
预期功能安全(SOTIF)的过程定义并传达了ADAS应如何验证以确保功能安全。所有的这些验证定义都被组织成场景,任何曾经发生过或可能发生过的事情,都可以在一个SOTIF场景中被定义出来。首先,为了更好地理解什么是SOTIF场景以及他们如何帮助用在整个开发过程,让我们回顾一下基础知识。
正如我们在本系列前两篇文章(为什么SOTIF是自动驾驶安全和难题的关键部分)中所讨论的,现今的车辆是高度复杂的机电一体化机器,通过电子电器架构将机械系统,软件,计算能力、传感数据和宽带容量以及执行器紧密结合在一起。这些电子电器系统使得车辆作为一个统一的整体,能够根据其所感知的情况以及设计的概念做出决策和执行。
这些系统的设计极大地受到安全考虑的影响。ADAS是这一设计过程的产物。他们是硬件、软件和通信系统,通过使用人机交互界面辅助驾驶车辆的人提高安全性并降低风险。
当驾驶的条件超过一个或多个系统组成的性能限制时,SOTIF有助于减轻暴露的风险和危害。他还能解决人为因素,例如可预见的系统误用或人类应该如何操作车辆的困惑
ADAS和SOTIF都是通过遵守国际标准来定义和管理的。他们共同致力于解决系统的预期功能安全以及可能出现的非预期功能失效。SOTIF的范围是通过工程师在试图消除风险的时候所形成的意图,并准确定义、测试与优化。因此,风险最终推动了定义给定系统和场景的安全状态。明确识别、量化和分类这些风险的过程是我们接下来要研究的。
什么是SOTIF场景?
在开始任何系统设计工作之前。必须首先定义系统可能遇到的每个场景的风险。毕竟所有这些工作的目的都是将风险降至最低。因此,在设计和构建系统以解决这些风险之前,必须试图量化这些风险。一旦拥有SOTIF意识的ADAS智能被开发出来,系统将拥有处境识别的意识。
出于此目的,场景被定义为一组条件和系列事件的详细计划。当识别出实际或潜在风险时,将其归类为四种SOTIF情景类型之一。任何曾经发生或可能发生的事情都可以在场景中被定义出来。可以对每个场景进行分类。该分类表明了该场景中的性质和风险,并提供了处理它的方法的出发点。
每个SOTIF场景都两个”非此即彼”的变量来解决基本问题,该场景本身是安全的还是本身不安全的?同时这两个答案中的任何一个都还包含另两个参数,风险是已知的还是未知的,结果是每个相关使用case都可以划分进这四类SOTIF场景。
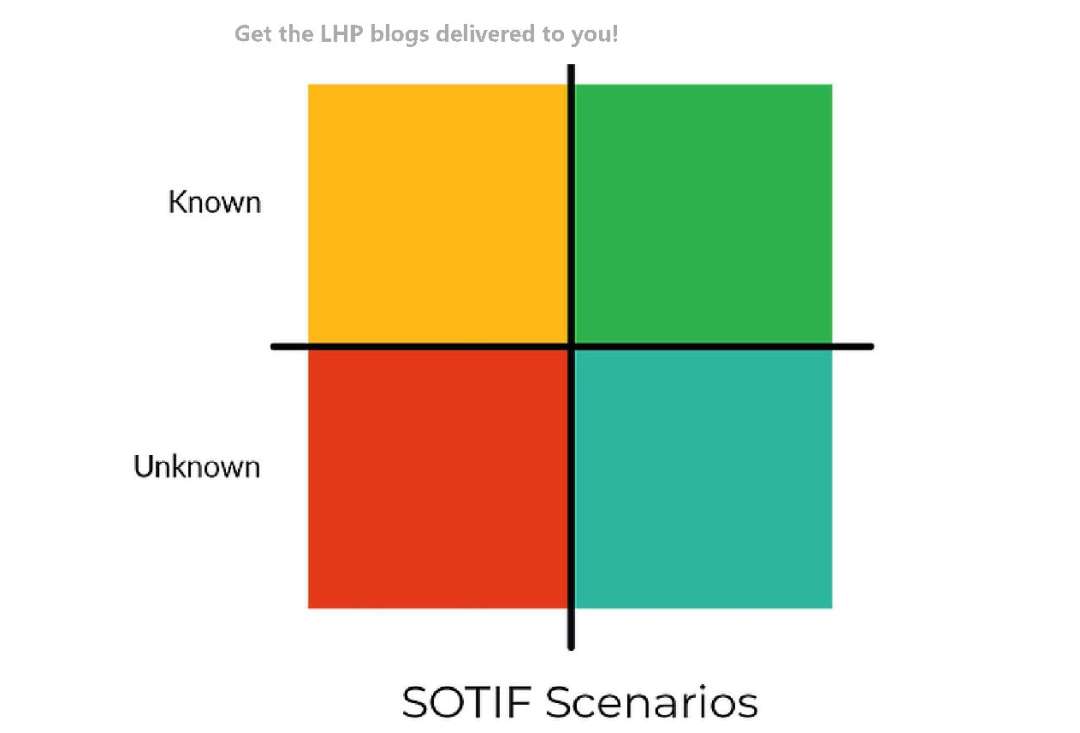
因为每种类型的风险都有其特殊性,所以每种风险都有不同的优先级和处理方式。
已知部分
第一步是尝试识别已知的内容,因为最基本的常识是我们需要做好我们的已经知道的内容。已知部分分为已知安全和已知不安全两类,这部分是我们必须尽最大努力解决的问题。
1.已知安全
安全操作/常规操作:一般的预期功能安全可以被应用与验证
2.已知非安全
车辆的运行受限于系统和传感器的限制,可以在系统级别部署冗余,并且可以谨慎地使用手动驾驶模式警报。独立的系统行为(及其预期功能)、与道路场景相关的其他随机触发事件、驾驶员对系统警报的忽视以及驾驶员可能的系统功能误用,都可以在系统级进行仿真和验证。此外,对于智能系统的功能,可以使用算法来验证端到端的响应时间,以确定性能限制来指导可能的改进。
在已知的部分中,我们试图识别系统中的弱点以发现疏漏。这通常从传感器开始,并可能扩展到其他器件。我们必须识别某些传感器的弱点,因为如果来自传感器的数据不准确或不可靠,这会导致系统下游的所有内容不在可用。
未知部分
测试已知事件是一个直截了当的过程,那我们如何测试未知部分,这就是比较抽象的部分了
3.未知的非安全部分
这部分是噩梦般的场景。难以预测系统反应以及其他部分。道路环境中常见、持续的场景或触发事件型场景可能交错出现,例如各种交通状况、公路驾驶、城市驾驶、医院区、学校区、道路施工区、服务车道和限制车道。通过配置例如HIL硬件在环的黑盒测试等技术,这些都可用来评估系统的定性和定量特征以及系统行为。
