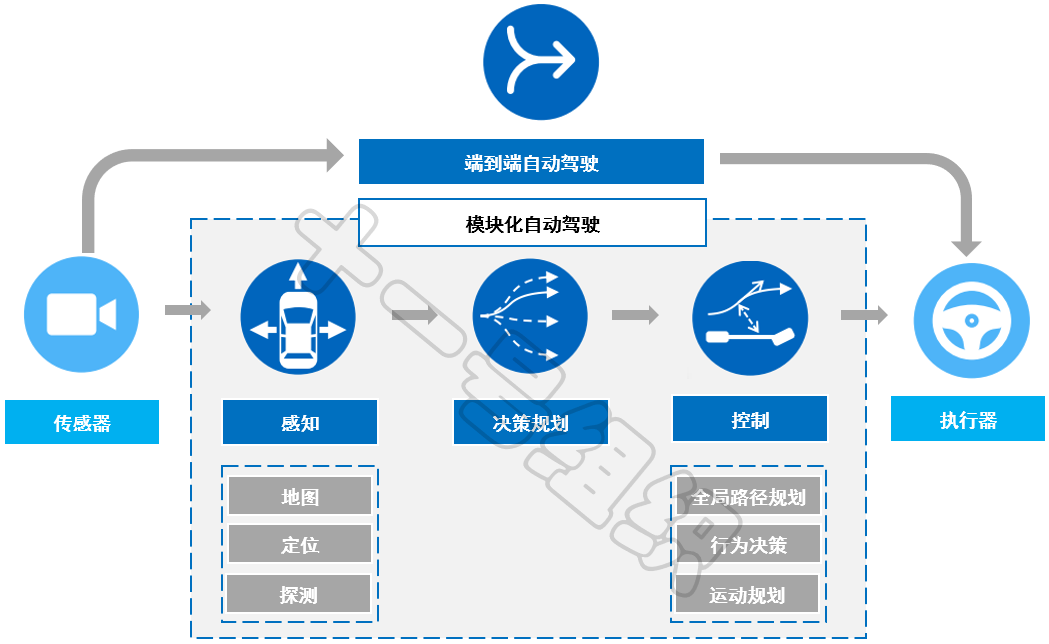
正菜之前,我们先来了解一下图(包括有向图和无向图)的概念。图是图论中的基本概念,用于表示物体与物体之间存在某种关系的结构。在图中,物体被称为节点或顶点,并用一组点或小圆圈表示。节点间的关系称作边,可以用直线或曲线来表示节点间的边。
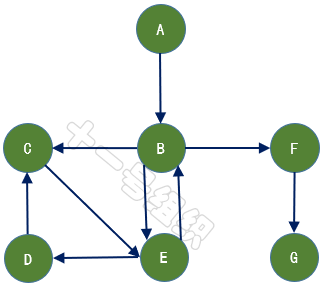
如果给图的每条边规定一个方向,那么得到的图称为有向图,其边也称为有向边,如图9所示。在有向图中,与一个节点相关联的边有出边和入边之分,而与一个有向边关联的两个点也有始点和终点之分。相反,边没有方向的图称为无向图。
 8JTednc
8JTednc
数学上,常用二元组G =(V,E)来表示其数据结构,其中集合V称为点集,E称为边集。对于图6所示的有向图,V可以表示为{A,B,C,D,E,F,G},E可以表示为{,,,,,,}。表示从顶点A发向顶点B的边,A为始点,B为终点。8JTednc
在图的边中给出相关的数,称为权。权可以代表一个顶点到另一个顶点的距离、耗费等,带权图一般称为网。8JTednc
在全局路径规划时,通常将图10所示道路和道路之间的连接情况,通行规则,道路的路宽等各种信息处理成有向图,其中每一个有向边都是带权重的,也被称为路网(Route Network Graph)。8JTednc
那么,全局路径的规划问题就变成了在路网中,搜索到一条最优的路径,以便可以尽快见到那个心心念念的她,这也是全局路径规划算法最朴素的愿望。而为了实现这个愿望,诞生了Dijkstra和A*两种最为广泛使用的全局路径搜索算法。8JTednc
2.1 Dijkstra算法8JTednc
戴克斯特拉算法(Dijkstra’s algorithm)是由荷兰计算机科学家Edsger W. Dijkstra在1956年提出,解决的是有向图中起点到其他顶点的最短路径问题。8JTednc
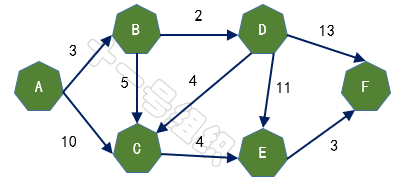
假设有A、B、C、D、E、F五个城市,用有向图表示如图11,边上的权重代表两座城市之间的距离,现在我们要做的就是求出起点A城市到其它城市的最短距离。8JTednc
用Dijkstra算法求解步骤如下:8JTednc
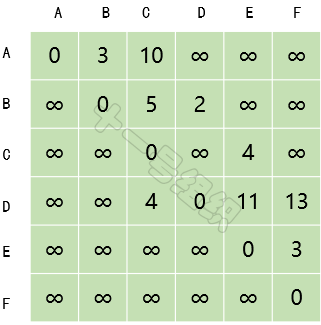
(1)创建一个二维数组E来描述顶点之间的距离关系,如图12所示。E[B][C]表示顶点B到顶点C的距离。自身之间的距离设为0,无法到达的顶点之间设为无穷大。8JTednc
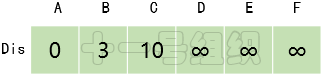
(2)创建一个一维数组Dis来存储起点A到其余顶点的最短距离。一开始我们并不知道起点A到其它顶点的最短距离,一维数组Dis中所有值均赋值为无穷大。接着我们遍历起点A的相邻顶点,并将与相邻顶点B和C的距离3(E[A][B])和10(E[A][C])更新到Dis[B]和Dis[C]中,如图13所示。这样我们就可以得出起点A到其余顶点最短距离的一个估计值。8JTednc
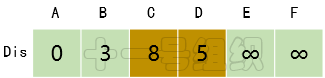
(3)接着我们寻找一个离起点A距离最短的顶点,由数组Dis可知为顶点B。顶点B有两条出边,分别连接顶点C和D。因起点A经过顶点B到达顶点C的距离8(E[A][B] + E[B][C] = 3 + 5)小于起点A直接到达顶点C的距离10,因此Dis[C]的值由10更新为8。同理起点A经过B到达D的距离5(E[A][B] + E[B][D] = 3 + 2)小于初始值无穷大,因此Dis[D]更新为5,如图14所示。8JTednc
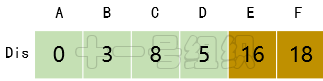
(4)接着在剩下的顶点C、D、E、F中,选出里面离起点A最近的顶点D,继续按照上面的方式对顶点D的所有出边进行计算,得到Dis[E]和Dis[F]的更新值,如图15所示。8JTednc
(5)继续在剩下的顶点C、E、F中,选出里面离起点A最近的顶点C,继续按照上面的方式对顶点C的所有出边进行计算,得到Dis[E]的更新值,如图16所示。8JTednc
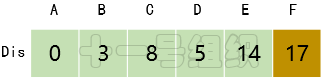
(6)继续在剩下的顶点E、F中,选出里面离起点A最近的顶点E,继续按照上面的方式对顶点E的所有出边进行计算,得到Dis[F]的更新值,如图17所示。8JTednc
(7)最后对顶点F所有点出边进行计算,此例中顶点F没有出边,因此不用处理。至此,数组Dis中距离起点A的值都已经从“估计值”变为了“确定值”。8JTednc
基于上述形象的过程,Dijkstra算法实现过程可以归纳为如下步骤:8JTednc
