 Sukednc
Sukednc
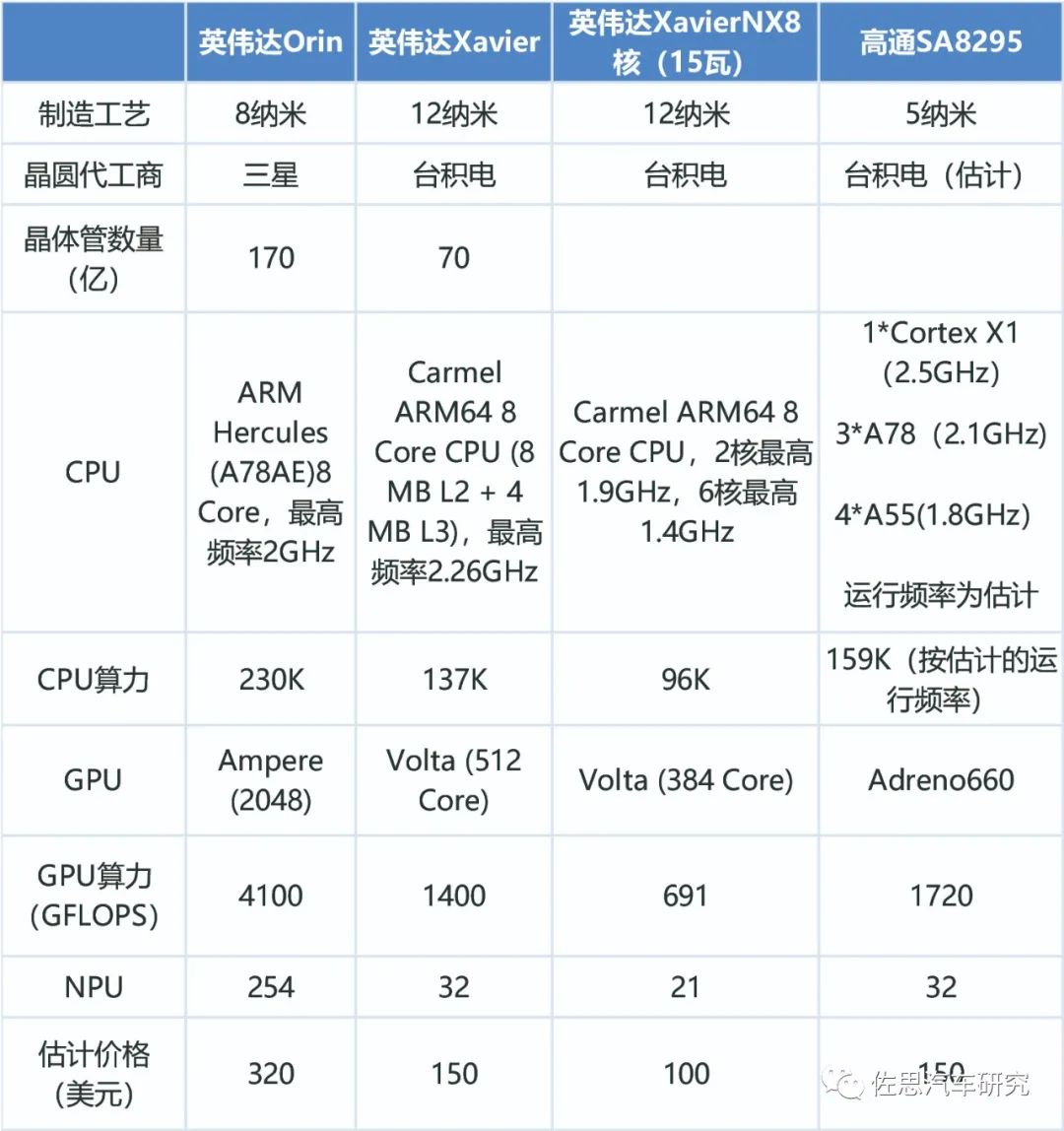
高通8295就是通用汽车2023年的Ultra Cruise用的芯片,基本上就是高通骁龙888的车载版,骁龙888的首发价格大约240美元,目前大约170美元(高通公开资料能查到其MSM芯片出货量与收入,平均价格大约30-35美元),因为大部分成本都已经被出货量两三千万的手机覆盖,因此SA8295价格可以很低。不过高通车载芯片一般都交给台积电代工,台积电代工远比三星价格高(台积电营业利润率几乎是三星晶圆代工业务4倍),估计SA8295价格大约150美元,如果是三星的5纳米,估计价格是120美元或100美元,但高通要外加AI加速器,不过AI加速器价格预计不超过50美元,合在一起,高通仍具备价格优势。
Orin的出货量自然无法和骁龙888比,但三星的成熟工艺,加上有座舱版、游戏机版多个版本分摊成本,价格估计是320美元。不过这个单价意义不大,目前L3/L4智能驾驶车辆价格高昂,而技术迭代很快,产品生命周期越来越短,整个生命周期内的出货量都微乎其微,开发费平摊在每一辆车上的成本远超ECU硬件成本,厂家考虑的是整体成本,特别是软件的成本和一次性费用,对SoC的单价应该不在意,芯片厂家也是推全套方案,软硬件全包。
