
三、一切为了数据,为了数据的一切
2021 CVPR 会议上,Andrej 表示特斯拉转向纯视觉深度学习之后,已经积累了超过 60 亿个物体标签,超过 1.5PB 的数据量——那还只是 6 月底。

为了应对如此庞大的数据,特斯拉表示他们目前拥有一支 1000 人的数据标签队伍,与工程师一起工作,打造了完全定制化的数据标签&分析架构。
在传统的 2D 图像标注基础上,特斯拉现在可以实现 4D,也就是立体空间+时间戳的四维标注,效果如图:
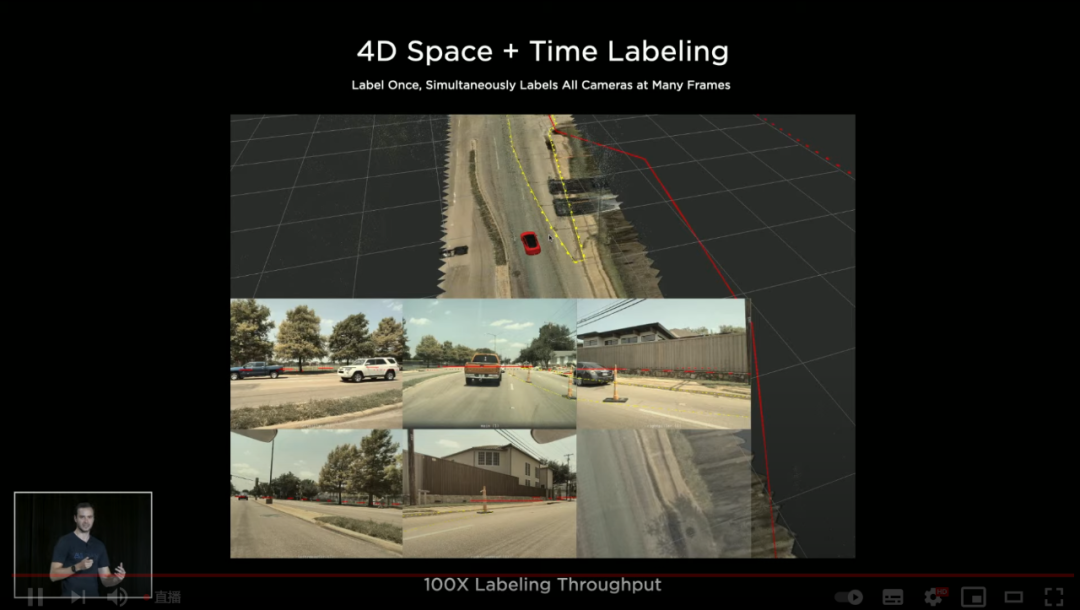
另外,销量屡创新高,路上跑的车越来越多之后,特斯拉如今可以对同一条路做多次数据收集:

加上墙壁、路障,和其他所有物体,再加上周边行人、车辆的闭环整合,一辆特斯拉眼中的数据世界,是这样的:

