
很多人会问,为什么没有英伟达?目前所有主流深度学习运算主流框架后端都是英伟达的CUDA,包括TensorFlow、Caffe、Caffe2、PyTorch、mxnet、PaddlePaddle,CUDA包括微架构和指令集以及并行计算引擎。CUDA垄断了深度学习或者也可以说垄断了人工智能,这一点类似ARM的微架构和指令集。CUDA强大的生态系统,造就了英伟达牢不可破的霸主地位。深度学习的理论基础在上世纪五十年代就已经齐备,无法应用的关键就是缺乏像GPU这样的密集简单运算设备,是英伟达的GPU开创了人类的深度学习时代,或者说人工智能时代,CUDA强化了英伟达的地位。你可以不用英伟达的GPU,但必须转换格式来适应CUDA。
CUDA开启了并行计算或多核运算时代,今天人工智能用的所有加速器都是多核或众核处理器,几乎都离不开CUDA。CUDA程序构架分为两部分:Host和Device。一般而言,Host指的是CPU,Device指的是GPU或者叫AI加速器。在CUDA程序构架中,主程序还是由CPU 来执行,而当遇到数据并行处理的部分,CUDA 就会将程序编译成 GPU能执行的程序,并传送到GPU。而这个程序在CUDA里称做核(kernel)。CUDA允许程序员定义称为核的C语言函数,从而扩展了C语言,在调用此类函数时,它将由N个不同的CUDA线程并行执行N次,这与普通的C语言函数只执行一次的方式不同。执行核的每个线程都会被分配一个独特的线程ID,可通过内置的threadIdx变量在内核中访问此ID。在 CUDA 程序中,主程序在调用任何 GPU内核之前,必须对核进行执行配置,即确定线程块数和每个线程块中的线程数以及共享内存大小。你可以不用英伟达的GPU,但最终都离不开CUDA,也就是需要转换成CUDA格式,这就意味着效率的下降。所以英伟达是参考级的存在。