2021年11月9日,英伟达正式推出采用Orin的模块,即Jeston AGX Orin,这意味着个人用户也可以买到自动驾驶领域的顶级运算模组。当年Jeston AGXXavier的价格是1099美元(现在价格已降到699美元,国内报价大约6千人民币含税),Jeston AGX Orin价格不会太高,估计是1499-1799美元,3年后价格估计也就是1299美元。
 Sukednc
Sukednc
图片来源:互联网Sukednc
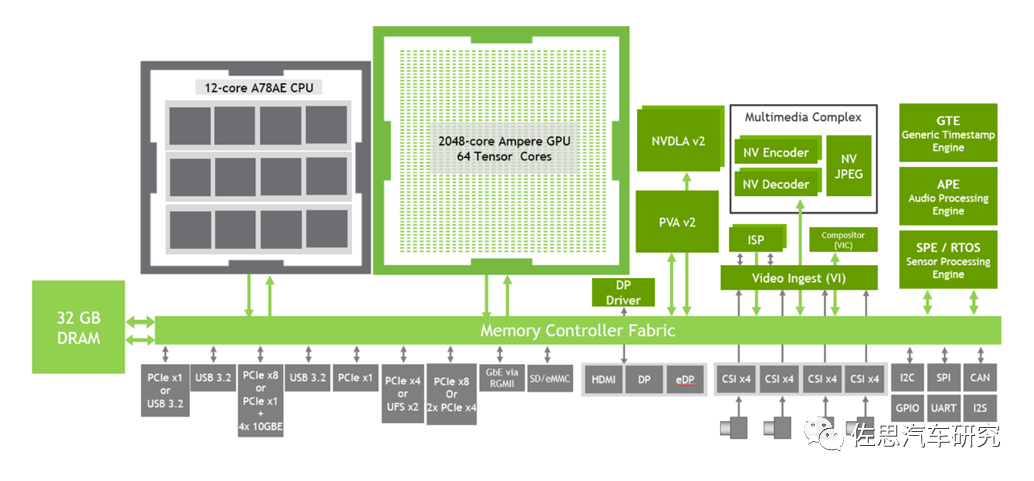
模组里还包括32GB的LPDDR5,带宽有204.8GB/s,价格大约是105美元,近期LPDDR5价格上涨,连苹果13都节约成本用LPDDR4。64GB的eMMC倒是很便宜,目前主要7美元。其余关键的芯片还有一片QSPI NOR和Secure NOR,这两片价格都不高,估计5-8美元。还有电源系统。
 Sukednc
Sukednc
图片来源:互联网Sukednc
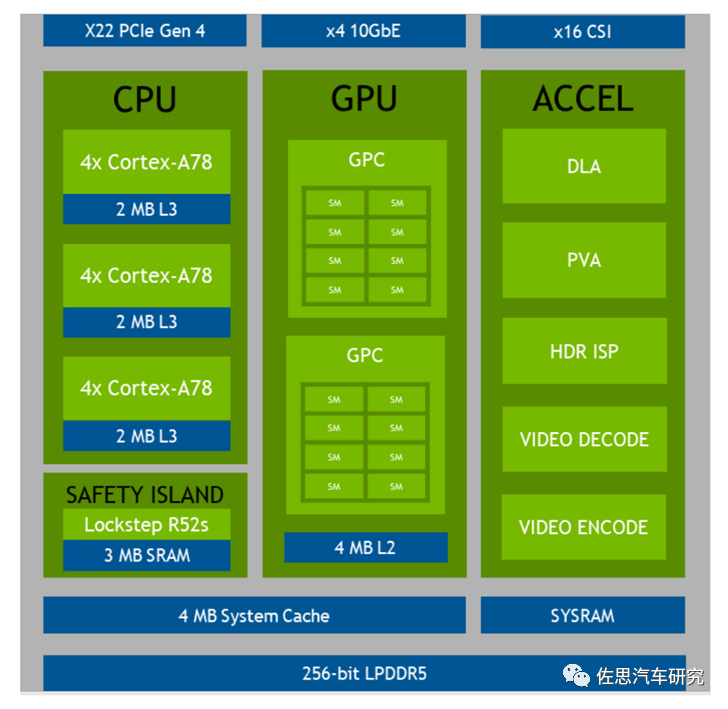
Orin内部框架图,可以简单分为5部分,存储、外围、CPU、GPU和加速器。Sukednc
 Sukednc
Sukednc