(1)将有向图中所有的顶点分成两个集合P和Q,P用来存放已知距离起点最短距离的顶点,Q用来存放剩余未知顶点。可以想象,一开始,P中只有起点A。同时我们创建一个数组Flag[N]来记录顶点是在P中还是Q中。对于某个顶点N,如果Flag[N]为1则表示这个顶点在集合P中,为1则表示在集合Q中。8JTednc
(2)起点A到自己的最短距离设置为0,起点能直接到达的顶点N,Dis[N]设为E[A][N],起点不能直接到达的顶点的最短路径为设为∞。8JTednc
(3)在集合Q中选择一个离起点最近的顶点U(即Dis[U]最小)加入到集合P。并计算所有以顶点U为起点的边,到其它顶点的距离。例如存在一条从顶点U到顶点V的边,那么可以通过将边U->V添加到尾部来拓展一条从A到V的路径,这条路径的长度是Dis[U]+e[U][V]。如果这个值比目前已知的Dis[V]的值要小,我们可以用新值来替代当前Dis[V]中的值。8JTednc
(4)重复第三步,如果最终集合Q结束,算法结束。最终Dis数组中的值就是起点到所有顶点的最短路径。8JTednc
2.2 A*算法8JTednc
1968年,斯坦福国际研究院的Peter E. Hart, Nils Nilsson以及Bertram Raphael共同发明了A*算法。A*算法通过借助一个启发函数来引导搜索的过程,可以明显地提高路径搜索效率。8JTednc
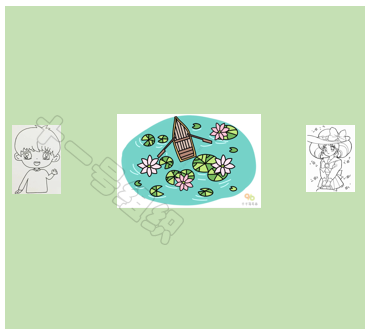
下文仍以一个实例来简单介绍A*算法的实现过程。如图18所示,假设小马要从A点前往B点大榕树底下去约会,但是A点和B点之间隔着一个池塘。为了能尽快提到达约会地点,给姑娘留下了一个守时踏实的好印象,我们需要给小马搜索出一条时间最短的可行路径。8JTednc
A*算法的第一步就是简化搜索区域,将搜索区域划分为若干栅格。并有选择地标识出障碍物不可通行与空白可通行区域。一般地,栅格划分越细密,搜索点数越多,搜索过程越慢,计算量也越大;栅格划分越稀疏,搜索点数越少,相应的搜索精确性就越低。8JTednc
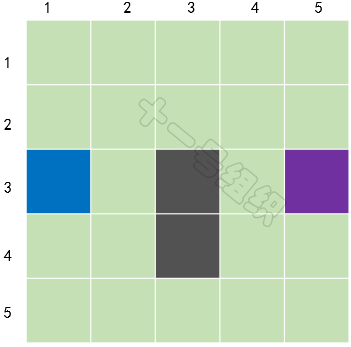
如图19所示,我们在这里将要搜索的区域划分成了正方形(当然也可以划分为矩形、六边形等)的格子,图中蓝色格子代表A点(小马当前的位置),紫色格子代表B点(大榕树的位置),灰色格子代表池塘。同时我们可以用一个二维数组S来表示搜素区域,数组中的每一项代表一个格子,状态代表可通行和不可通行。8JTednc
接着我们引入两个集合OpenList和CloseList,以及一个估价函数F = G + H。OpenList用来存储可到达的格子,CloseList用来存储已到达的格子。G代表从起点到当前格子的距离,H表示在不考虑障碍物的情况下,从当前格子到目标格子的距离。F是起点经由当前格子到达目标格子的总代价,值越小,综合优先级越高。8JTednc
G和H也是A*算法的精髓所在,通过考虑当前格子与起始点的距离,以及当前格子与目标格子的距离来实现启发式搜索。对于H的计算,又有两种方式,一种是欧式距离,一种是曼哈顿距离。8JTednc
欧式距离用公式表示如下,物理上表示从当前格子出发,支持以8个方向向四周格子移动(横纵向移动+对角移动)。8JTednc
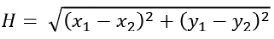 8JTednc
8JTednc
曼哈顿距离用公式表示如下,物理上表示从当前格子出发,支持以4个方向向四周格子移动(横纵向移动)。这是A*算法最常用的计算H值方法,本文H值的计算也采用这种方法。8JTednc
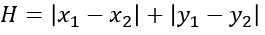 8JTednc
8JTednc
现在我们开始搜索,查找最短路径。首先将起点A放入到OpenList中,并计算出此时OpenList中F值最小的格子作为当前方格移入到CloseList中。由于当前OpenList中只有起点A这个格子,所以将起点A移入CloseList,代表这个格子已经检查过了。8JTednc
接着我们找出当前格子A上下左右所有可通行的格子,看它们是否在OpenList当中。如果不在,加入到OpenList中计算出相应的G、H、F值,并把当前格子A作为它们的父节点。本例子,我们假设横纵向移动代价为10,对角线移动代价为14。8JTednc
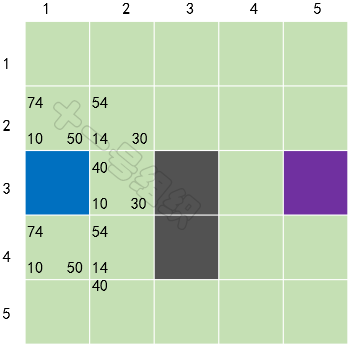
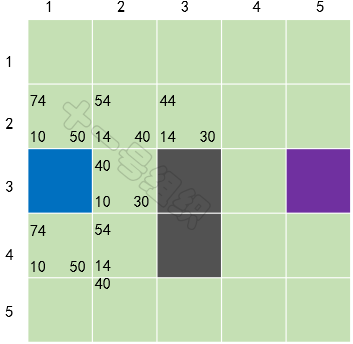
我们在每个格子上标出计算出来的F、G、H值,如图20所示,左上角是F,左下角是G,右下角是H。通过计算可知S[3][2]格子的F值最小,我们把它从OpenList中取出,放到CloseList中。8JTednc
