
具有驾驶辅助功能的现代汽车本质上是安全的。严格的安全要求和自动驾驶功能的引入,增加了对汽车内计算和通信系统的要求。汽车开放系统架构(AUTOSAR)自适应平台的目标是,通过支持高性能计算设备和高带宽通信技术来满足这些行业要求。AUTOSAR自适应平台利用了扩展的面向服务的IP中间件SOME/IP(Scalable service-Oriented MiddlewarE over IP),这是一个汽车中间件解决方案,支持在不同规模和操作系统的不同设备之间交换控制信息。通常,为了保证软件的安全运行,汽车会对关键的软件任务进行冗余处理,以容忍永久的崩溃故障。自适应 AUTOSAR 标准没有规定任何容错要求。在本文中,我们指出了当前AUTOSAR自适应平台标准(第18.10版)中的一些缺口,并提出了弥补这些缺口的建议。我们提出了一个框架,该框架中使用不同的复制策略支持AUTOSAR自适应平台的容错执行。对使用SOME/IP的应用程序,分析了我们的解决方案的故障检测和恢复时间的界限。我们对模型进行了实验验证,并给出了评价结果。
随着计算系统、传感器技术和机器学习技术的发展,各种先进的辅助驾驶和自动驾驶功能在现代自动驾驶汽车中已经切实可行了。这些功能极大地增加了汽车中使用的计算资源的数量和复杂性。此外,本质上,汽车最关键的就是安全。严格的安全要求只会进一步增加汽车系统的复杂性。汽车开放系统架构(AUTOSAR)经典平台(CP)标准是一个广为人知的的汽车电子控制单元(ECU)的标准化软件架构,它只能解决深度嵌入式低复杂度设备的需求。因此,经典平台无法满足上述现代汽车系统的复杂需求。因此,AUTOSAR规定了第二个软件平台,即AUTOSAR自适应平台,以满足这些行业要求。
AUTOSAR适应性平台主要提供高性能的计算和通信机制。它还能提供灵活的软件配置,例如,支持软件的空中更新。对电子信号和汽车专用总线系统的访问等一些为经典平台专门界定的功能,也可以集成到自适应平台中。
与AUTOSAR经典平台相比,自适应平台支持面向服务的架构(SOA),SOA允许在运行期间动态链接服务和客户端,使其对应用程序开发人员来说更加灵活。自适应平台支持众核处理器和提供并行处理的异构计算平台,以及快速和高带宽通信技术,如以太网。自适应平台还支持一些安全和安保功能,如基于优先级的调度、执行经过验证的代码以及控制内存和CPU资源的分配。