图片来源:互联网Sukednc
 Sukednc
Sukednc
图片来源:互联网Sukednc
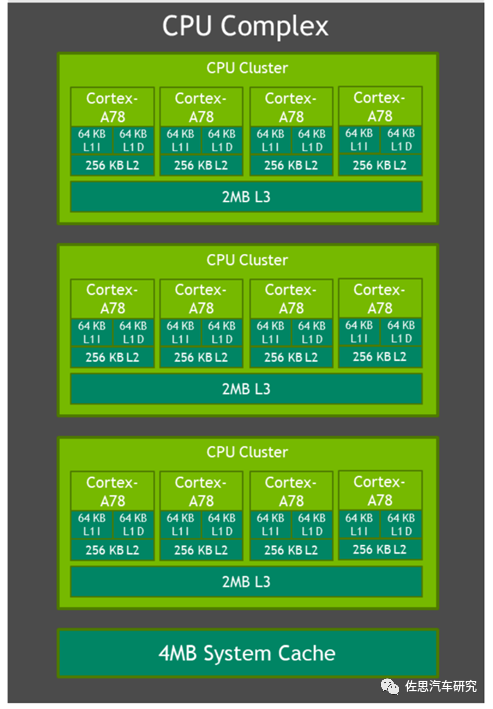
Orin CPU部分框架图,这里的A78应该是A78AE(Automotive Enhanced),即针对汽车领域的A78。ARM建议A78使用5纳米工艺,运行频率2.1GHz-2.8GHz之间。考虑到车规,英伟达将运行频率上限定为2GHz。出于成本考虑,也没使用5纳米工艺,而是使用三星的8纳米工艺,效果与台积电的10纳米差不多。
英伟达放弃了自研的大小核架构,改用ARM的簇架构,这就是ARM在2017年提出的DSU,DynamIQ Shared Unit (DSU)控制单元,其允许最多8个CPU核心构成一个簇(Cluster),单个处理器最多可实现32个簇,这样一个处理最多可以拥有256个核心,并可通过CCIX总线扩展到1000个核心。
英伟达没有公布过Xavier的CPU框架图,应该也是4个核心为一簇,有两个簇,英伟达Xavier的缓存还是有详细说明。
 Sukednc
Sukednc
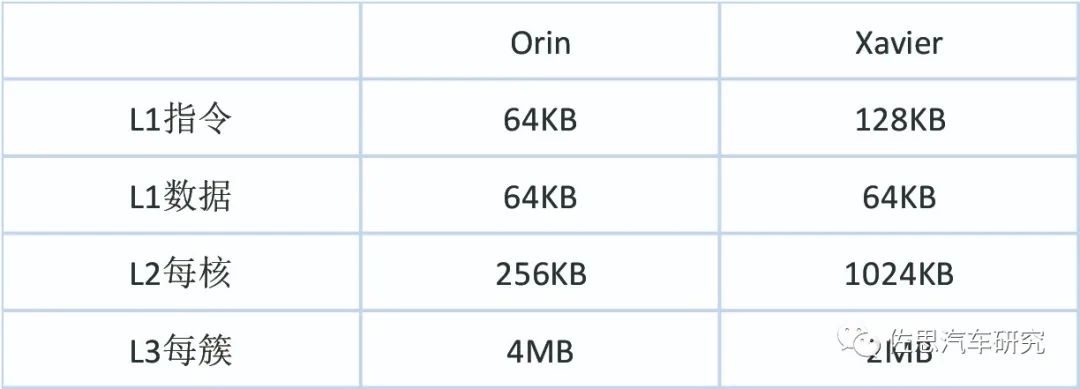
缓存上看,Orin好像比较在意成本,L2和L1的缓存比较小,L3倒是不小。