接着将S[3][2]作为当前格子,检查所有与它相邻的格子,忽略已经在CloseList或是不可通行的格子。如果相邻的格子不在OpenList中,则加入到OpenList,并将当前方格子S[3][2]作为父节点。8JTednc
已经在OpenList中的格子,则检查这条路径是否最优,如果非最优,不做任何操作。如果G值更小,则意味着经由当前格子到达OpenList中这个格子距离更短,此时我们将OpenList中这个格子的父节点更新为当前节点。8JTednc
对于当前格子S[3][2]来说,它的相邻5个格子中有4个已经在OpenList,一个未在。对于已经在OpenList中的4个格子,我们以它上面的格子S[2][2]举例,从起点A经由格子S[3][2]到达格子S[2][2]的G值为20(10+10)大于从起点A直接沿对角线到达格子S[2][2]的G值14。显然A经由格子S[3][2]到达格子S[2][2]不是最优的路径。当把4个已经在OpenList 中的相邻格子都检查后,没有发现经由当前方格的更好路径,因此我们不做任何改变。8JTednc
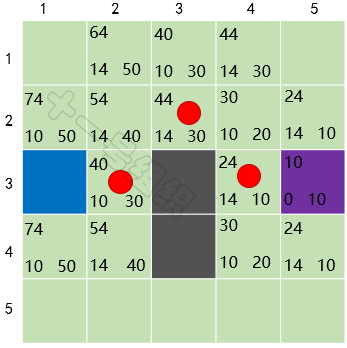
对于未在OpenList的格子S[2][3](假设小马可以斜穿墙脚),加入OpenList中,并计算它的F、G、H值,并将当前格子S[3][2]设置为其父节点。经历这一波骚操作后,OpenList中有5个格子,我们需要从中选择F值最小的那个格子S[2][3],放入CloseList中,并设置为当前格子,如图21所示。8JTednc
重复上面的故事,直到终点也加入到OpenList中。此时我们以当前格子倒推,找到其父节点,父节点的父节点……,如此便可搜索出一条最优的路径,如图22中红色圆圈标识。8JTednc
基于上述形象的过程,A*算法实现过程可以归纳为如下步骤:8JTednc
(1)将搜索区域按一定规则划分,把起点加入OpenList。8JTednc
(2)在OpenList中查找F值最小的格子,将其移入CloseList,并设置为当前格子。8JTednc
(3)查找当前格子相邻的可通行的格子,如果它已经在OpenList中,用G值衡量这条路径是否更好。如果更好,将该格子的父节点设置为当前格子,重新计算F、G值,如果非更好,不做任何处理;如果不在OpenList中,将它加入OpenList中,并以当前格子为父节点计算F、G、H值。8JTednc
(4)重复步骤(2)和步骤(3),直到终点加入到OpenList中。8JTednc
2.3 两种算法比较8JTednc
Dijkstra算法的基本思想是“贪心”,主要特点是以起点为中心向周围层层扩展,直至扩展到终点为止。通过Dijkstra算法得出的最短路径是最优的,但是由于遍历没有明确的方向,计算的复杂度比较高,路径搜索的效率比较低。且无法处理有向图中权值为负的路径最优问题。8JTednc
A*算法将Dijkstra算法与广度优先搜索(Breadth-First-Search,BFS)算法相结合,并引入启发函数(估价函数),大大减少了搜索节点的数量,提高了搜索效率。但是A*先入为主的将最早遍历路径当成最短路径,不适用于动态环境且不太适合高维空间,且在终点不可达时会造成大量性能消耗。8JTednc
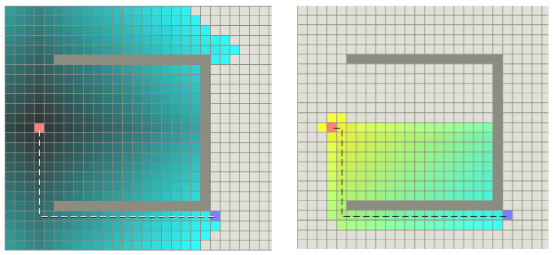
图24是两种算法路径搜索效率示意图,左图为Dijkstra算法示意图,右图为A*算法示意图,带颜色的格子表示算法搜索过的格子。由图23可以看出,A*算法更有效率,手术的格子更少。8JTednc
 8JTednc
8JTednc
图23 Dijkstra算法和A*算法搜索效率对比图(图片来源:https://mp.weixin.qq.com/s/myU204Uq3tfuIKHGD3oEfw)
作为L4级自动驾驶的优秀代表Robotaxi,部分人可能已经在自己的城市欣赏过他们不羁的造型,好奇心强烈的可能都已经体验过他们的无人“推背”服务。作为一个占有天时地利优势的从业人员,我时常在周末选一个人和的时间,叫个免费Robotaxi去超市买个菜。8JTednc
刚开始几次乘坐,我的注意力全都放在安全员的双手,观察其是否在接管;过了一段时间,我的注意力转移到中控大屏,观察其梦幻般的交互方式;而现在,我的注意力转移到了智能上,观察其在道路上的行为决策是否足够聪明。
而这一观察,竟真总结出不少共性问题。比如十字路口左转,各家Robotaxi总是表现的十分小心谨慎,人类司机一脚油门过去的场景,Robotaxi总是再等等、再看看。且不同十字路口同一厂家的Robotaxi左转的策略基本一致,完全没有人类司机面对不同十字路口、不同交通流、不同天气环境时的“随机应变”。
面对复杂多变场景时自动驾驶行为决策表现出来的小心谨慎,像极了人类进入一个新环境时采取的猥琐发育策略。但在自动驾驶终局到来的那天,自动驾驶的决策规划能否像人类一样,在洞悉了人情社会的生活法则之后,做到“见人说人话”、“见人下饭”呢?