为了支持各种设备的可扩展性,AUTOSAR自适应平台利用了可扩展的面向服务的IP中间件(SOME/IP)。SOME/IP是一个汽车中间件解决方案,可用于发送和接收控制信息。它被设计用来支持不同大小和不同操作系统的设备。这包括小型设备,如相机、AUTOSAR设备、远程信息处理设备和信息娱乐设备。典型的中间件解决方案通常只支持单一的功能(如RPC或发布/订阅),而SOME/IP支持很多功能,包括序列化、远程过程调用(RPC)、服务发现(SD)、发布/订阅(Pub/Sub)和UDP消息的分段。与其他中间件解决方案(如DDS)不同,SOME/IP 不支持通过抽象(如服务质量)来实现可靠性的概念。数据传输的可靠性和及时性是保证系统安全的重要条件。
通常情况下,为了保证软件的安全运行,汽车会对关键的软件任务进行冗余处理,以容忍永久的崩溃故障。冗余可以有很多类型,但大致可以分为并发冗余和非并发冗余。并发冗余意味着主应用程序和冗余版本同时在功能上运行(活动副本属于这一类),而非并发冗余意味着冗余组件监控主应用程序的状态,只有在主应用程序失败时才开始执行完整的功能。
自适应 AUTOSAR 标准没有规定任何容错要求。在本文中,我们指出了当前AUTOSAR自适应平台标准(第18.10版)中的一些缺口,并提出了弥补这些缺口的建议。介绍了为支持AUTOSAR自适应平台的这些复制策略而设计的软件容错框架。针对使用SOME/IP进行通信的应用程序,分析了该框架的故障检测和恢复时间界限。本文的其余部分结构如下。
第二节,我们介绍了相关的工作。
第三节,介绍了我们的系统和故障模型。
第四节,描述了在AUTOSAR自适应平台上支持容错执行的框架,并分析了使用SOME/IP的应用程序在不同复制策略下的故障检测和恢复时间表现。
在第五节,描述了我们的实验设置,并展示了评价结果,
随后在第六节进行了总结。
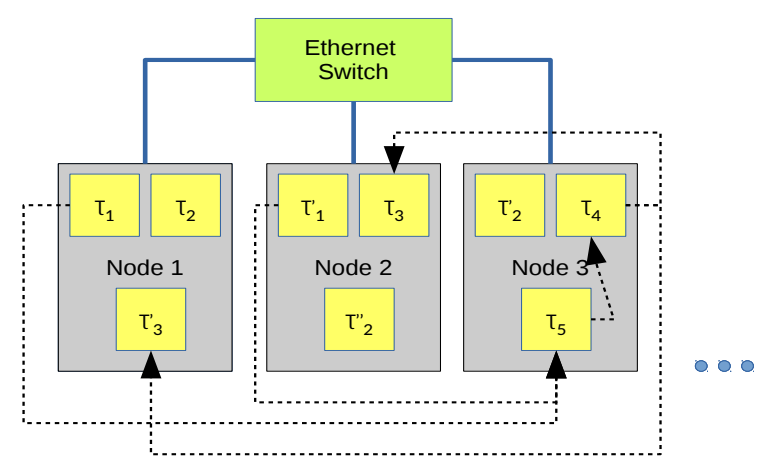
图1: 系统模型
本文提出了一种部署实时软件的方法,旨在为处理器生成可行的任务分配。他们还提出了在AUTOSAR中检测故障节点和激活重新配置的概念。提出了热备和冷备处理器的R-FLOW算法,以支持具有约束恢复时间的容错。然后,他们在AUTOSAR中整合该算法,以提供可靠性。Lu等人提出了一种反射原理的方法来实现AUTOSAR中的容错。该方法引入了具有信息记录、检查和恢复功能的防御软件。该防御软件需要访问操作系统,以便监控操作系统级别的控制和数据流。提出了一个框架,支持 AUTOSAR 经典平台的容错执行。Fabre 等人提出了一种多级反射方法,以实现使用 AUTOSAR 作为中间件的容错和鲁棒性。这种功能和非功能软件的多层次结构可作为自检组件。在低级别的通信框架上也有容错的考虑,如Flexray和以太网。
另一方面,本文首次介绍了在使用SOME/IP框架的AUTOSAR自适应平台面向服务的架构中,对容错支持的系统设计和分析。