4.未知的安全部分
正常的预期功能可以被使用和验证,如果车辆具有安全且受监控的系统设计,则可以操作车辆
总之,我们必须创建未知的场景,然后看看我们的系统如何响应。高风险类别是未知的不安全部分,这其中是我们不知道哪些我们是不了解的,我们要做的是要把未知的东西变小,把无限的风险变小。我们正在努力让系统变得更聪明,从而增加我们在未知的不安全类别中取得成功的信心。
如何创建未知场景
在整个行业范围内,未知场景的具体数学描述尚未被完全定义。因此,我们需要一种方法来随机生成表示未知的场景。这里有一些指导意见:如果你不小心,你最终可能会花费大量的时间和精力来创建许多场景,这些涵盖了一些场景
您意识到其影响力不足以引起额外关注或者并不是真正的未知不安全情景,或者他本身最终可能是安全的,除了100%确定的无限随机性,没有其他机制。
因此,必须集中精力。集中注意力使用你从已知弱点中学到的东西作为输入,以便你重点关注这些。还可以添加一些统计分析,以尝试生成一些情景输入的统计数据。
比方说,其中一个场景环境可能是城市街道,另一个可能是乡村道路,也可能是高速公路,或者是双车道高速公路。它们都有一点不同,有不同程度的风险和挑战。那么,我们是否对它们进行相同的测试?不,有另一种方法。
创建一个实用的统计分布
如果我们进行研究,并能够显示车辆在每个场景中运行的频率,于是就可以得出一个分布,在每个场景中运行的百分比。因此,作为我们的随机场景生成的一个输入,我们最终应该得到具有相同类型分布的场景,因为从统计学上讲,这就是我们期望车辆运行的方式。我们应该把包括道路类型,天气条件,和其他因素考虑其中。
考虑到天气因素需要一种稍微不同的方法。在进行研究后,可能会发现,与晴天相比,车辆不经常在雪中行驶,也不经常在雨中行驶。在这些情况下。这些场景应该稍微调整一下,以避免出现恶劣天气因素。因此可以理解,在“正午阳光明媚”的场景中,功能更容易起效。然而,这并不能反映出现实的全貌。解决办法是不要强调晴天。即使这些类型的日子最终可能是主要的场景,也不要强调它们。调整你的输入,使其朝着不太理想的方向发展,并将其纳入你的测试计划。
随机生成SOTIF场景
SOTIF场景如何产生随机性?在整个行业中,这仍然是一个正在尝试和探讨的领域。但你具体怎么做?你如何实施它?这是许多人现在感兴趣的一个领域,但尽管有这种兴趣,该行业还没有实现一个具体的一步步实现的方法。
总结
任何已经发生或可能发生的事情都可以用SOTIF场景来定义,每个场景都可以被归入SOTF的四个分类之一:已知安全、已知不安全、未知不安全和未知安全。这种分类表明了该情景的性质和风险,并提供了处理该情景的起点方法。第一步是尽量涵盖已知的场景,包括已知安全部分和已知非安全部分,这些都是非常直截了当的。相比之下,测试未知的部分就成了一个更抽象的工作。未知不安全的情况是噩梦般的场景,你不知道哪些你不了解,你也不知道有多少风险。它在一定程度上是通过测试模拟(如HIL测试)来量化的,这允许以安全且经济高效的方式快速测试大量的场景。未知的安全部分可能会带来惊喜,但一个具有鲁棒性的系统设计可以吸收未知但安全的场景的大部分影响。
驾驶条件因道路条件和环境的不同而不同,采用统计分布来反映我们期望车辆在这些不同类型的条件下是如何运行的,在这些条件下,我们更倾向于测试不安全的场景。这有助于弥补一个现实,即行业还没有一个具体的计划来系统地将随机性注入工作中。我们行业在系统地管理这些挑战方面已经取得了重大进展,SOTIF发挥了关键作用。但是,要系统地创建真实地反映现实生活中混乱的随机性的测试,仍有许多工作要做。
 最前沿的电子设计资讯
最前沿的电子设计资讯