在让自动驾驶车辆的行为决策变得越来越像老司机的努力过程中,主要诞生了基于规则和基于学习的两大类行为决策方法。
3.1 基于规则的方法
在基于规则的方法中,通过对自动驾驶车辆的驾驶行为进行划分,并基于感知环境、交通规则等信息建立驾驶行为规则库。自动驾驶车辆在行驶过程中,实时获取交通环境、交通规则等信息,并与驾驶行为规则库中的经验知识进行匹配,进而推理决策出下一时刻的合理自动驾驶行为。
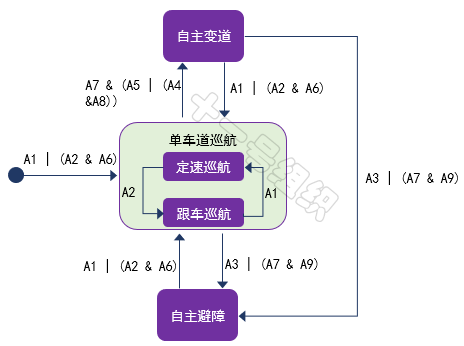
正如全局路径规划的前提是地图一样,自动驾驶行为分析也成为基于规则的行为决策的前提。不同应用场景下的自动驾驶行为不完全相同,以高速主干路上的L4自动驾驶卡车为例,其自动驾驶行为可简单分解为单车道巡航、自主变道、自主避障三个典型行为。
单车道巡航是卡车L4自动驾驶系统激活后的默认状态,车道保持的同时进行自适应巡航。此驾驶行为还可以细分定速巡航、跟车巡航等子行为,而跟车巡航子行为还可以细分为加速、加速等子子行为,真是子子孙孙无穷尽也。
自主变道是在变道场景(避障变道场景、主干路变窄变道场景等)发生及变道空间(与前车和后车的距离、时间)满足后进行左/右变道。自主避障是在前方出现紧急危险情况且不具备自主变道条件时,采取的紧急制动行为,避免与前方障碍物或车辆发生碰撞。其均可以继续细分,此处不再展开。
上面列举的驾驶行为之间不是独立的,而是相互关联的,在一定条件满足后可以进行实时切换,从而支撑起L4自动驾驶卡车在高速主干路上的自由自在。现将例子中的三种驾驶行为之间的切换条件简单汇总如表2,真实情况比这严谨、复杂的多,此处仅为后文解释基于规则的算法所用。
表2 状态间的跳转事件8JTednc
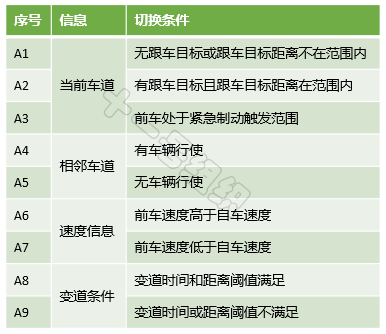 8JTednc
8JTednc
在基于规则的方法中,有限状态机(FiniteStateMaechine,FSM)成为最具有代表性的方法。2007年斯坦福大学参加DARPA城市挑战赛时的无人车“Junior”,其行为决策采用的就是有限状态机方法。
有限状态机是一种离散的数学模型,也正好符合自动驾驶行为决策的非连续特点,主要用来描述对象生命周期内的各种状态以及如何响应来自外界的各种事件。有限状态机包含四大要素:状态、事件、动作和转移。事件发生后,对象产生相应的动作,从而引起状态的转移,转移到新状态或维持当前状态。
我们将上述驾驶行为定义为有限状态机的状态,每个状态之间在满足一定的事件(或条件)后,自动驾驶车辆执行一定的动作后,就可以转移到新的状态。比如单车道巡航状态下,前方车辆低速行驶,自车在判断旁边车道满足变道条件要求后,切换到自主变道状态。自主变道完成后,系统再次回到单车道巡航状态。
结合表2中的切换条件,各个状态在满足一定事件(或条件)后的状态跳转示意图如图24所示。
基于有限状态机理论构建的智能车辆自动驾驶行为决策系统,可将复杂的自动驾驶过程分解为有限个自动驾驶驾驶行为,逻辑推理清晰、应用简单、实用性好等特点,使其成为当前自动驾驶领域目前最广泛使用的行为决策方法。
但该方法没有考虑环境的动态性、不确定性以及车辆运动学以及动力学特性对驾驶行为决策的影响,因此多适用于简单场景下,很难胜任具有丰富结构化特征的城区道路环境下的行为决策任务。
上文介绍的基于规则的行为决策方法依靠专家经验搭建的驾驶行为规则库,但是由于人类经验的有限性,智能性不足成为基于规则的行为决策方法的最大制约,复杂交通工况的事故率约为人类驾驶员的百倍以上。鉴于此,科研工作者开始探索基于学习的方法,并在此基础上了诞生了数据驱动型学习方法和强化学习方法。
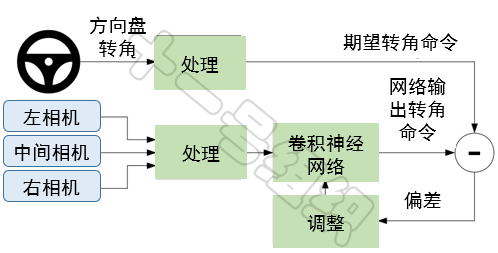
数据驱动型学习是一种依靠自然驾驶数据直接拟合神经网络模型的方法,首先用提前采集到的老司机开车时的自然驾驶数据训练神经网络模型,训练的目标是让自动驾驶行为决策水平接近老司机。而后将训练好的算法模型部署到车上,此时车辆的行为决策就像老司机一样,穿行在大街小巷。读者可参见端到端自动驾驶章节中介绍的NVIDIA demo案例。
强化学习方法通过让智能体(行为决策主体)在交互环境中以试错方式运行,并基于每一步行动后环境给予的反馈(奖励或惩罚),来不断调整智能体行为,从而实现特定目的或使得整体行动收益最大。通过这种试错式学习,智能体能够在动态环境中自己作出一系列行为决策,既不需要人为干预,也不需要借助显式编程来执行任务。