 Sukednc
Sukednc
图片来源:互联网Sukednc
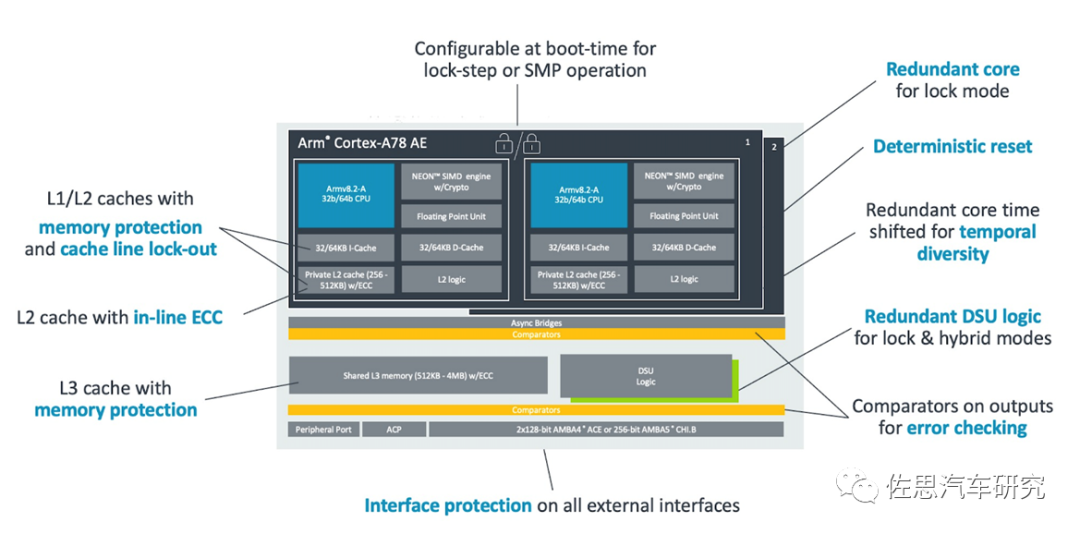
A78AE的内部框架,似乎为了内存保护和锁步,所以L1的缓存容量不高。DSU可以分配各级缓存,还负责控制簇内每个CPU核心开关,频率高低,电压大小,是控制CPU性能与功耗的关键。所以DSU部分做了逻辑控制冗余。这是与消费类A78的主要区别,即添加了DSU-AE。Sukednc
 Sukednc
Sukednc
图片来源:互联网Sukednc
分区模式下,DSU控制每个簇火力全开,锁步模式下,每个簇内都有一核处于休眠状态,一旦监测到异常就启用备份系统。Sukednc
 Sukednc
Sukednc
图片来源:互联网Sukednc
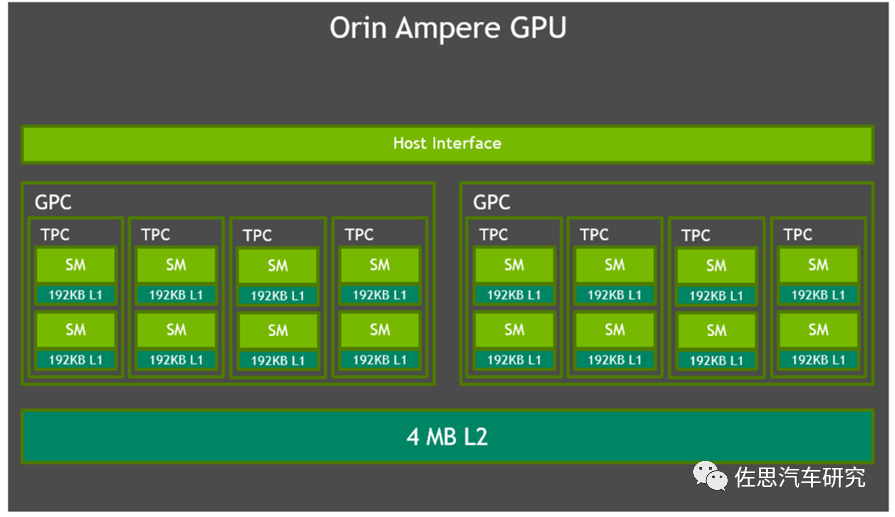
GPU方面,每个流处理器SM包含128个CUDA核,共有16个SM,合计2048个CUDA,算力为4096GFLOPS。还有64个张量核Tensor,稀疏INT8模型下算力达131TOPS,或者密集INT8下54TOPS。
 Sukednc
Sukednc
图片来源:互联网Sukednc
