家人工智能公司」,发布了第一款汽车企业自研的人工智能训练芯片 D1,以及目前性能最强的人工智能计算机柜 DOJO Pod——它会为特斯拉的纯视觉 FSD 深度学习服务。
除此以外,特斯拉还公开了纯视觉 FSD 的工作原理、遇到的挑战,以及 Autopilot 软件团队的解决方案。
最出乎意料的,是马斯克带来了 one more thing——特斯拉研发的机器人 Tesla Bot!

我们用尽可能易懂的表达,尽量摘录了大部分内容,但时间关系,具体的原理今天很难展开讨论,请大家见谅。
今天的文章不短,而且很多图,但我们还是强烈建议您看完全文,因为这场发布会实在太炸裂。
前言:特斯拉的 AI 原命题
如果你制定了超越一个行业的计划,要不你是个疯子,要不你就会滚起认知和实践的雪球,做到无数个「第一次」。
特斯拉就是典例。
DOJO 的诞生并不是为了称霸超算界而称霸超算界,它更像是普罗米修斯手里的火种,目的是为特斯拉,以及后面的一众车企/技术公司,照亮人工智能的前路。

所以进入正文前,请大家牢记一个问题:当前地球量产科技基础上,如何打造最极致的人工智能?
因为这是 DOJO、FSD、Tesla Bot 的灵魂,也是特斯拉本次 AI Day 的原命题。
一、「用眼睛开车」
很多朋友已经对这句话倒背如流,不过今天还是得重复一次,作为本章节的纲领——「你会开车,是因为你用眼睛看路,而不是眼睛发射激光」。
这句话将一个深刻的道理极限地浅显化,以至于引来了可能是自动驾驶领域最激烈(起码之一)的争论。
这个道理是:人类经过漫长岁月的进化,已经形成了一套从眼睛开始,以大脑为中枢,肢体为具现的「地球 OL 启动器」。
所以,特斯拉的纯视觉方法论,并不像是绕开雷达信号融合的「捷径」,反而可能是最形而上学的蜀道难——因为特斯拉希望造一个轮子上的人。
前不久的 2021 CVPR 计算机视觉会议上,特斯拉 AI 部门高级主管 Andrej Karpathy 已经分享了很多 Autopilot 软件细节,大家可以点击这里回看我们的报道,今天我们只聊特斯拉做到了什么。
想要实现 Andrej 说过的,让汽车用眼睛开车,有摄像头是不够的,关键是如何分解摄像头信号,又如何让汽车思考这些信号。