强化学习可能不是每个人都听过,但DeepMind开发的围棋智能AlphaGo(阿尔法狗),2016年3月战胜世界围棋冠军李世石,2017年5月后又战胜围棋世界排名第一柯洁的事,大家应该都有所耳闻。更过分的是,半年后DeepMind在发布的新一代围棋智能AlphaZero(阿尔法狗蛋),通过21天的闭关修炼,就战胜了家族出现的各种狗子们,成功当选狗蛋之王。
而赋予AlphaGo及AlphaZero战胜人类棋手的魔法正是强化学习,机器学习的一种。机器学习目前有三大派别:监督学习、无监督学习和强化学习。监督学习算法基于归纳推理,通过使用有标记的数据进行训练,以执行分类或回归;无监督学习一般应用于未标记数据的密度估计或聚类;
强化学习自成一派,通过让智能体在交互环境中以试错方式运行,并基于每一步行动后环境给予的反馈(奖励或惩罚),来不断调整智能体行为,从而实现特定目的或使得整体行动收益最大。通过这种试错式学习,智能体能够在动态环境中自己作出一系列决策,既不需要人为干预,也不需要借助显式编程来执行任务。
这像极了马戏团训练各种动物的过程,驯兽师一个抬手动作(环境),动物(智能体)若完成相应动作,则会获得美味的食物(正反馈),若没有完成相应动作,食物可能换成了皮鞭(负反馈)。时间一久,动物就学会基于驯兽师不同的手势完成不同动作,来使自己获得最多数量的美食。
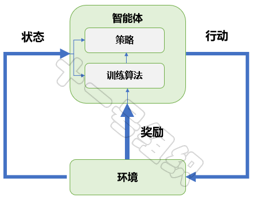
大道至简,强化学习亦如此。一个战胜人类围棋冠军的“智能”也仅由五部分组成:智能体(Agent)、环境(Environment)、状态(State)、行动(Action)和奖励(Reward)。强化学习系统架构如图25所示,结合自动驾驶代客泊车中的泊入功能,我们介绍一下各组成的定义及作用。
代客泊车泊入功能的追求非常清晰,就是在不发生碰撞的前提下,实现空闲停车位的快速泊入功能。这个过程中,承载强化学习算法的控制器(域控制器/中央计算单元)就是智能体,也是强化学习训练的主体。智能体之外的整个泊车场景都是环境,包括停车场中的立柱、车辆、行人、光照等。
训练开始后,智能体实时从车载传感器(激光雷达、相机、IMU、超声波雷达等)读取环境状态,并基于当前的环境状态,采取相应的转向、制动和加速行动。如果基于当前环境状态采用的行动,是有利于车辆快速泊入,则智能体会得到一个奖励,反之则会得到一个惩罚。
在奖励和惩罚的不断刺激下,智能体学会了适应环境,学会了下次看到空闲车位时可以一把倒入,学会了面对不同车位类型时采取不同的风骚走位。
从上述例子,我们也可以总结出训练出一个优秀的“智能”,大概有如下几个步骤:
(1)创建环境。定义智能体可以学习的环境,包括智能体和环境之间的接口。环境可以是仿真模型,也可以是真实的物理系统。仿真环境通常是不错的起点,一是安全,二是可以试验。
(2)定义奖励。指定智能体用于根据任务目标衡量其性能的奖励信号,以及如何根据环境计算该信号。可能需要经过数次迭代才能实现正确的奖励塑造。
(3)创建智能体。智能体由策略和训练算法组成,因此您需要:
(a)选择一种表示策略的方式(例如,使用神经网络或查找表)。思考如何构造参数和逻辑,由此构成智能体的决策部分。8JTednc
(b)选择合适的训练算法。大多数现代强化学习算法依赖于神经网络,因为后者非常适合处理大型状态/动作空间和复杂问题。8JTednc
(4)训练和验证智能体。设置训练选项(如停止条件)并训练智能体以调整策略。要验证经过训练的策略,最简单的方法是仿真。
(5)部署策略。使用生成的 C/C++ 或 CUDA 代码等部署经过训练的策略表示。此时无需担心智能体和训练算法;策略是独立的决策系统。
强化学习方法除了具有提高行为决策智能水平的能力,还具备合并决策和控制两个任务到一个整体、进行统一求解的能力。将决策与控制进行合并,这样既发挥了强化学习的求解优势,又能进一步提高自动驾驶系统的智能性。实际上,人类驾驶员也是具有很强的整体性的,我们很难区分人类的行为中哪一部分是自主决策,哪一部分是运动控制。
现阶段强化学习方法的应用还处在摸索阶段,应用在自动驾驶的潜力还没有被完全发掘出来,这让我想起了母校的一句校歌:“能不奋勉乎吾曹?”