本节介绍了我们的计算模型和故障模型。
A. 计算模型
计算模型由几个运行自适应AUTOSAR平台的节点组成。假设这些节点通过交换式以太网网络相互连接。如图1所示,每个节点运行几个软件应用,也被称为任务。每个任务τ,既可以是几个客户端的服务器端,也可以是几个服务的客户端。例如,任务τ5既是任务τ4的服务器端,又是任务τ1的客户端。
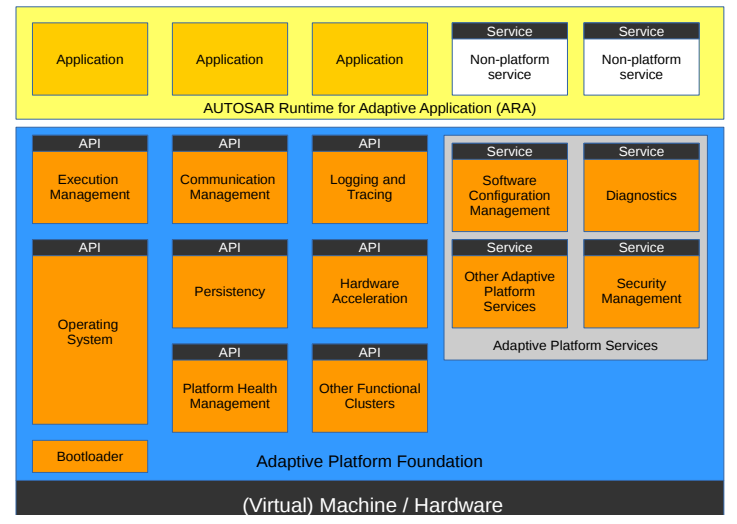
图2: 自适应 AUTOSAR 平台架构
图2展示了AUTOSAR自适应平台的架构。自适应应用程序(AA)运行在ARA之上,ARA即自适应应用程序的AUTOSAR运行时间。ARA由功能集群提供的应用接口组成,这些功能集群属于自适应平台基础(APF)或自适应平台服务(APS)。APF提供AP的核心功能,APS提供辅助服务。任何AA也可以向其他AA提供服务,如图中显示的非平台服务。操作系统负责自适应平台上所有应用程序的运行时资源管理(包括时间)。执行管理(EM)负责系统执行管理的所有方面,包括平台初始化和应用程序的启动/关闭。通信管理(CM)负责分布式实时嵌入式环境中应用程序之间通信的所有方面。在本文中,我们假设CM利用SOME/IP堆栈来管理应用程序之间的通信。
假设系统中的所有任务都使用SOME/IP服务发现(SOME/IP- SD)来提供和订阅服务,SOME/IP- SD允许所有的应用程序在启动时动态地设置通信路径。
B. 故障模型
故障模型假定,在系统中各个节点上运行的任务以及节点本身,都可能会遭受故障停止的情况。换句话说,当一个任务正在运行时,假设它产生的每条消息都是正确的,并且在失败时,它将停止发送消息。通常情况下,电源子系统的问题、硬件故障和软件内存故障会导致崩溃故障,从而导致这种故障-停止。像看门狗这样的监控硬件单元也有助于确保故障-停止行为。为了容忍崩溃故障,必须复制任务。我们考虑了两类冗余:并发冗余和非并发冗余。一个任务可以有一个或多个副本。这意味着多个不同的任务可以提供相同的服务器端,多个相同的客户端可以利用同一服务器端。如图1所示,任务τ5由τ1的两个副本提供相同的服务,任务τ3的相同副本利用任务τ4提供的服务。我们的容错框架还假定,通过使用以太网TSN,底层通信框架的最坏情况下的消息传输延迟约束是可以分析的。
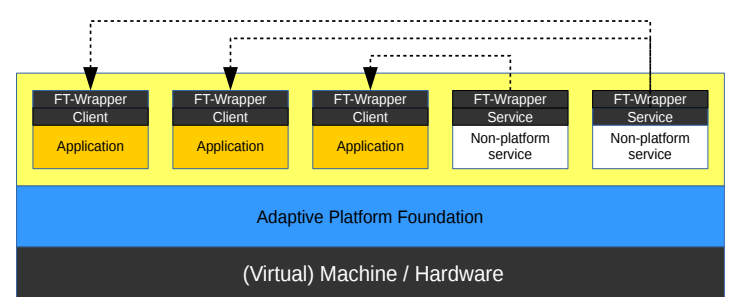
图3: 系统设计
本节介绍了本文的主要贡献:AUTOSAR自适应平台容错支持系统设计。图3显示了设计的高级视图。我们为客户端和服务器端设计并实现了一个容错包装,使他们不需要考虑容错问题。在应用层中保持对容错的支持,可以在不同类型的平台和应用中实现可移植性。我们考虑对以下SOA元素/抽象的支持,这些元素/抽象组合在一起构成了所提供的服务:
1) 事件: 从服务器端向客户端发送的通知。
2) 字段: 字段抽象支持三种操作:set:为数据元素赋值,get:检索数据元素的值,notify:通知客户端数据元素值的变化。
3) 方法: 由服务器端代表客户端执行的远程过程调用。
根据服务器端和客户端之间消息交换的单向性或双向性,这些SOA抽象可以大致分为两类。
1) 基于通知的抽象:事件和字段——通知抽象只会导致从服务器到客户端的单向消息传输。
2) 基于请求-应答的抽象:字段set、字段get和方法抽象导致了服务器和客户端之间的双向消息传递。
在设计中,我们考虑了以下的复制需求,以满足系统的安全保证。
1) 服务器可能故障:多个任务必须提供相同的服务。这些服务可以是相同的副本,也可以是另一个服务的降级副本。客户端必须能够定位、订阅和使用服务的所有副本,允许隐式故障处理。
2) 客户端可能故障:多个任务必须充当客户端。服务器必须能够处理来自多个相同客户端的命令和请。
目前的自适应 AUTOSAR 标准(第18.10 版)没有规定对容错支持的要求。在标准中定义容错要求,对于平台功能集群(如执行管理和通信管理)尤其重要,因为这些组件的故障可能是灾难性的。将这些复制需求映射到上面描述的SOA抽象中,我们需要考虑以下事项:
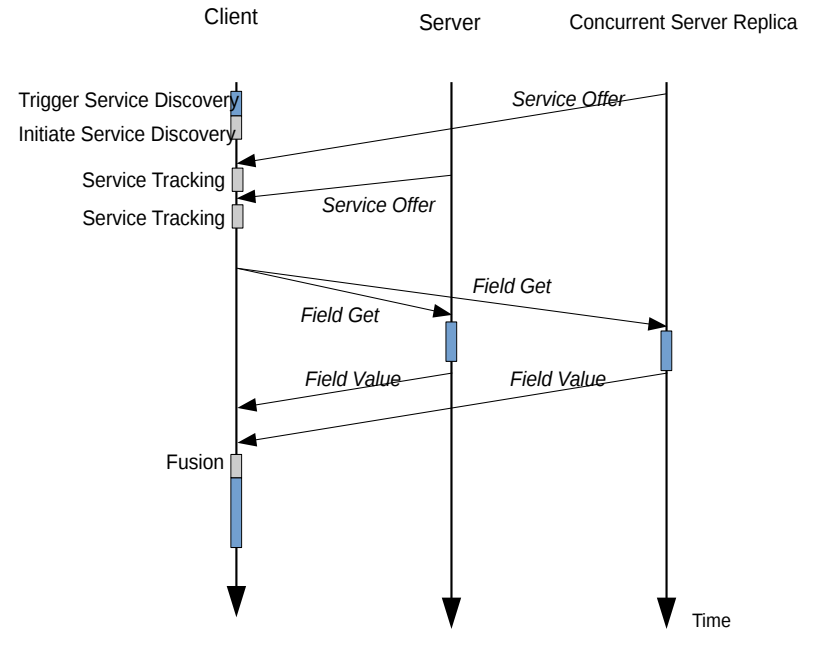
图4: 可靠客户端抽象化
1) 客户端处理:事件、字段-get和字段-通知的抽象只在客户端修改数据,因此容错支持只适用于客户端。
2) 服务器端处理:字段-set抽象只在服务器端修改数据,因此容错支持只适用于服务器端。
3) 客户端和服务器端处理:方法抽象可以修改服务器端和客户端的数据,因此容错支持同时适用于服务器端和客户端。
A. 容错的API设计
考虑到不同的抽象需要在客户端(Client)和服务器(Server)端进行不同类型的处理,我们开发了两个新的抽象:ReliableClient和ReliableServer,客户端和服务器可以分别使用它们来支持容错操作。我们将这些抽象实现为FT库的一部分,所有软件应用程序都可以使用。FT库支持以下功能:
1) 数据时间戳:每个来自服务器端或客户端的请求和应答都被打上最新的全局时间戳。
2) 复制信息:来自服务器端或客户端的每个请求和应答都附加了对容错支持至关重要的数据,如复制类型、状态和任务以及节点id。