从CUDA的特性我们不难看出,单独的AI加速器是无法使用的。今天我们分析三款可用于智能驾驶领域的AI加速器,分别是高通的AI100,华为的昇腾,特斯拉的FSD。这其中高通AI100比较少见。


同时支持24路200万像素帧率25Hz的图像识别,特斯拉的FSD不过是同时8路130万像素帧率30Hz的图像识别,性能至少是特斯拉FSD的3倍。

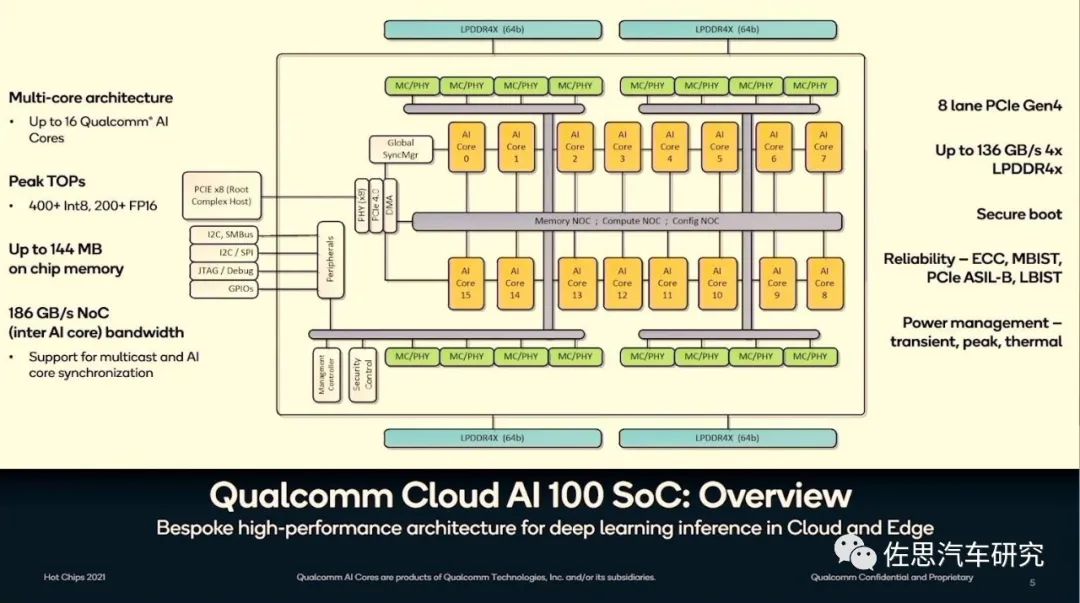
上图为高通AI100内部框架图。设计很简洁,16个AI核,内核与内核之间是第四代PCIe连接,带宽有186GB/s,8通道的PCIe网络,然后再与各种片上网络(NoC),包括存储NoC、运算NoC和配置NoC通过PCIe总线连接。片上存储器容量高达144MB,带宽136GB/s。外围存储器为256Gb的LPDDR4。支持汽车行业的ISO26262安全标准,即ASIL,达到B级。
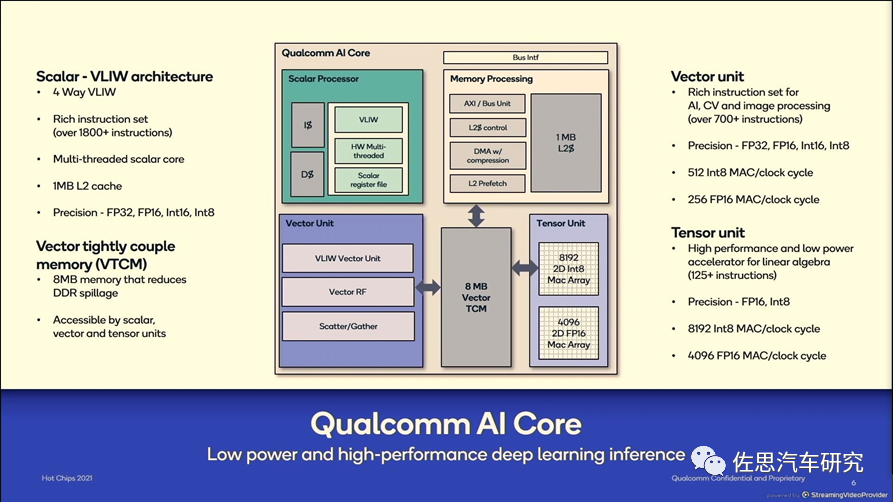
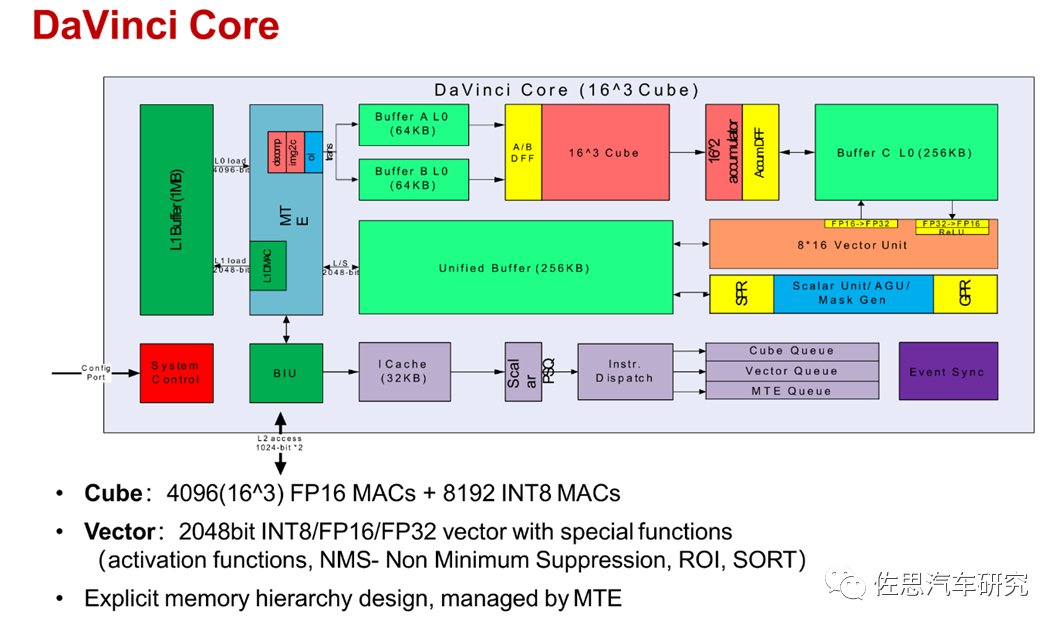
每个AI核内部框架如上,主要分4个部分,分别是标量处理、向量处理、存储处理和张量处理。深度学习中经常出现4种量,标量、向量、矩阵和张量。神经网络最基本的数据结构就是向量和矩阵,神经网络的输入是向量,然后通过每个矩阵对向量进行线性变换,再经过激活函数的非线性变换,通过层层计算最终使得损失函数的最小化,完成模型的训练。