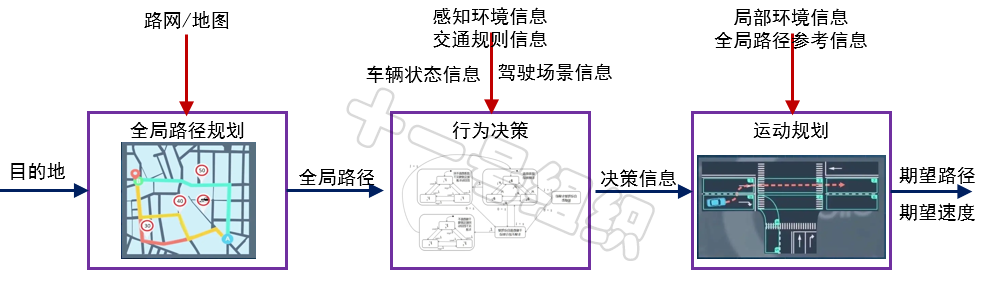
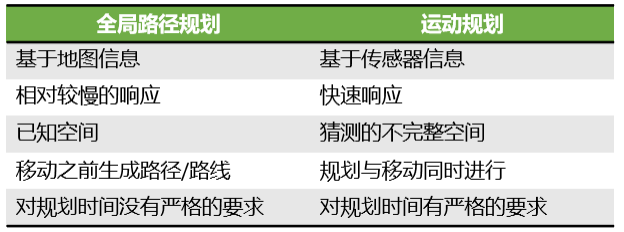
有了全局路径参考信息,有了局部环境信息了,有了行为决策模块输入的决策信息,下一步自然而然的就要进行运动规划,从而生成一条局部的更加具体的行驶轨迹,并且这条轨迹要满足安全性和舒适性要求。8JTednc
考虑到车辆是一个具有巨大惯性的铁疙瘩且没有瞬间移动的功能,如果仅考虑瞬时状态的行驶轨迹,不规划出未来一段时间有前瞻性的行驶轨迹,那么很容易造成一段时间后无解。因此,运动规划生成的轨迹是一种由二维空间和一维时间组成的三维空间中的曲线,是一种偏实时的路径规划。
运动规划的第一步往往采用随机采样算法,即走一步看一步,不断更新行驶轨迹。代表算法是基于采样的方法:PRM、RRT、Lattice。这类算法通过随机采样的方式在地图上生成子节点,并与父节点相连,若连线与障碍物无碰撞风险,则扩展该子节点。重复上述步骤,不断扩展样本点,直到生成一条连接起点到终点的路径。
概率路标法 (Probabilistic Road Maps, PRM),是一种经典的采样方法,由Lydia E.等人在1996年提出。PRM主要包含三个阶段,一是采样阶段,二是碰撞检测阶段,三是搜索阶段。
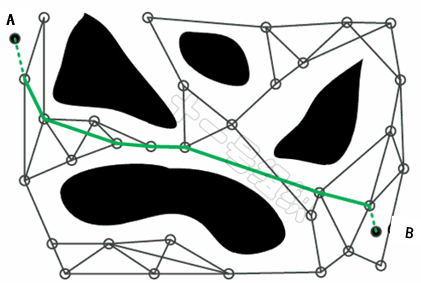
图26为已知起点A和终点B的地图空间,黑色空间代表障碍物,白色空间代表可通行区域。在采样阶段中,PRM首先在地图空间进行均匀的随即采样,也就是对地图进行稀疏采样,目的是将大地图简化为较少的采样点。
图26 PRM工作原理示意图(来源:https://mp.weixin.qq.com/s/WGOUf7g0C4Od4X9rnCfqxA)
在碰撞检测阶段,剔除落在障碍物上的采样点,并将剩下的点与其一定距离范围内的点相连,同时删除穿越障碍物的连线,从而构成一张无向图。
在搜索阶段,利用全局路径规划算法章节介绍的搜索算法(Dijkstra、A*等)在无向图中进行搜索,从而找出一条起点A到终点B之间的可行路径。
(1)构造无向图G =(V,E),其中V代表随机采样的点集,E代表两采样点之间所有可能的无碰撞路径,G初始状态为空。
(2)随机撒点,并选取一个无碰撞的点c(i)加入到V中。
(3)定义距离r,如果c(i)与V中某些点的距离小于r,则将V中这些点定义为c(i)的邻域点。
(4)将c(i)与其邻域点相连,生成连线t,并检测连线t是否与障碍物发生碰撞,如果无碰撞,则将t加入E中。
(5)重复步骤2-4,直到所有采样点(满足采样数量要求)均已完成上述步骤。
(6)采用图搜索算法对无向图G进行搜索,如果能找到起始点A到终点B的路线,说明存在可行的行驶轨迹。
PRM算法相比基于搜索的算法,简化了环境、提高了效率。但是在有狭窄通道场景中,很难采样出可行路径,效率会大幅降低。
快速探索随机树(Rapidly Exploring Random Trees,RRT),是Steven M. LaValle和James J. Kuffner Jr.在1998年提出的一种基于随机生长树思想实现对非凸高维空间快速搜索的算法。与PRM相同的是两者都是基于随机采样的算法,不同的是PRM最终生成的是一个无向图,而RRT生成的是一个随机树。RRT的最显著特征就是具备空间探索的能力,即从一点向外探索拓展的特征。
RRT分单树和双树两种类型,单树RRT将规起点作为随机树的根节点,通过随机采样、碰撞检测的方式为随机树增加叶子节点,最终生成一颗随机树。而双树RRT则拥有两颗随机树,分别以起点和终点为根节点,以同样的方式进行向外的探索,直到两颗随机树相遇,从而达到提高规划效率的目的。
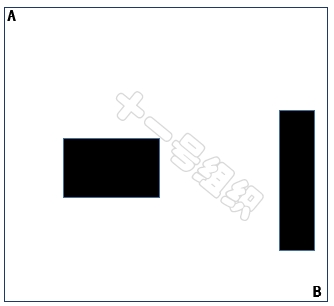
下面以图27所示的地图空间为例介绍单树RRT算法的实现过程。在此地图空间中,我们只知道起点A和终点B以及障碍物的位置(黑色的框)。
图27 RRT算法举例的地图空间8JTednc