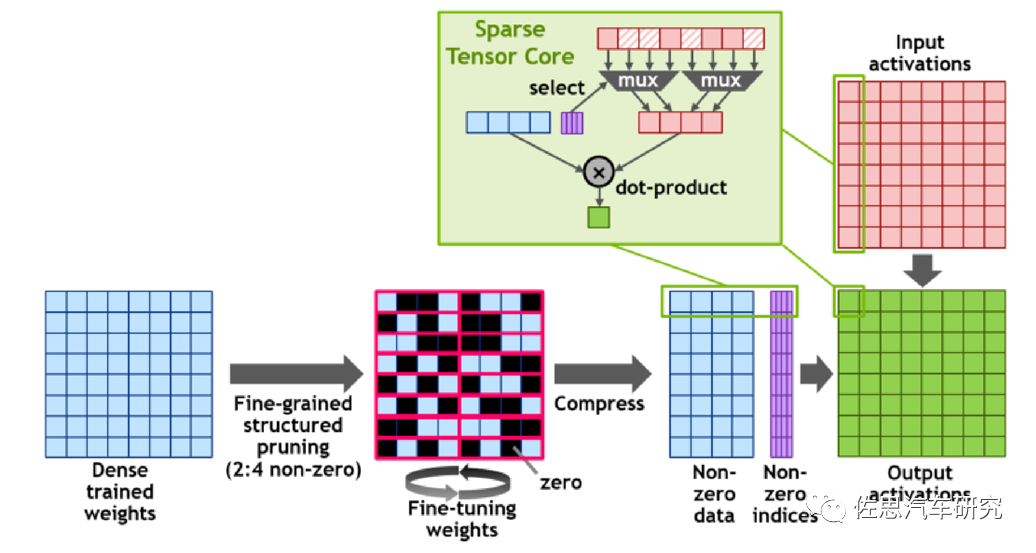
64个张量核采用半精度矩阵乘和累加和集成乘和累加运算指令集,HMMA (Half-Precision Matrix Multiply and Accumulate) 和IMMA (Integer Matrix Multiple and Accumulate),让GPU架构也能对应稠密代数运算和深度学习推理。英伟达采用精细变换权重系统,将稠密训练权重稀疏权重模型。稀疏约束为每4个权重,两个不能为零。经过这样变换后,权重的存取空间大幅度缩小,张量处理还可以跳过零值,速度增加两倍。
 Sukednc
Sukednc
图片来源:互联网Sukednc
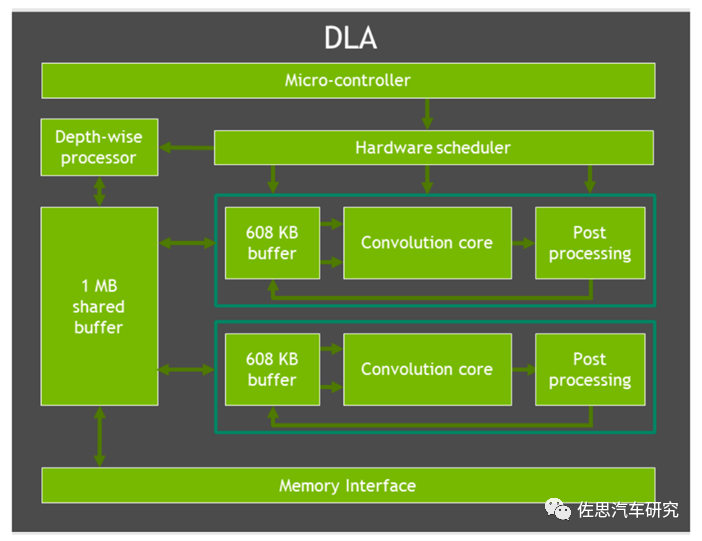
英伟达深度学习加速器内部框架,英伟达的深度学习加速器是针对推理应用的,或许是认为没有什么技术含量,英伟达对DLA介绍的非常简单,寥寥数语,对GPU、CPU、PVA都介绍的很详细。也的确,深度学习加速器没什么技术含量,就是乘和累加运算单元的堆砌。改进之处就是增加了608KB的缓冲,实际应该就是加了608KB的SRAM,提高了运行效率,小模型无需频繁读取DRAM。这个DLA性能为INT8稀疏模型97TOPs,两个是194TOPs。上一代的Xavier是11.4TOPs,不过是稠密模型。