3) 唯一标识符接口:FT库支持一个序列号接口,该接口可由客户和服务器应用程序覆盖,为请求和应答提供唯一的序列号。在汽车方面,由于大多数应用程序都要处理来自传感器的数据,因此可以使用传感器包序列号和复制信息为每个请求或应答创建一个惟一的标识符。
我们现在来介绍可靠客户端和可靠服务器抽象,并详细描述它们。
B. 可靠客户端
ReliableClient抽象向客户端公开了以下三个API。
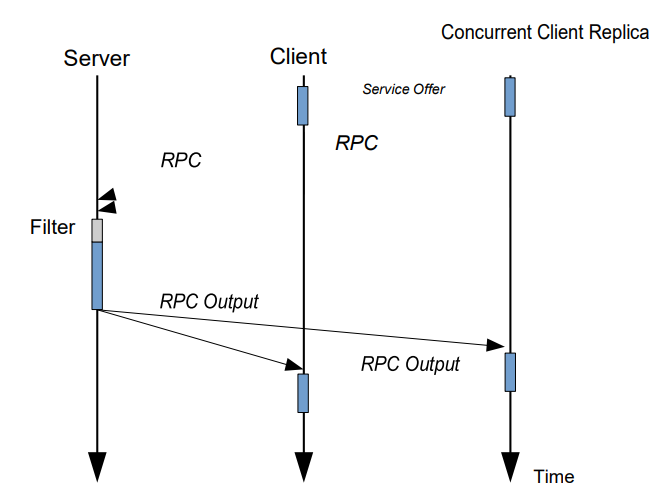
图5:可靠服务器抽象化
1) 服务发现接口: 该接口允许客户机发起服务发现调用,以连接到特定的服务ID。ReliableClient 使用指定的 serviceID 建立与所有服务的连接并维护它们的状态。
2) 融合接口: 这个接口允许客户端提供一个自定义的融合策略,以便在请求的服务ID存在重复的服务器时应用。如果融合策略需要,ReliableClient使用唯一标识符和时间戳基元来识别重复的输入。
3) 请求接口: 这个接口允许客户端进行单一的请求调用,并将其转发到由ReliableClient维护的所有服务器。
图4展示了一个使用ReliableClient API的客户端应用程序的例子。客户应用通过服务发现接口启动服务发现。ReliableClient连接到所有可用的服务并保持其状态。然后,客户端应用程序设置一个融合策略并通过请求接口提出请求。对于来自服务器的回复,ReliableClient会执行融合策略并返回结果。
C. 可靠服务器
ReliableServer抽象化向服务器应用程序展示了以下API。
1) 过滤器接口: 这个接口允许服务器提供一个自定义的过滤策略,以便在重复的客户端请求相同的服务时应用。如果过滤策略需要,ReliableServer使用唯一标识符和时间戳原语来识别重复的输入。
图5介绍了一个使用ReliableServer API的服务器应用程序的例子。服务器接受一个过滤策略,在收到客户端的请求时,如果有必要,就执行该过滤策略,并将输出返回给所有相同的客户端。
如前所述,副本可以是并行的,也可以是非并行的。这两种类型的复制策略都可以利用ReliableClient和ReliableServer的抽象性。有了始终处于运行状态的并发副本,API就可以不加改变地被使用。对于非并行副本,只有在主站故障时才开始运行,有必要检测主站的故障。对于服务器,我们通过让副本订阅主服务来利用 SOME-IP/SD。对于不提供服务的纯客户端,ReliableClient 提供的服务只是为了与副本交换健康消息。当主站点发生故障时,副本因此能够检测到服务的故障,从而可以开始提供服务。需要注意的是,尽管非并行副本是非操作性的,但它们确实参与了服务的发现,它们只是在主要故障之前不实施服务而已。
