
在特斯拉AI Day发布会上,Dojo这个特斯拉自己定制超级计算平台,它的出现是从头开始构建,用于自动驾驶视频数据进行视频训练。主要两个目的:其一是比市售云计算更便宜;其二是比市售云计算更强大——从某种意义上,特斯拉和Jeff Bezos 是不对付的,所以特斯拉是希望与亚马逊 AWS 相提并论,使用在线提供的服务,可以用更少的钱、更快地训练模型。
特斯拉已有是基于 NVIDIA GPU 的大型超级计算机,新的 Dojo 定制计算机,是在设计层面做有效的突破。

▲图1. Dojo的计算效果
Dojo Exapod规格:1.1 EFLOP、1.3 TB SRAM 和 13 TB 高带宽 DRAM。
从设计之初,硬件层面要为深度的神经网络训练做考虑,从芯片到机组再到机房的传输带宽都是非常扩展,将Occupancy网络应用于Dojo系统之中,实现了AI硬件与AI软件的更佳匹配,最后在降低延迟和性能损失上取得的效果十分惊人。


▲图2. 特斯拉的ExaPOD效果图
Dojo超级计算机系统的未来路线图如下:

▲图3. Dojo的整体Roadmap

Part 1
电源和带宽设计
1)电源供给
在技术部分,好的计算模块需要非常特制的电源设计,在这里电压调节模块可以传输1000A电流,具有超高密度,利用多层垂直电源管理材料过渡。这个设计具有高性能、高密度(0.86A/mm²)、复杂集成性,未来的目标是减少54%的CTE,提升3倍性能。在这里提高功率密度是提升系统性能的核心和基石,有趣的是特斯拉在24个月内设计更新了14个版本。
在这个电源设计中,充分考虑了电容、时钟和振动特性。
● 下一步优化开关频率


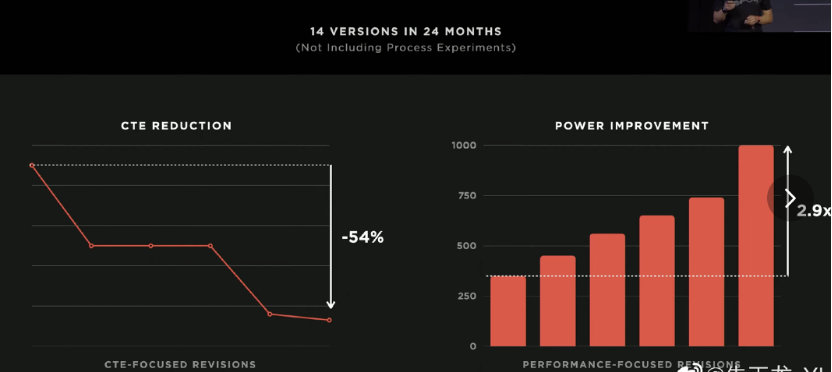
▲图4. 配套的电源模块

▲图5. Training Tile的结构
2)可扩展的系统
系统集合,包含了功率、结构和散热三部分,这个最小单元System Tray参数:75mm高度、54 PFLOPS(BF16/CFP8)、13.4 TB/S(对分带宽)、100+ KW Power
Standard Interface Processor参数:32GB(高带宽动态随机存取存储器)、900 TB/S(TTP带宽)、50 GB/S(以太网带宽)、32GB/S(第四代PCI带宽)
High Interface Processor参数:640GB(高带宽动态随机存取存储器)、1TB/S(以太网带宽)、18 TB/S(Aggregate Bandwidth To Tiles)

