

作者|PerceptionX
来源 |计算机视觉life(直接);知乎@PerceptionX
原文 |https://zhuanlan.zhihu.com/p/466426243
Tesla对自动标注的技术和要求:
● 首先是在Vector Space上的标注, 需要对数据做出分析处理,数据标注工具的搭建;
● 一个离线大模型对数据进行标注,车载模型相当于对大模型进行蒸馏;并且拥有强大的数据采集能力;
● 核心技术方面:三维重建与视觉SLAM等算法。
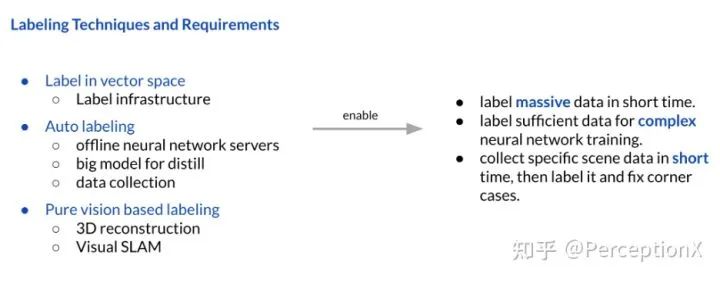
下面我们就来为这三点慢慢展开。

特斯拉高级主管提供的信息
首先我们recall一下特斯拉高级主管Andrej Karpathy在2021 CVPR上对特斯拉自动驾驶现状讲解时提供的信息。

● 要想成功训练出一个网络,对数据的需求特征:
1. 你需要有大量的数据,这里可以指成千上万个视频片段;
2. 需要有Sanity Check, 需要干净的数据,数据的标注需要涵盖深度、速度、加速度信息;
3. 需要多种多类的数据,即使在同一个简单场景跑一万年,实际上的作用也不大,更重要的是需要大量的corner cases。
● 整体的数据闭环体系:
数据采集 → 搭建数据集 → 自动+人工标注 →送入模型训练 → 量化部署到车端上。
● 重视Data labelling:
在整个特斯拉自动驾驶里面,Data labelling可能比网络部分还要重要,因为数据这一块容易用一些技巧去提升效果。

特斯拉数据标注策略的演变
一开始tesla选择和第三方公司合作,但很快就发现标注效率很低,并且沟通的成本很高,后来他们选择自己建立标注团队,也实现了比较好的产出。
我们可以从图片的下方看到数据标注量在后面时间段产出都比较稳定。
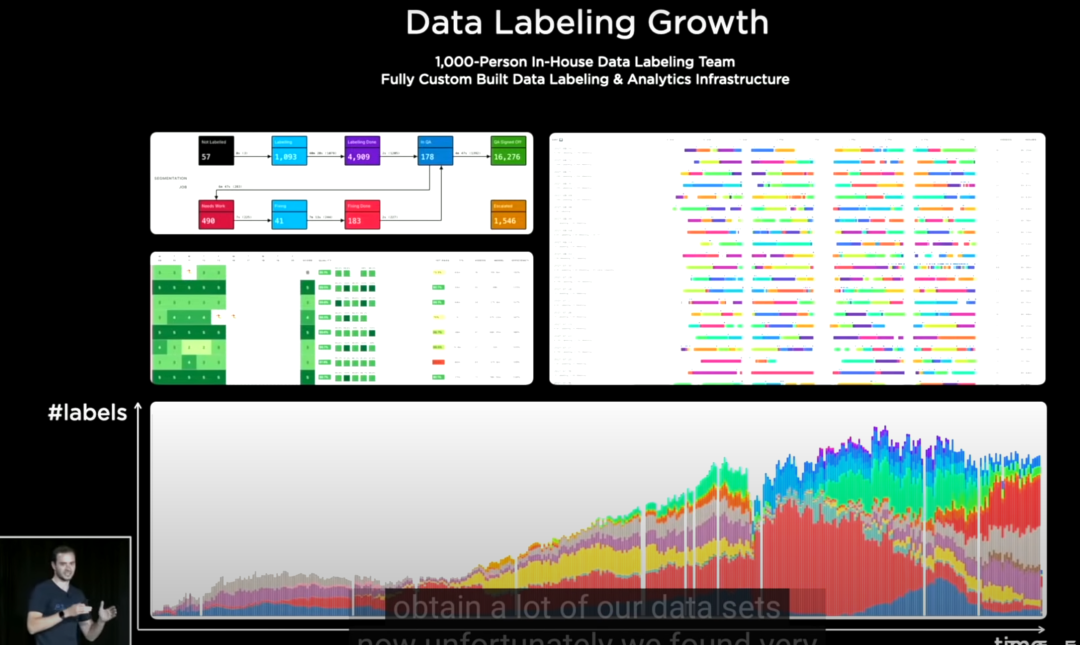
我们猜测其中有两点起到了作用:
1. Tesla自主开发了一个数据标注平台,包括数据标注工具与数据分析工具; 2. 公司自己组建了一个千人标注团队,(不确定是否都是全职)专门负责数据的标注。
NO.1
早期的2D平面标注
回到最初,Tesla是在2D的平面上对数进行精细的标注, 例如上图,不仅对车道线+朝向,红绿灯,行人做标注,连对锥形雪糕筒,左边路面的拖拉机,大卡车也会去做标注(估计归类为construction)。
但是对于这种方法, Tesla就发现这么一张一张去标注不太work, 并且一直这么标也不知道什么时到终点。