 Sukednc
Sukednc
图片来源:互联网Sukednc
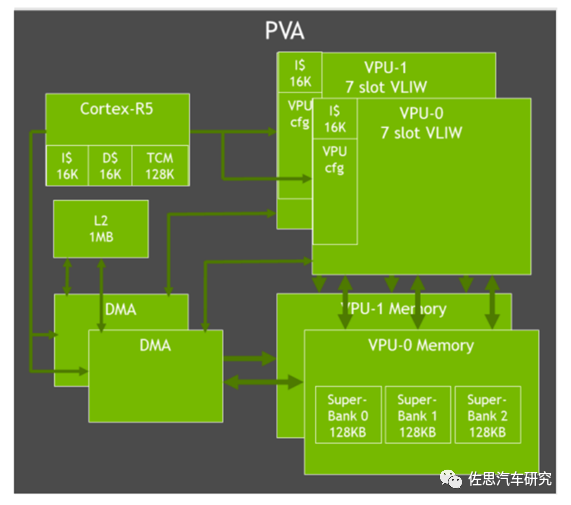
PROGRAMMABLE VISION ACCELERATOR可编程视觉加速器即PVA架构如上图。与Xavier的一代PVA相比,增加了1MB的L2,其余几乎不变。PVA主要针对滤波、扭曲、图形三角生成、特征检测、FFT等矢量运算,具体应用主要是立体双目、特征检测器、特征追踪、目标追踪。包含两个7Slot(两个标量、两个矢量和三个存储)VLIW矢量处理器,两个DMA引擎和一个实时性Cortex-R5。
 Sukednc
Sukednc
图片来源:互联网Sukednc
PVA的典型应用立体双目视差管线。这里特别需要指出英伟达着力推广的VPI,Vision Programming Interface (VPI)是英伟达高性能计算机视觉/图像处理算法库接口。VPI为各种不同的硬件提供统一的接口,如CPU, GPU, Programmable Vision Accelerator (PVA), 以及Video Image Compositor (VIC),而且提供方便调用的GPU并行功能。