▲图6. System Tray

▲图7. Dojo Host 接口
对应32GB高传输频宽存储、每秒900TB资料传输量,以及每秒可对应50GB资料传输量的网路传输频宽的Dojo接口处理器

▲图8. Dojo的接口处理器
下图是Dojo的时间进度表。
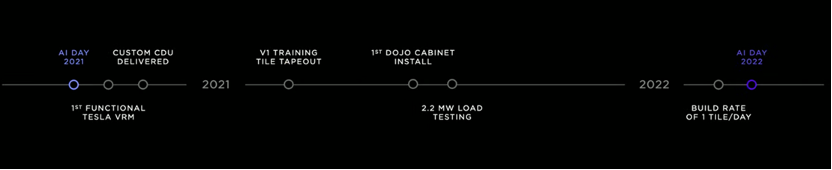

▲图9. Dojo 的时间进度

Part 2
Dojo的软件系统
Dojo系统建立目标:解决很难形成规模的约束模型。
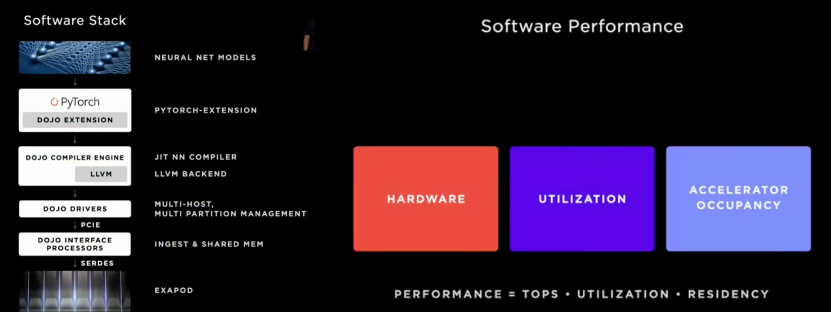
▲图10. 软件的优化目标
单一的加速器到前向和后向通道、优化器、多个加速器上运行多个副本的流程。更大激活度的模型想运行前向通道时会遇到适合单个加速器的批量大小往往小于批量规范面的问题;多个加速器上设置同步批量规范模式。
高密度集成是为了加速模型的计算约束和延迟约束部分;Dojo网格的一个片断可以被分割出来运行模型(只要分片足够大);统一的低延迟中的细粒度同步原语加速跨集成边界的并行性;Tensors是以RAM的形式存储Chardon,并在各层执行时及时复制;张量复制的另一个数据传输与计算重叠,编译器也可重新计算层。
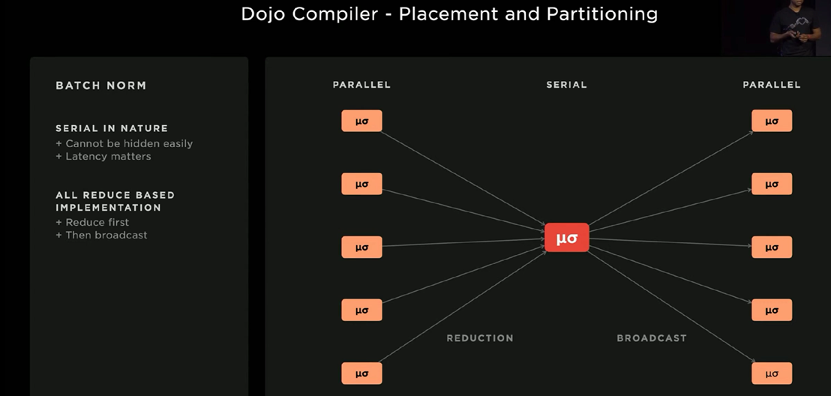
▲图11. 网络模型