四、Dojo,地表最强!
终于来到本次发布会的重中之重了。

目前特斯拉唯一一款自研芯片,是 FSD Chip。单芯算力 72TOPS,双芯组成的 Autopilot 硬件 3.0 算力 144TOPS。

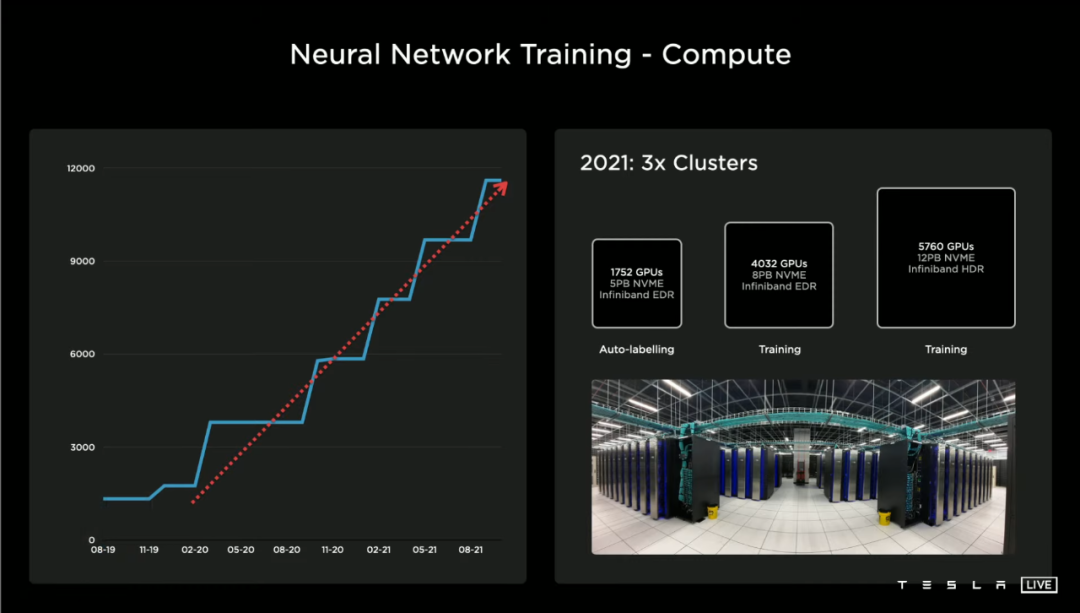
除了装在 SEXY 家族车型上,特斯拉还在用硬件 3.0 做 AI 评估,超过 3000 块 HW3.0 主板组成的 3 个数据中心,每周可以运行 100 万次循环。
而前不久 Andrej「爆料」的,目前用于神经网络训练的超级计算机,则使用了英伟达 A100 GPU 方案,合计 5760 个 GPU 以及 12PB(1PB=1024TB)的 NVME 高速存储器。
但在 Dojo 面前,它俩都像是上一个时代的产物——或者说本来就是。
正式进入 Dojo 参数之前,我们先来强调一下:特斯拉对于 AI 训练计算机的核心诉求,并不是算力,而是带宽和延迟。
这一点,2019 年的 Pete Bannon 已经提到过:「自动驾驶运算需要极高的带宽,起码要达到 1TB 每秒,FSD 芯片(内部)可以达到 2TB 每秒」。
多芯片之间数据交换的带宽(类似于车道数)和延迟(类似于道路限速),是特斯拉在 AI 训练路上狂奔得足够久之后的深刻总结。

Dojo 的设计原命题,就是带宽和延迟,这两个要素,是决定特斯拉能否达到「最佳 AI 训练性能、更大更复杂神经网络、能耗成本优化」目标的关键。

再卖个关子,来看看英伟达的 A100 多芯片方案,多个芯片位于不同的 PCB 基板,用桥接器连接。这已经是目前最快的桥接器,速度达到了 600GB 每秒。
但对于特斯拉来说,这还远远不够。
多芯片之间最理想的数据交换方式,就是「放在一起」,也就是位于同一块基板上,左邻右里排布。
而特斯拉更进一步,不是将芯片们「放」在一起,而是「封装」在一起。
封装多个芯片有很多种方法,比如这颗英特尔处理器一样,两块芯片放在一个基板上:

而特斯拉又进了一步,使用了台积电首次量产的 InFO-SoW 扇上晶圆直出封装技术,也就是直接从晶圆上刻出一个个芯片,然后整块晶圆摁在基板上。

全部装起来之后,一个 Dojo 计算模组长这样:

如果只刻一块芯片,那它叫 D1 Chip,长这样,基于台积电 7 纳米工艺打造,核心面积 645 平方毫米,内置了 500 亿个晶体管,内部线束长度高达 11+ 英里(约 18 公里):