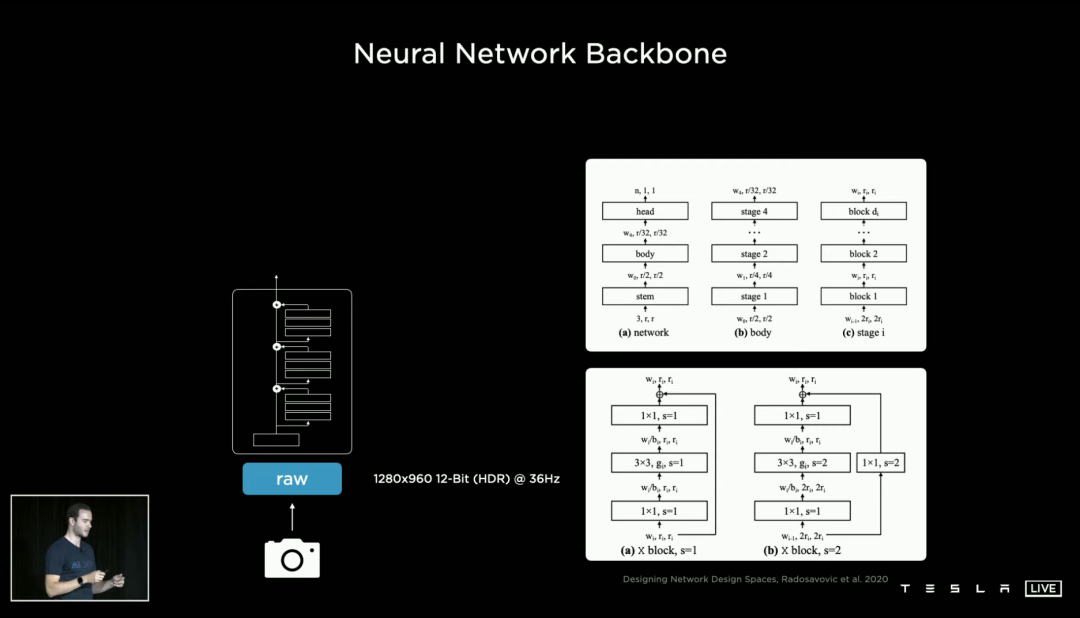
但事实上,先不说更深层次的「思考」,光是让纯视觉「认清」一样东西,就已经需要耗费大量努力。
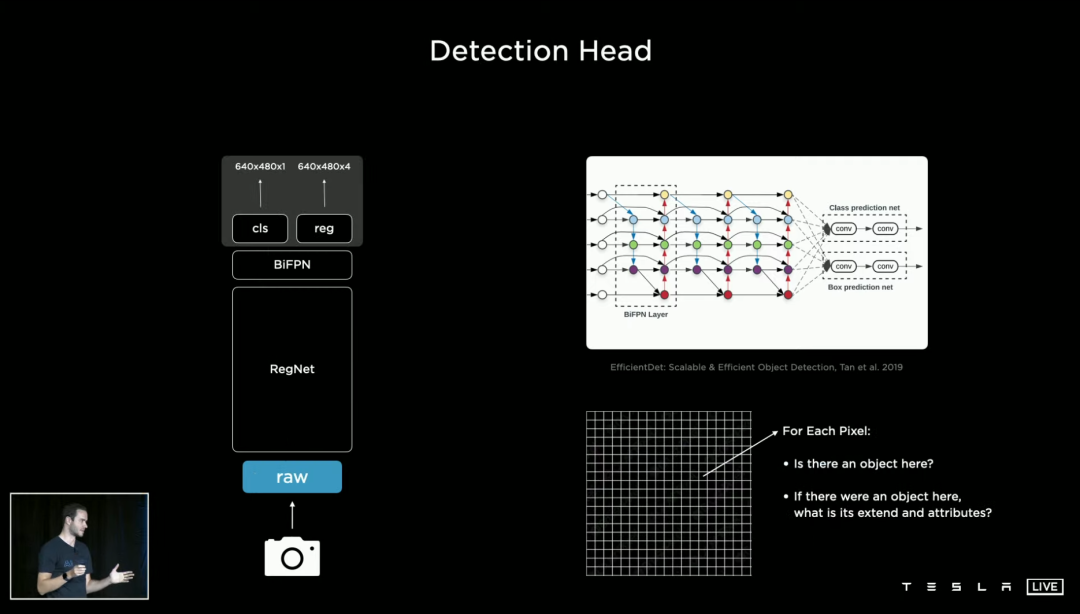
和我们开眼看世界不太一样,摄像头看到的是像素集合,因此神经网络要做的,是分析每个像素之间的联系,并判断哪些像素集合成哪些物体。
点线面体,我们现在来到了「体」,也就是由无数同一时间发生的、存在的事物组成的真实世界。以驾驶为例子,「障碍物」、「交通灯」、「车道线」等等,都是需要神经网络认清的元素。
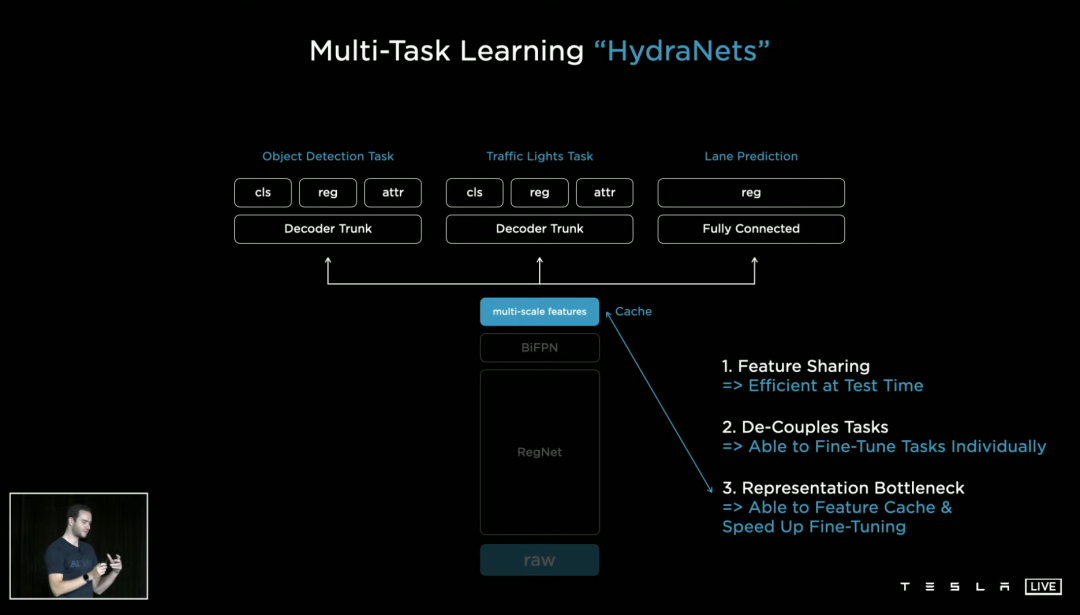
于是我们需要多任务深度学习,特斯拉则将自己的多任务网络称为「HydraNets」。
纯视觉 Autopilot 数据,由 8 个摄像头,每个摄像头每秒拍摄的 36 帧画面组成,所以每一帧的最终效果如下图所示——每秒一共有 36 组这样的画面。
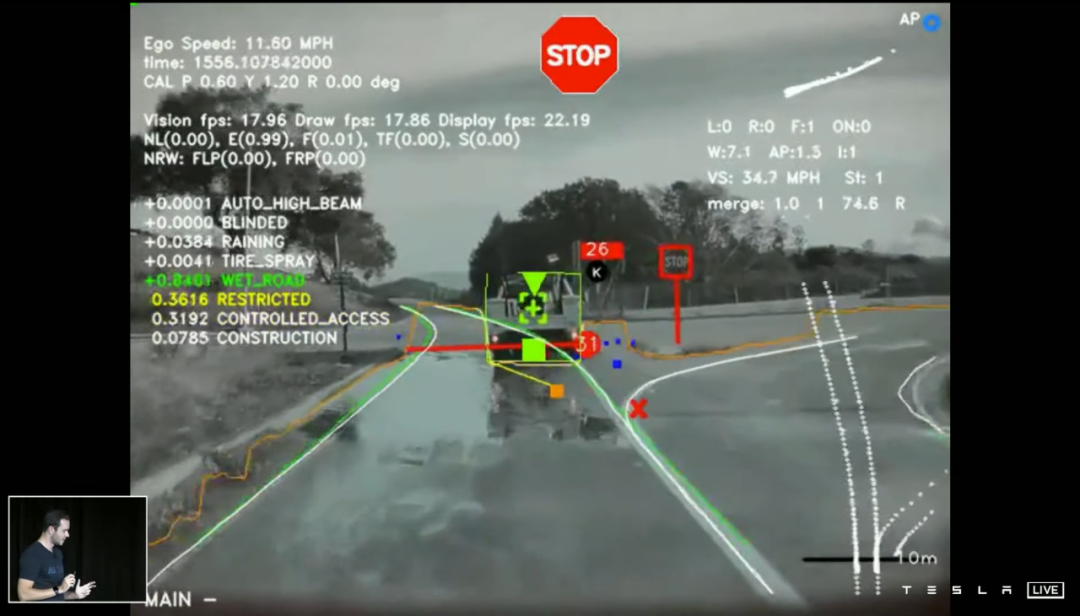