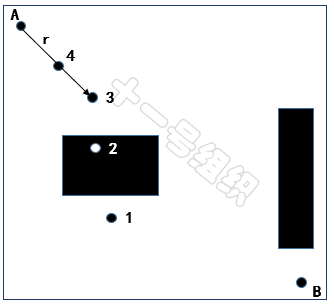
对于单树RRT算法,我们将起点A设置为随机树的根,并生成一个随机采样点,如图27所示,随机采样点有下面这几种情况。
(1)随机采样点1落在自由区域中,但是根节点A和随机采样点1之间的连线存在障碍物,无法通过碰撞检测,采样点1会被舍弃,重新再生成随机采样点。
(2)随机采样点2落在障碍物的位置,采样点2也会被舍弃,重新再生成随机采样点。
(3)随机采样点3落在自由区域,且与根节点A之间的连线不存在障碍物,但是超过根节点的步长限制。但此时这个节点不会被简单的舍弃点,而是会沿着根节点和随机采样点3的连线,找出符合步长限制的中间点,将这个中间点作为新的采样点,也就是图28中的4。
 8JTednc
8JTednc
图28 不同随机采样点举例8JTednc
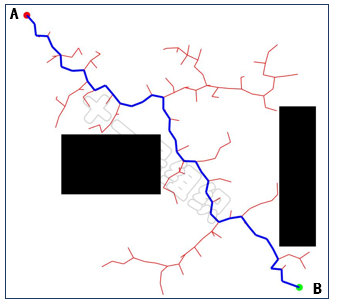
接着我们继续生成新的随机采样点,如果新的随机采样点位于自由区域,那么我们就可以遍历随机树中已有的全部节点,找出距离新的随机采样点最近的节点,同时求出两者之间的距离,如果满足步长限制的话,我们将接着对这两个节点进行碰撞检测,如果不满足步长限制的话,我们需要沿着新的随机采样点和最近的节点的连线方向,找出一个符合步长限制的中间点,用来替代新的随机采样点。最后如果新的随机采样点和最近的节点通过了碰撞检测,就意味着二者之间存在边,我们便可以将新的随机采样点添加进随机树中,并将最近的点设置为新的随机采样点的父节点。
重复上述过程,直到新的随机采样点在终点的步长限制范围内,且满足碰撞检测。则将新的随机采样点设为终点B的父节点,并将终点加入随机树,从而完成迭代,生成如图29所示的完整随机树。
图29 随机树结算结果示例8JTednc
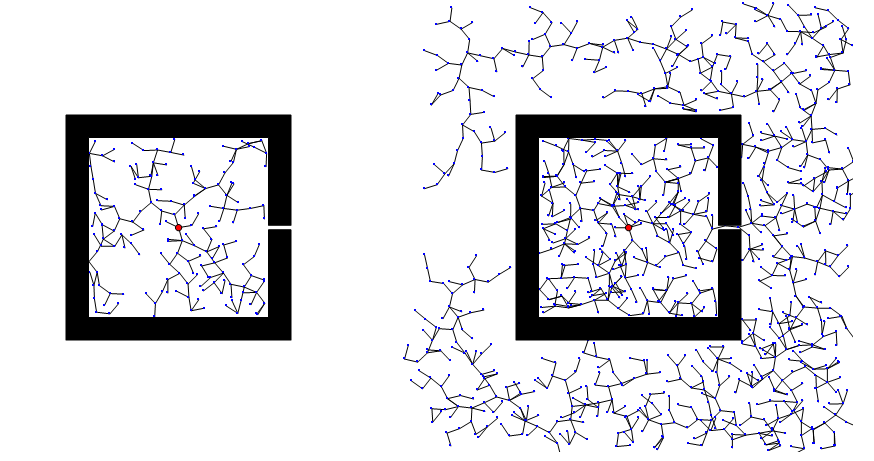
相比PRM,RRT无需搜索步骤、效率更高。通过增量式扩展的方式,找到路径后就立即结束,搜索终点的目的性更强。但是RRT作为一种纯粹的随机搜索算法,对环境类型不敏感,当地图空间中存在狭窄通道时,因被采样的概率低,导致算法的收敛速度慢,效率会大幅下降,有时候甚至难以在有狭窄通道的环境找到路径。
图30展示了 RRT应对存在狭窄通道地图空间时的两种表现,一种是RRT很快就找到了出路,一种是一直被困在障碍物里面。
图30 RRT面对狭窄通道时的表现(来源:https://mp.weixin.qq.com/s/O8aK2RwOUXtcPSKQbDViiQ)
围绕如何更好的“进行随机采样”、“定义最近的点”以及“进行树的扩展”等方面,诞生了多种改进型的算法,包括双树RRT-Connect(双树)、lazy-RRT, RRT-Extend等。
PRM和RRT都是一个概率完备但非最优的路径规划算法,也就是只要起点和终点之间存在有效的路径,那么只要规划的时间足够长,采样点足够多,必然可以找到有效的路径。但是这个解无法保证是最优的。
采用PRM和RRT等随机采样算法生成的行驶轨迹,大多是一条条线段,线段之间的曲率也不不连续,这样的行驶轨迹是不能保证舒适性的,所以还需要进一步进行曲线平滑、角度平滑处理。代表算法是基于曲线插值的方法:RS曲线、Dubins曲线、多项式曲线、贝塞尔曲线和样条曲线等。
所有基于曲线插值方法要解决的问题就是:在图31上的若干点中,求出一条光滑曲线尽可能逼近所有点。下文以多项式曲线和贝塞尔曲线为例,介绍曲线插值算法的示例。
图31 曲线插值方法要解决的问题描述8JTednc
4.3 多项式曲线8JTednc
找到一条曲线拟合所有的点,最容易想到的方法就是多项式曲线。常用的有三阶多项式曲线、五阶多项式曲线和七阶多项式曲线。理论上只要多项式的阶数足够高,就可以拟合各种曲线。但从满足需求和工程实现的角度,阶数越低越好。
车辆在运动规划中,舒适度是一个非常重要的指标,在物理中衡量舒适性的物理量为跃度(Jerk),它是加速度的导数。Jerk的绝对值越小意味着加速度的变化越平缓,加速度的变化越平缓意味着越舒适。而五次多项式曲线则被证明是在运动规划中可以使Jerk比较小的多项式曲线。