2D 标注demo
NO.2
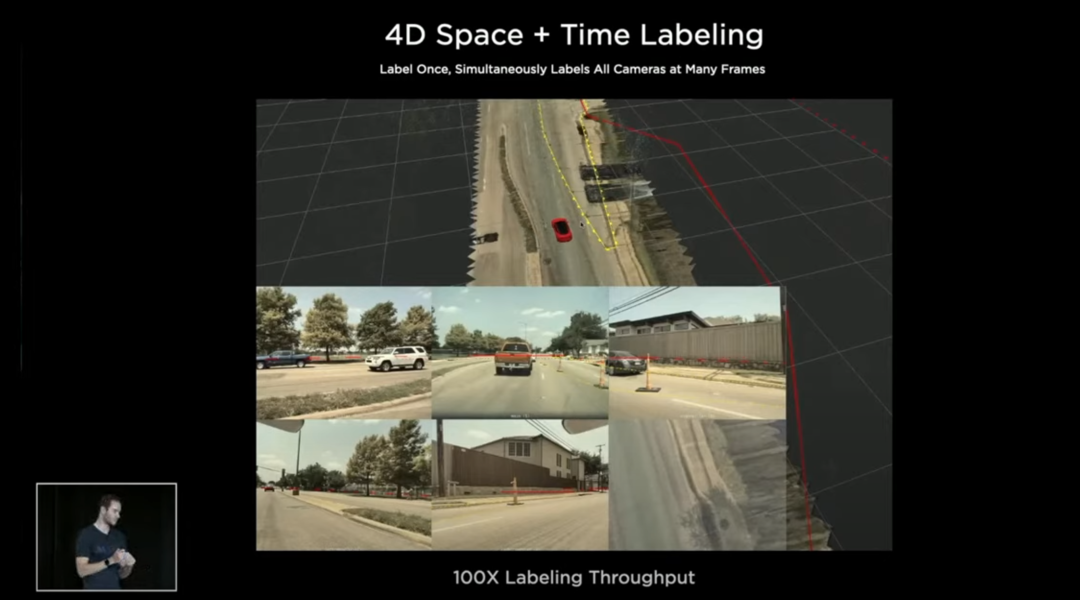
4D Space + TimeLabelling
接下来Tesla马上转变到一个4D Space + Time Labelling 的标注模式,在我们看来其实像一个vector space 下 3D 标注 + 时间序列,加入时间序列主要作用是知道前面发生了什么,把前面的东西保留,可以将信息投到后面,例如3D版的CVAT。
整个思想是,在3D空间下标注,然后再投到8个摄像机里面,简单来说,可以理解为 amount of the labels in 3D space (vector space) = ⅛ amount of labels in 8 camera views (image space)。这里可能会涉及到2D标注与3D标注之前的成本问题,很明显我们都知道标注一张2D的图像会比标注一张3D的图像成本低,但如果是 8张2D的图像对比1张3D的图像,从Tesla 的做法来看,是标注1张3D图像的成本效果要比较好。
但其实即使你标注获得了8倍的数据,对自动驾驶而言也还是不够用的。我们在之前的图片也看到,在CVPR2021 WAD的时候, Tesla 有60亿个标注,和1.5 Pentabytes (PB) 的数据,如果单单利用人工劳动力去标注,是不大可能做到如此庞大的数据量的。
 最前沿的电子设计资讯
最前沿的电子设计资讯