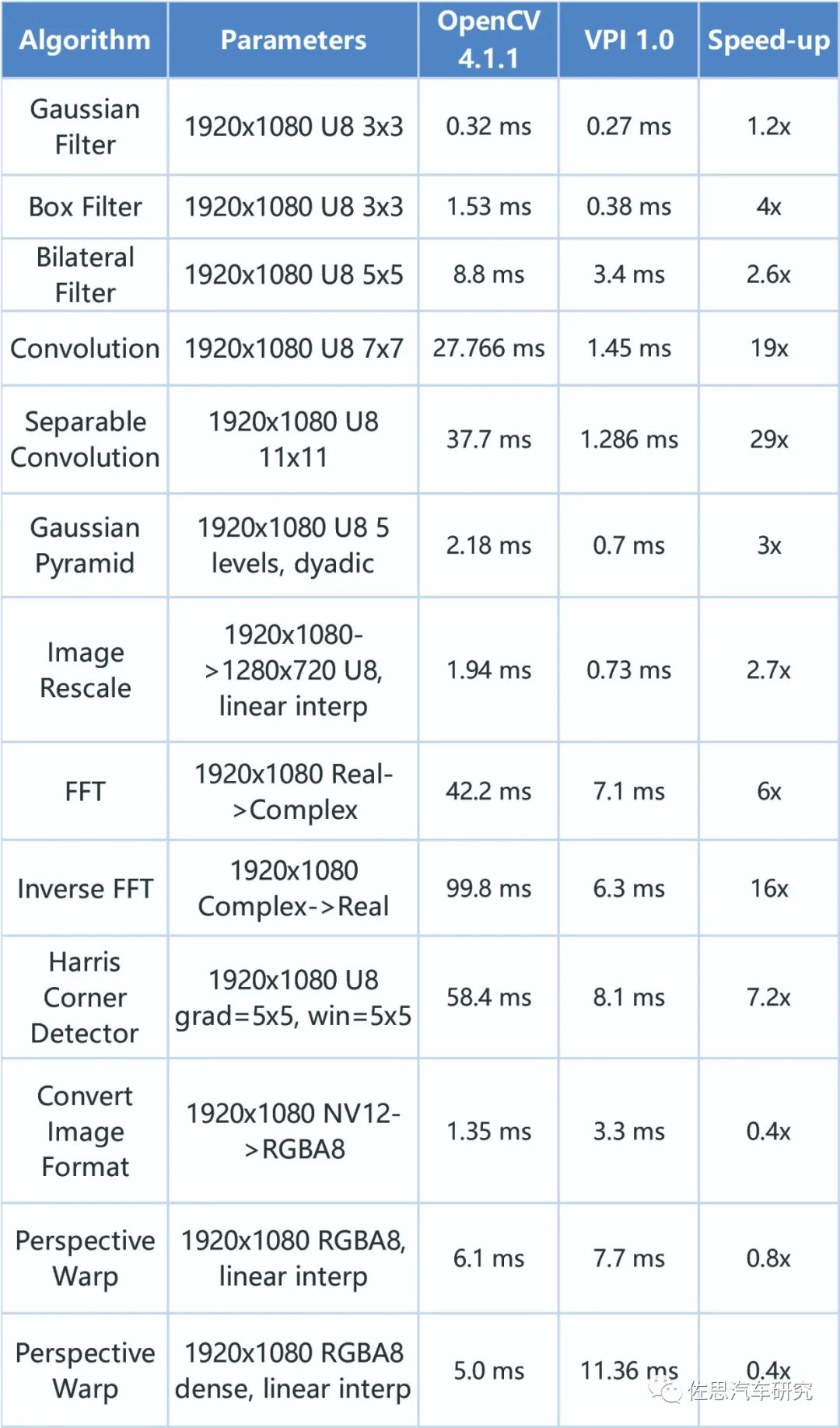
支持的算法包括高斯金字塔发生器,拉普拉斯金字塔,可分离图像压缩器,箱式图像滤波器,高斯图像滤波器,双边图像滤波器,图像重新缩放,图像重映射,图像直方图,直方图均衡化,快速傅里叶变换,逆向快速傅里叶变换,图像格式转换器,透视翘曲,背景减法,镜头失真矫正,时间性降噪,金字塔式LK光学流,及本身常用算法都包括了。
英伟达VPI似乎有意取代OpenCV,在英伟达的计算平台上,VPI比OpenCV明显要快。
 Sukednc
Sukednc
某些移动端如可分离卷积Separable Convolution,效率提高29倍。
英伟达用CUDA垄断深度学习,下一个目标就是用VPI垄断计算机视觉算法。
 Sukednc
Sukednc
图片来源:互联网Sukednc
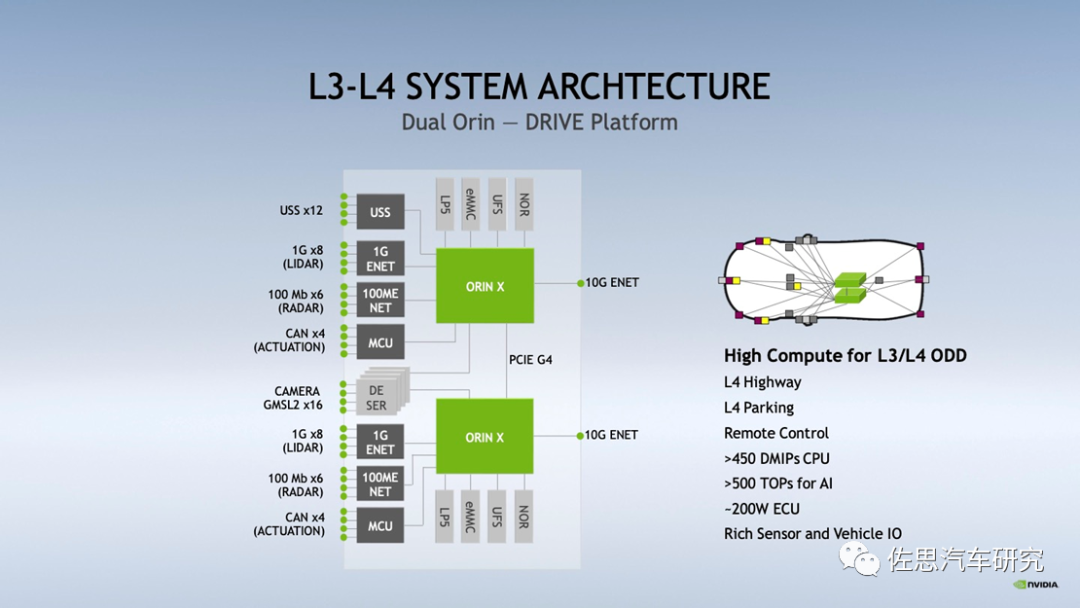
接口方面,最高提供6个CSI摄像头接口,看起来似乎不多,通过虚拟通道可以增加到16个。一般自动驾驶都是使用双Orin,16个MIPI CSI通道也就是4个800万像素,双Orin是8个800万像素。
 Sukednc
Sukednc
图片来源:互联网Sukednc