D. 故障检测的时间分析和服务故障的恢复
在汽车上运行的安全关键应用程序必须及时地从故障中重新获得恢复,以满足所需的安全保障。在本节中,我们分析了不同副本类型的容错行为,并确定了在出现故障时达到所需安全水平的控制旋钮。
对于给定的任务 τ ,让 Trecthres 表示在违反安全保证之前,所提供的服务可以承受的保持不可用的最长时间。对于基于请求-回复的抽象化来说,这是在提出请求到执行请求之间所能承受的最长时间。对于基于通知的抽象化来说,这是一个服务器无法产生通知的最长时间。让Trecmax代表一个任务的恢复时间的最大值。因此,如果Trecmax < Trecthres τ,我们假设系统在出现故障时满足其安全要求。
我们首先介绍了SOME-IP/SD阶段的概况,以描述一些重要的系统控制参数。在SOME-IP/SD中,服务发出供应消息以提供网络内的服务,而客户端发出查找消息以定位网络内的服务。这发生在三个阶段:初始等待阶段、重复阶段和主要阶段。
1) 初始等待阶段(IWP): 在这个阶段,客户端在控制参数 CliDelIW Pmin 和 CliDelIW Pmax 之间的随机时间内保持沉默。在控制参数SerDelIW Pmin 和 SerDelIW Pmax之间,服务器也随机保持沉默。如果客户端在这个阶段收到一个服务器的指示,它就直接跳到主阶段。
2) 重复阶段(RP): 在这个阶段,客户端开始发送查找信息。每两条查找信息之间的时间连续增加,直到CliFindMsgMax给出的最大查找信息数量。两个查找信息之间的延迟可以通过设置控制参数CliRepDel来控制。客户端在接收到供应信息时过渡到主阶段。除了对接收到的查找消息的反应外,服务器的行为几乎与客户端完全相同。在这种情况下,服务器在预定范围内等待控制参数SerDelRPmin 和 SerDelRPmax之间的一个随机量,并发出一个单程供应信息。如果达到由控制参数SerFindMsgMax设定的供应信息数量,并以SerRepDelRP给定的速度,服务将过渡到主阶段。
3) 主要阶段(MP): 在这个阶段,客户端保持沉默,服务器继续发送供应信息,以表明其在控制参数SerRepDelMP 设定的时期内的可用性。
为了分析故障恢复行为,上述SOME-IP/SD阶段可分为以下两个不同阶段。
1) 客户端和服务器之间没有建立连接:如果在建立连接之前服务失败,必须重新启动服务。
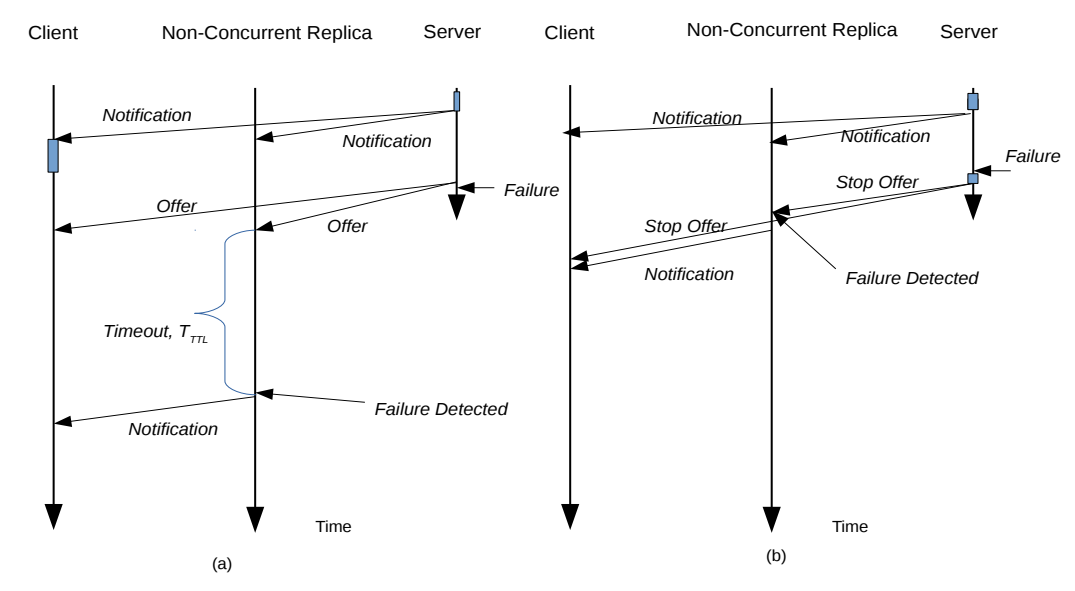
图6:提供基于通知的服务的非并行副本的恢复示例
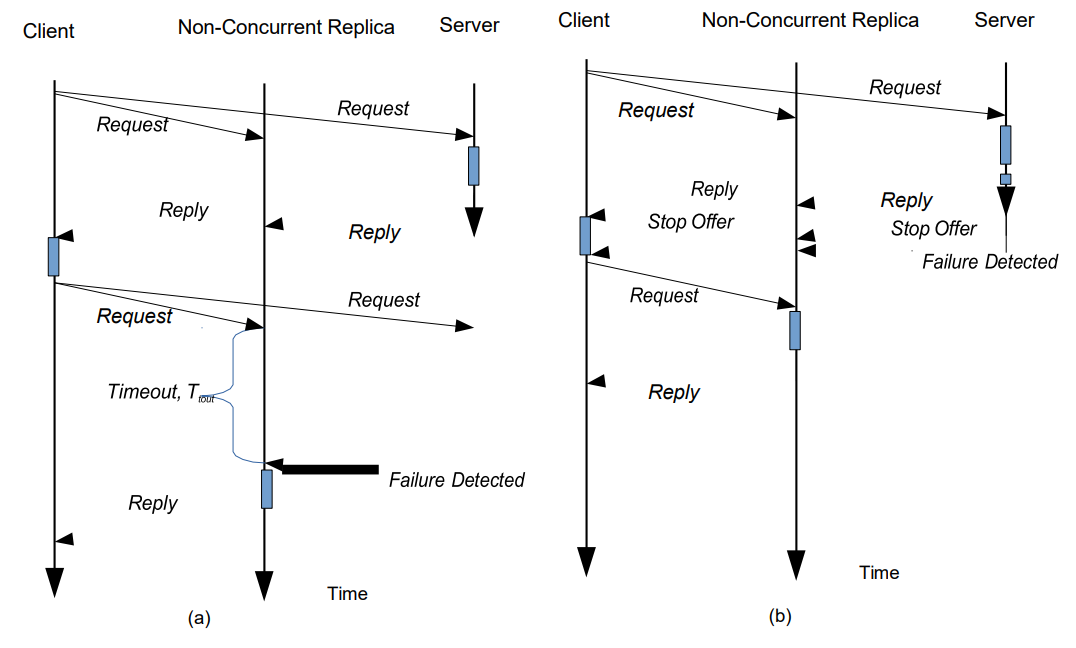