内部线束如此惊人,是因为 D1 芯片内和芯片间的通信带宽简直骇人听闻。这同时得益于台积电的封装技术(芯片之间的距离极短),以及特斯拉的芯片设计。
一块 D1 芯片由 354 个训练节点组成,每个训练节点内部都起码有以下部分:
64 位 4 路集相的多线程 CPU;
1.25MB SRAM 缓存;
低延迟数据交换结构;
SIMD 单指令多数据流的浮点/整数单元
D1 训练节点的一大特点,就在于这个「低延迟数据交换结构」。
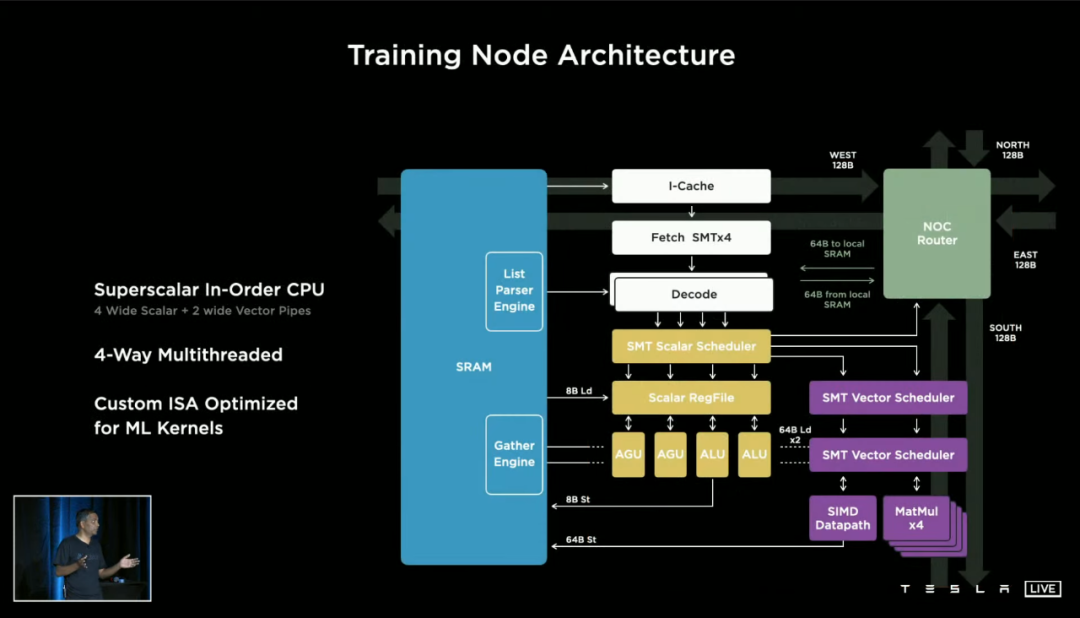
上图右上角有一个叫做「 NOC Router」的结构,这是训练节点之间交换数据的工具——特斯拉丧心病狂地给每一个小节点,都设计了上下左右各 64bit 的通道。
这是什么意思?我们还是直接看疗效:D1 的芯片内部带宽高达 10TB 每秒,芯片外带宽也高达 4TB 每秒!
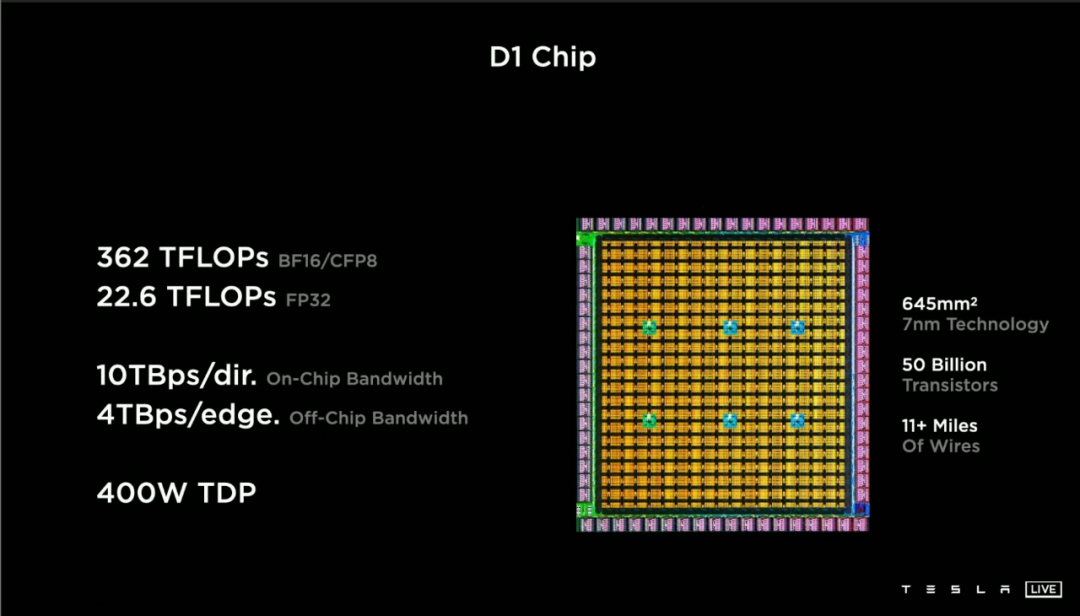
算力方面,每一个训练节点都拥有 1024GFLOPS 的 BF16/CF8 精度计算能力(这两个是较新的精度标准),或者 32GFLOPS 的 FP32 精度计算能力。
354 个训练节点构成的 D1 芯片,则可以实现高达 362TFLOPS 的 BF16/CF8 精度算力(FP32 精度 22.6T)——而 25 个 D1 芯片组成的 Dojo 计算模块,则将这块人手轻松举起来的「电脑」算力,推到了惊人的:
9PFLOPS!