标量(scalar):一个标量就是一个单独的数(整数或实数),不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。标量通常用斜体的小写字母来表示,标量就相当于Python中定义的x=1。
向量(Vector),一个向量表示一组有序排列的数,通过次序中的索引我们能够找到每个单独的数,向量通常用粗体的小写字母表示,向量中的每个元素就是一个标量,向量相当于Python中的一维数组。
矩阵(matrix),矩阵是一个二维数组,其中的每一个元素由两个索引来决定,矩阵通常用加粗斜体的大写字母表示,我们可以将矩阵看作是一个二维的数据表,矩阵的每一行表示一个对象,每一列表示一个特征。
张量(Tensor),超过二维的数组,一般来说,一个数组中的元素分布在若干维坐标的规则网格中,被称为张量。如果一个张量是三维数组,那么我们就需要三个索引来决定元素的位置,张量通常用加粗的大写字母表示。
不太严谨地说,标量是0维空间中的一个点,向量是一维空间中的一条线,矩阵是二维空间的一个面,三维张量是三维空间中的一个体。也就是说,向量是由标量组成的,矩阵是向量组成的,张量是矩阵组成的。

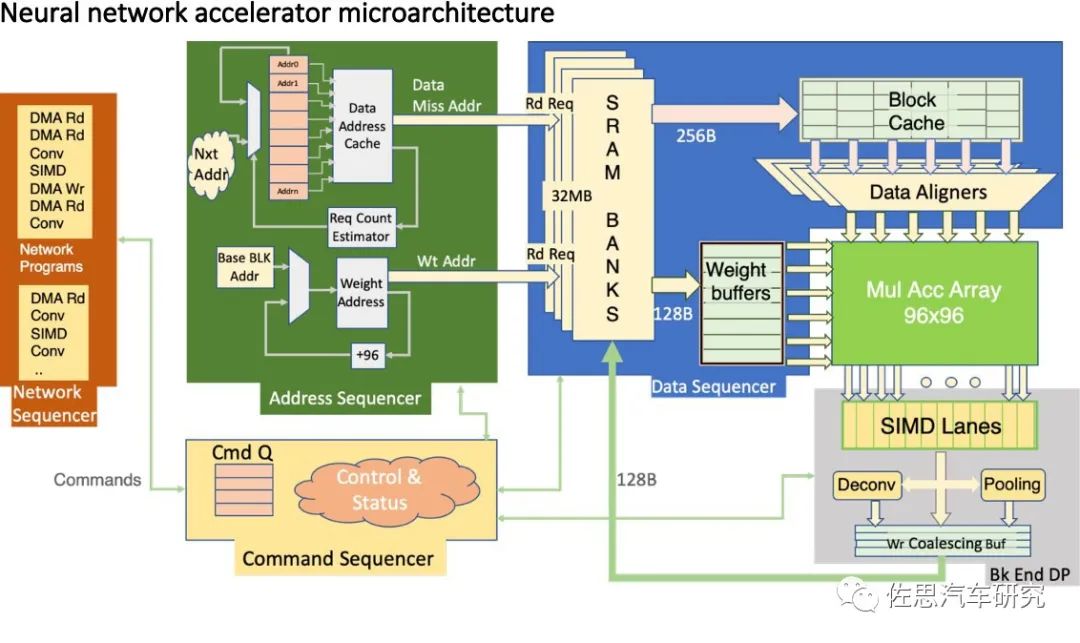
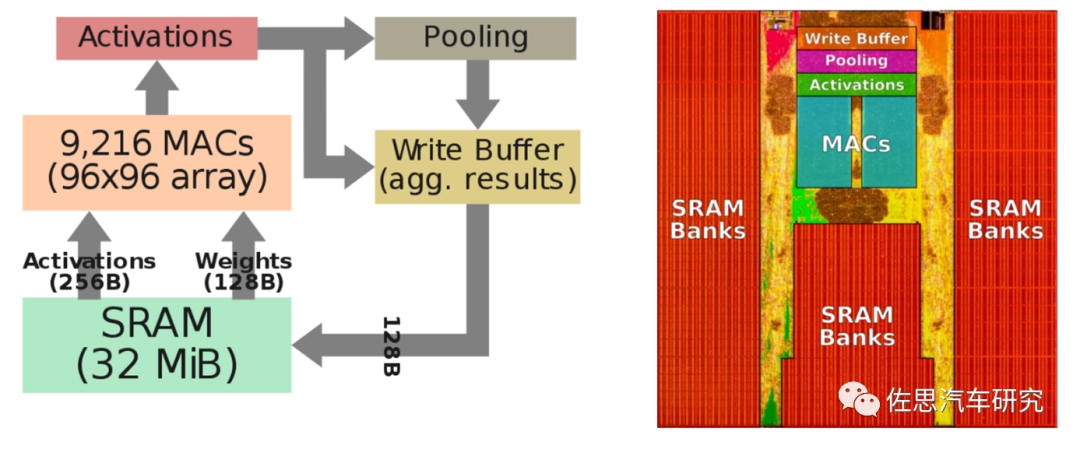