图7: 提供基于请求-回复的服务的非并行副本的恢复实例
在自适应平台中,这可以通过平台健康管理和执行管理功能集群来完成。
平台健康管理集群在进程启动时设置一个HW看门狗程序。
如果进程启动失败并且HW看门狗过期,执行管理被触发以重新启动进程。令 Twd为看门狗定时器的到期持续时间,令 TEM 表示执行管理集群重新启动进程所用的时间。让Tconnect表示与在服务器和客户端之间建立连接相关的启动延迟,启动延迟界限的正式推导在文献中推导。可以使用上述控制参数来控制此延迟界限。因此, 恢复所需的最长时间为,
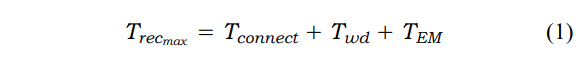
任务可能在多次重试时未能启动。在这种情况下,如果Trecovery > Trecmax,平台健康管理(PHM)功能集群应该能够在执行管理的帮助下触发适当的操作。对PHM定义的一个重要补充是允许根据看门狗定时器过期的次数来采取不同的行动。
1) 客户端和服务器之间形成成功连接后:对于并行的副本,如果至少有一个副本成功连接,则故障的处理是隐性的。
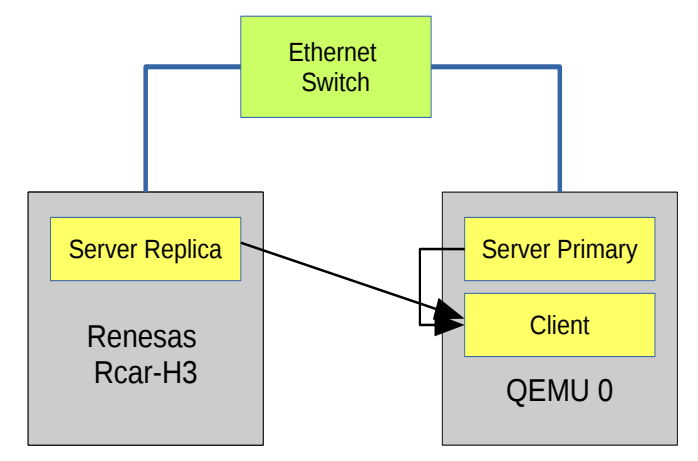
图8: 实验装置
对于非并行复本,如果一个服务在连接后发生故障的时候,有两种可能的结果,一种是故障被处理,另一种是未被处理。
如果一个进程能够处理故障,例如通过捕捉一个SegFault信号,它可以触发适当的备份机制。如果进程无法处理故障,例如在电源故障的情况下,则无法触发任何备份操作。
图6a展示了一个基于通知的抽象的恢复例子,其中有非并行复本的未处理的故障。最坏情况下的恢复发生在服务刚刚在其主要阶段产生一个表明其可用性的供应消息之后就发生故障了。SOME-IP/SD中的每个服务供应信息都配置了一个生存时间(TTL)标志。在这个TTL标志到期时,副本可以认为主服务器失败,并作为新的服务器接管。如果Tcomm为从服务器发送数据包到副本的时间,则恢复时间为,
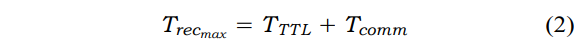
在处理失败的情况下,如图6b所示,服务器可以发出一个停止供应消息,向副本表明服务器即将失败,因此它可以接管执行。让Tsig代表处理异常信号所需的时间。
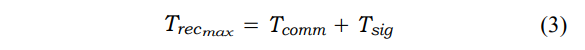
图7a,展示了一个基于请求-回复的抽象的恢复例子,其中有非并行副本的未处理故障。每个Reliableclient都会启动一个设置为Ttout的定时器,计时器与每个请求关联。这个定时器值的选择是允许主站处理请求并回复给客户端。如果定时器过期,客户端可以认为服务器失败,并接管新的服务器。因此,