编译器以模型并行的方式映射,通信阶段从节点计算本地平均值和标准偏差开始;协调后继续并行。从编译器中提取通信树;真实硬件的时间节点,中间辐射减少的值由硬件加速;这个操作在25个Dojo编译器上只需要5微秒,同样的操作在24个GPU上需要150微秒。这是对GPU的一个数量级的改进。
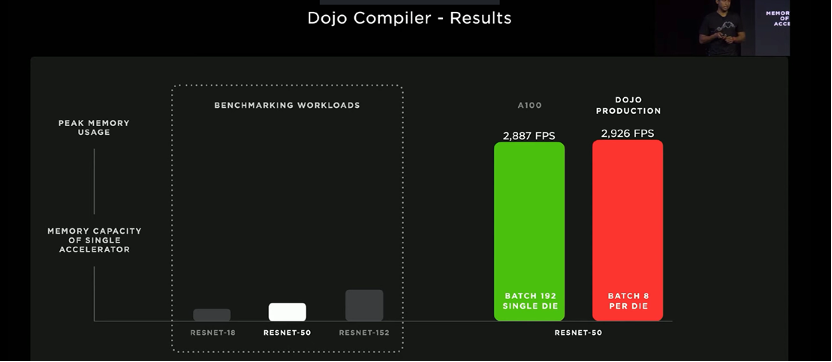
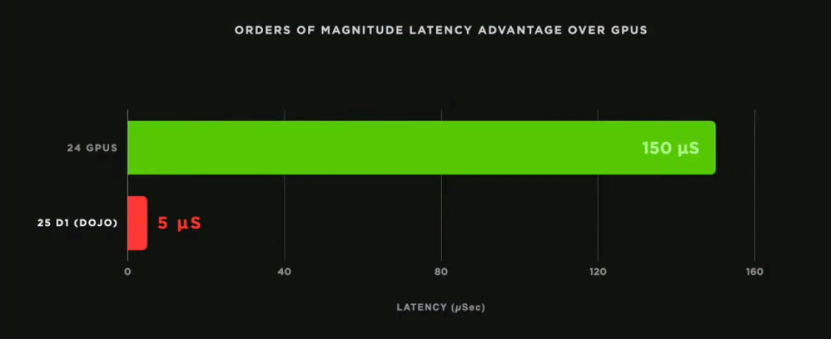
▲图12. 对比的结果
Dojo是为解决更大的复杂模型而建立的,当前两个GPU集群的使用模式,
● 占有率网络(高算术强度的大型模型)
测试结果:多模系统上对GPU和Dojo进行的测量显示已经可以超越任何100个使用当前硬件运行的老一代PRMS的性能;A100的吞吐量翻了一番;关键的编译器优化达到M100的3倍以上的性能。
目前来看,一个Dojo可以取代6个GPU盒子上的ML计算机,而成本比一个GPU盒子还低,目前一个多月时间来训练的网络现在只需要不到一个星期
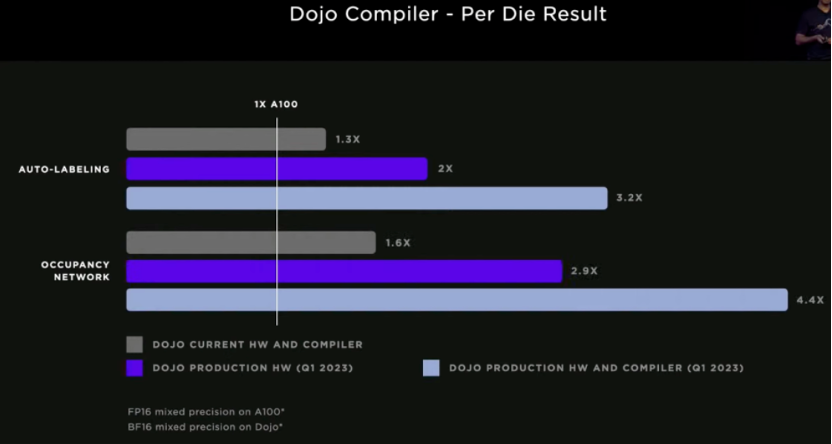
▲图13. Dojo的特性对比
小结:这些信息感觉都是为了给全球的工程师的,也是给出了很多的技术发展的方向,有些像之前开放专利的模式,为了进一步招纳年轻的工程师准备的。
 最前沿的电子设计资讯
最前沿的电子设计资讯