接口基本上就是对应上图的架构,16个400万像素摄像头,8个激光雷达,通过1个1G的以太网。两个10G的以太网连接上骨干网和交换机。
与Xavier比,Orin的AI算力主要来自DLA,而Xavier则是GPU。从简单的裸晶图片看,下一代的Atlan应该又重回Xavier路线,AI算力主要来自GPU,GPU的面积远比DLA要大,因为增加了一个DPU模块,DLA的面积被大幅度压缩了。下一代GPU架构代号或许是Ada Lovelace,阿达·洛芙莱斯(Ada Lovelace)是人类第一个程序员,英国著名诗人拜伦之女,数学家。
Orin的完成度感觉不高,特别是CPU,加上A78后ARM的一系列新技术,苹果、三星、英特尔甚至联发科都有能力挑战Orin,问题是相对手机和PC,L3/L4智能汽车市场太小了,且要提供全套解决方案,后进厂家在软件方面花费巨大,这就让Orin几乎垄断市场。国产芯片要想挑战Orin,必须购买ARM的最先进架构,还有采用至少5纳米的先进工艺,这导致一次性成本至少是1亿美元,芯片的整体开发成本预计在2亿美元以上,整个生命周期内出货量即使10万辆,单SoC的成本都要2000美元,显然这个价格是车厂无法接受的。任何企业想单靠汽车市场挑战Orin是完全不可能的。

 最前沿的电子设计资讯
最前沿的电子设计资讯