上图为特斯拉FSD神经网络架构,特斯拉把矩阵的乘和累加简单写成了MulAccArray。特斯拉做芯片刚刚入门,FSD上除了NPU是自己做的外,其余都是对外采购的IP。NPU方面,主要就是堆砌MAC乘和累加单元,在稍微有技术含量的标量计算领域,特斯拉没有公布采用何种指令集,应该是没什么特色。华为和高通都是采用了VLIW。
高通的向量处理器可以简单看作一个DSP。众所周知,高通的AI技术来源于其DSP技术,高通对DSP非常青睐,而已经失去生命力的VLIW超长指令集非常适合用在深度学习上,深度学习运算算法非常单一且密集度极高,并不需要通用场景下的实时控制。并且其程序运行有严格的时间要求,cache这种不可控时间的结构就不适合了,通常采用固定周期的TCM作为缓存,这样内存访问时间就固定了。有了上述的特征,静态编译在通用场合下面临的那些困难就不存在了,而DSP其更高效的并行运算能力和简化的硬件结构被完全发挥出来。
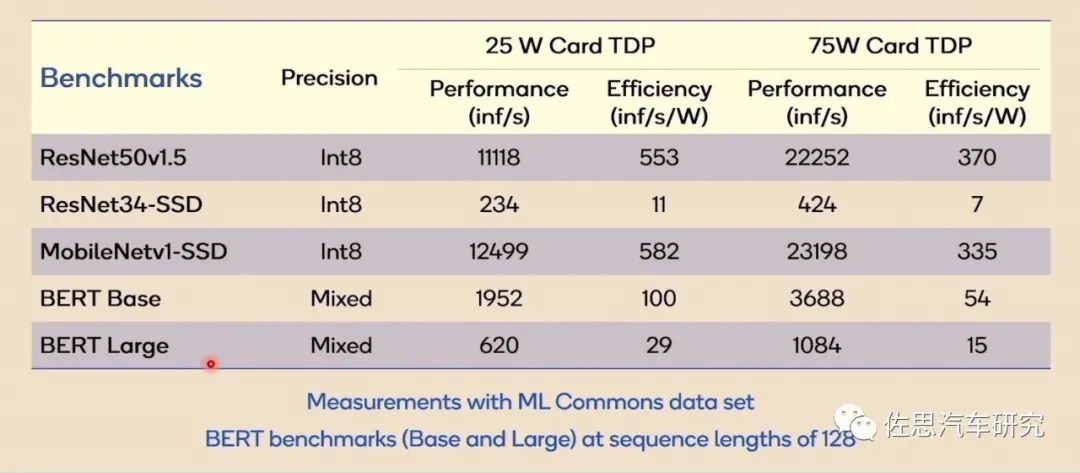
最后说算力,AI处理器对比似乎离不开算力对比,实际单独讲算力数据毫无意义,上图是高通AI100在五个数据集上的表现,我们可以看到性能与效率差别巨大,AI算力越强,其适用面就越窄,与深度学习模型的捆绑程度就越高,换句话说,AI芯片只能在与其匹配的深度学习模型上才能发挥最大性能,换一个模型,可能只能发挥芯片10%的性能,所有AI芯片目前的算力数据都是理论峰值数据,实际应用中都无法达到理论峰值,某些情况下,可能只有峰值算力的10%甚至2%。100TOPS的算力可能会萎缩到2TOPS。

 最前沿的电子设计资讯
最前沿的电子设计资讯