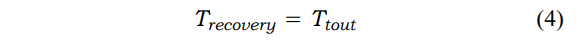
在处理故障的情况下,如图7b所示,服务器可以发出一个停止供应消息,向副本表明服务器即将失败,这样它就可以接管执行;因此,
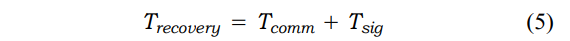
我们描述了我们的实验设置并展示了我们的评估结果。如图8所示,我们有一个双节点系统,每个节点都在运行Elektrobit的AUTOSAR
表I: 控制参数
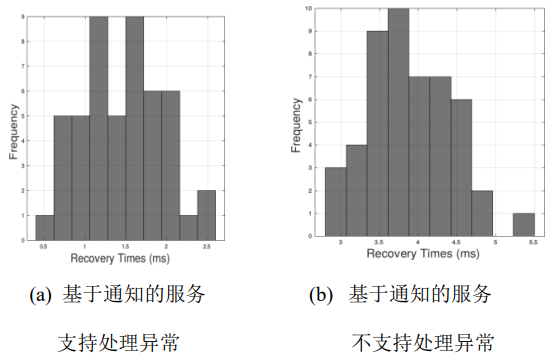
图9: 实验评估
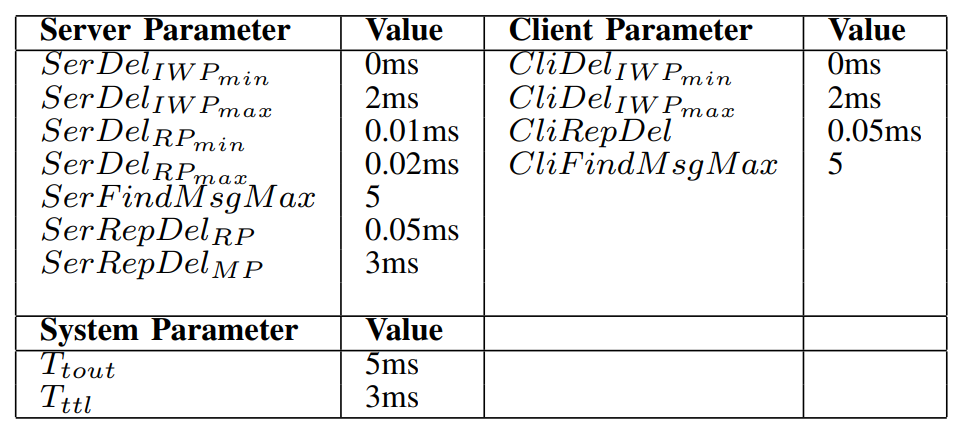
自适应平台执行指令,其大部分内容符合18.03自适应AUTOSAR标准。其中一个节点是Renesas的R-Car-H3开发套件,另一个是在X86笔记本电脑上的Qemu模拟器上运行的虚拟实例。这两个节点通过100Mbps速率的以太网交换机进行通信。我们创建一个服务器客户端的示例进行测试。服务器和客户端都使用ReliableServer和ReliableClient 应用程序接口。该服务由非共同定位的副本复制。实验中选择的控制参数如表1所示。
A. 基于通知的服务
在第一个实验中,所提供的服务产生周期性事件,并支持处理异常的机制。我们注入人工故障,呈现为分段故障。图9a列出了结果。由于故障得到了处理,主站点能够在副站发生故障之前触发副站来接管。
在我们的下一个实验中,提供的服务会产生周期性事件,但不支持处理异常的机制。我们通过断开RCar-H3板与电源的连接来注入人工故障。图9b展示了结果。由于故障没有被主站处理,所以它无法触发副站。副站必须产生一个额外的 Tttl 延迟才能检测到服务的故障。因此,与处理过的故障相比,恢复需要的时间更长。
B. 基于请求-回复的服务
在我们接下来的实验中,所提供的服务支持远程过程调用和异常处理的机制。客户端任务周期性地发出带周期的RPC(远程过程调用协议)请求。我们在服务中注入人工故障,呈现为分段故障。由于故障得到了处理,主站能够在副站发生故障之前触发副站来接管。
我们注意到,在大多数实际情况下,恢复是隐性的,因为在客户端提出新的请求之前,副站就已经接管了主系统。
接下来的实验中,所提供的服务支持远程过程调用,但不支持处理异常的机制。我们通过断开RCar-H3板与电源的连接来注入人工故障。由于故障没有被主站处理,所以它无法触发副站。副站等待,直到计时器Ttout过期,它才能宣布服务失败并回复RPC请求。
 最前沿的电子设计资讯
最前沿的电子设计资讯