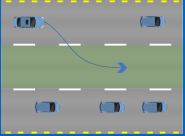
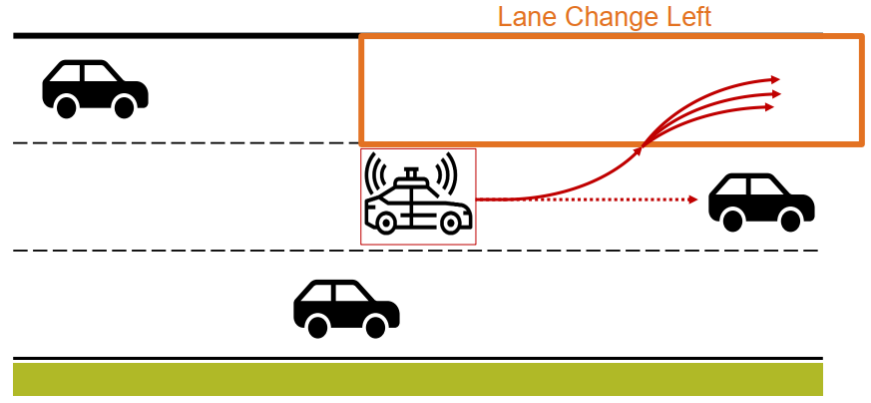
以图30所示换道场景为例,已知Frenet坐标系下换道起点和终点的六个参数s0、v0、a0、st、vt、at,采用横纵向解耦分别进行运动规划的方法,可得横向位置x(t)和纵向位置y(t)关于时间t的五次多项式表达式。
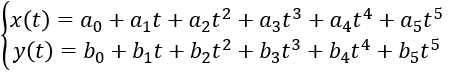 8JTednc
8JTednc
五次多项式中存在六个未知量,将起点和终点已知的六个参数代入便可这个六个未知量。然后根据时间t进行合并即可得到横纵向联合控制的曲线,即最终运动规划的曲线。
对于比较少的点来说,采用多项式曲线非常合理。但是当点比较多时,为了逼近所有点,就不得不增加多项式的次数,而由此带来的负面影响就是曲线震荡。退一步讲,即使震荡能够被消除,获得的曲线由于存在非常多的起伏,也不够光顺。而贝塞尔曲线的出现,正好解决了上述问题。
1959年,法国数学家保尔·德·卡斯特里使用独家配方求出贝塞尔曲线。1962年,法国雷诺汽车公司工程师皮埃尔·贝塞尔将自己在汽车造型设计的一些心得归纳总结,并广泛发表。贝塞尔在造型设计的心得可简单总结为:先用折线段勾画出汽车的外形大致轮廓,再用光滑的参数曲线去逼近这个折线多边形。
绘制贝塞尔曲线之前,我们需要知道起点和终点的参数,然后再提供任意数量的控制点的参数。如果控制点的数量为0,则为一阶贝塞尔曲线,如果控制点的数量为1,则为二阶贝塞尔曲线,如果控制点的数量为2,则为三阶贝塞尔曲线,依次类推。不论是起点、终点还是控制点,它们均代表坐标系下的一个向量。
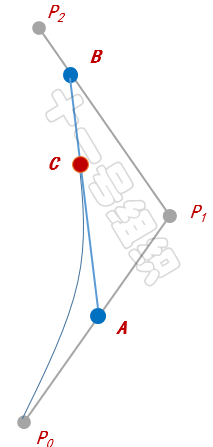
下面我们以经典的二阶贝塞尔曲线为例,介绍其绘制方法。如图32所示,P0和P2为已知的参数的起点和终点,P1为已知参数的控制点。首先我们按照起点、控制点、终点的顺序依次连接,生成两条直线。
接着我们以每条直线的起点开始,向各自的终点按比例t取点,如图中的A和B。随后我们将A和B相连得到一条直线,也按相同的比例t取点,便可得到C点,这也是二阶贝塞尔曲线在比例为t时会经过的点。比列t满足如下的公式。
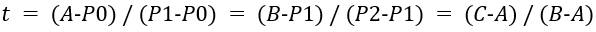 8JTednc
8JTednc
当我们比例t一点点变大(从0到1),就得到起点到终点的所有贝塞尔点,所有点相连便绘制出完整的二阶贝塞尔曲线C(t),用公式表达为。
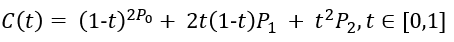 8JTednc
8JTednc
由二阶贝塞尔曲线拓展到N阶贝塞尔曲线,可得数学表达式如下。
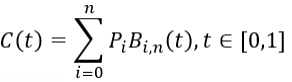 8JTednc
8JTednc
https://mp.weixin.qq.com/s/oNHDzdxMy_ciAok79kLDYg
https://mp.weixin.qq.com/s/Wxt-h3MovCKTbQd5GbFa4Q
http://blog.jobbole.com/101065/
https://mp.weixin.qq.com/s/hgT-a3Ug9578k1DmioRgUg
https://mp.weixin.qq.com/s/9Guin-EbTp4IL4Td_bZKzw
https://mp.weixin.qq.com/s/eHp9WOSJkajzx34FTYL3Kg
https://mp.weixin.qq.com/s/V1QlB3i-udRcxi3ZcTP68Q
https://mp.weixin.qq.com/s/KtHaKNyWd4ygrRersg8KJg
【9】运动规划入门 | 4. 白话RRT,从原理到Matlab实现
https://mp.weixin.qq.com/s/CXA5-gkPvk7juUS4CMMswA



 最前沿的电子设计资讯
最前沿的电子设计资讯