挑战随即而至:多摄像头融合的界限很难划分、图像内的空间也并不是最终映射的实际空间(类似于畸变)。


一个明显的例子是长长的半挂,同时出现在 5 个摄像头的视野内:

除了看清物体,看路也是至关重要的一环,特别是正确识别道路的边界。在这张范例里,道路边缘的特征点被车辆阻挡,这时候就需要从画面其他部分「寻找线索」。
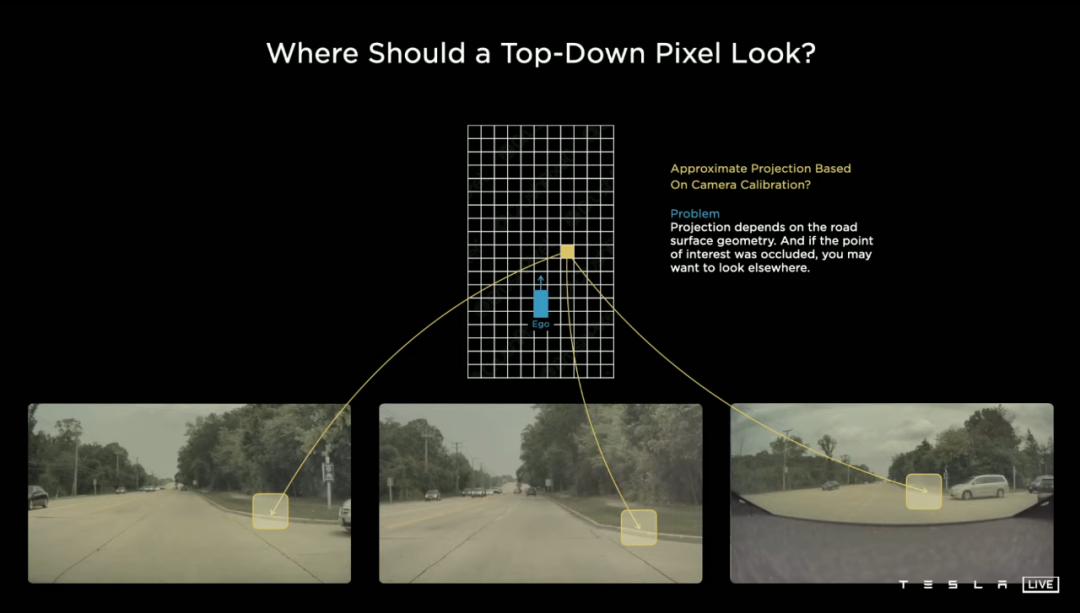
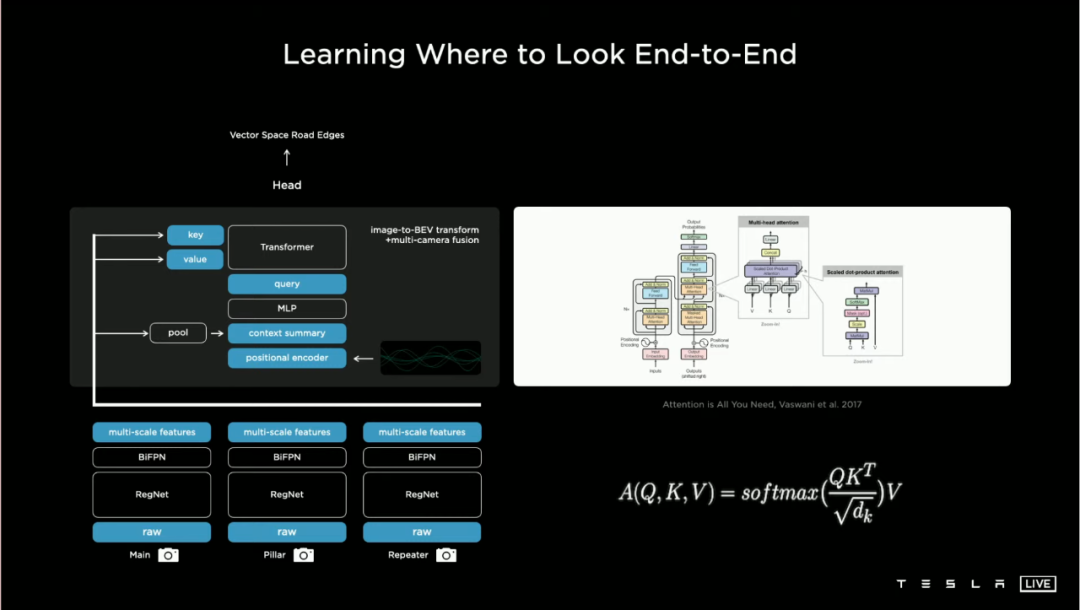
事实上,让车子搞清楚「需要看哪里」,同样不是容易的事情,特斯拉把算法的简单结构 po 了出来:
接下来要搞定的,是如何「看得完整」。也就是正确识别某个物体跨越多个摄像头的全部运动轨迹,比如前面有车经过:

最后是「记得你看过的东西」。
我们在开车的时候,以往的经验会告诉我们,路边停着的车队中间可能会窜出一个人、单行道上没有打双闪的车,停下来也许短时间也不会走...
以至于速度、方向、标识等等纷繁的细节,它们都组成了我们对路况即时的记忆,然后决定了我们什么时候应该做什么。

 最前沿的电子设计资讯
最前沿的电子设计资讯