这是什么概念?
最终成品的单个 DOJO 计算机柜,叫做 DOJO Pod,总算力超过 1.1EFLOPS(BF16 精度),内含 3000 个 D1 芯片,也就是只需要 120 片上图这样小巧的模组——就达到了超越全球超算排行榜第 5 名的 FP32 精度算力。

而目前的第 5 名,隶属于美国国家能源研究科学计算中心(NERSC)的 Perlmutter,一共有 40 个机柜。
当然,马斯克说过的可是「1 exa flops at de facto FP32(货真价实的 1E FP32 精度算力)」。目前一个 Dojo Pod 可实现不了——但这次跳票也许真不怪马斯克,台积电目前有多紧俏,相信大家都有所耳闻。
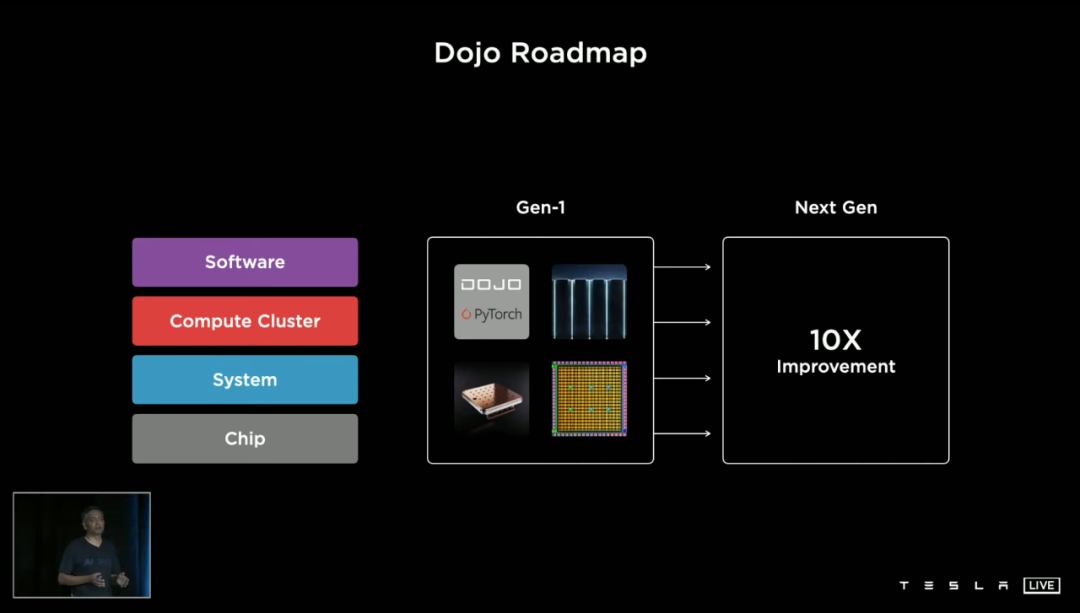
哦对了,下一代 Dojo 和相关软件工具已经在研发了,目标又是 10 倍级别的系统级性能提升。
 最前沿的电子设计资讯
最前沿的电子设计资讯

