

2021年4月,一段极狐阿尔法S华为HI定制版在城区复杂场景中自行驾驶的视频刷爆全网。在视频中,车辆灵活地穿梭在路况复杂的城市里,司机全程没有接管。

在此之前,量产车的智能驾驶最高水平,只能做到在高速路上巡航、变道、超车,在低速场景下跟车,占据普通人80%以上出行场景的城市路段,驾驶任务还得扔回给人类。很少有用户愿为如此孱弱的功能付费。
而极狐的这则视频,在一片“华为牛逼”、“Demo而已”的弹幕对垒中,勾勒出了一副真·智能汽车的景象:乘用车在城市中实现点到点的自动驾驶,过程中只需很少的人类驾驶员接管甚至零接管。
对大多数行业外的中国人来说,这是他们第一次感受到自身能力被智能驾驶汽车挑战。
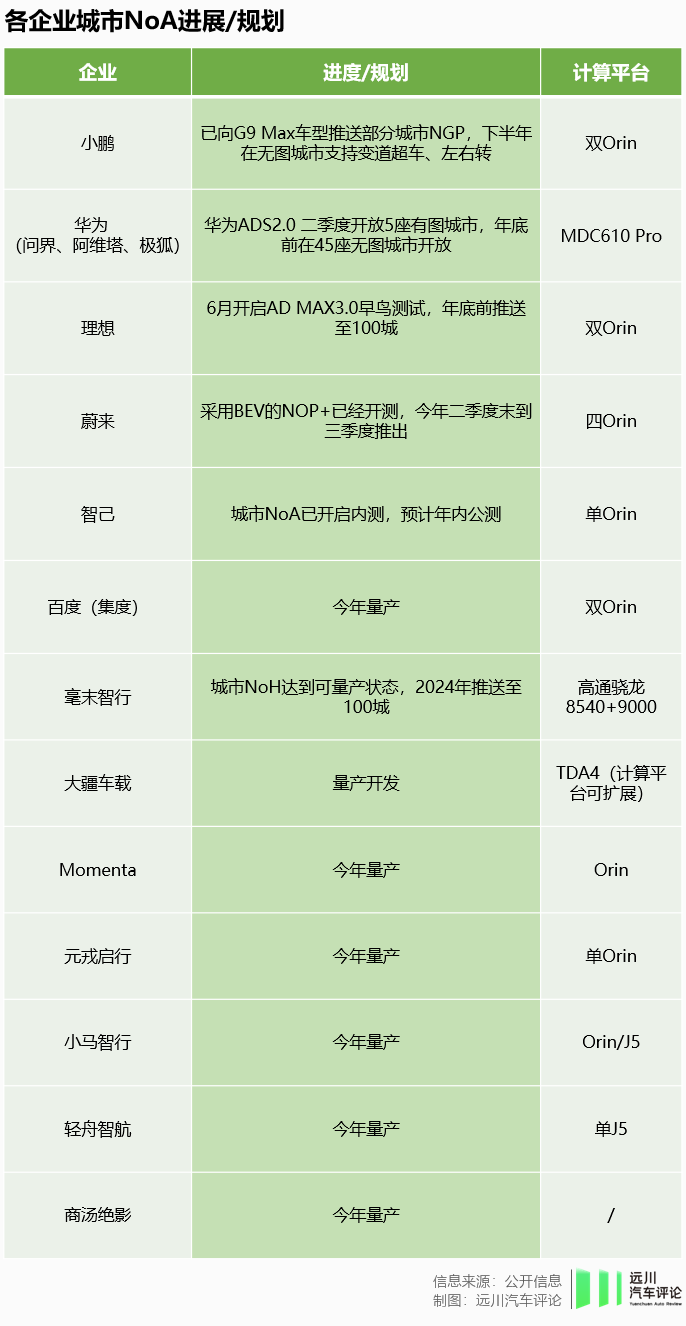
而在行业内,城市NoA(城市高阶智驾)的暗战已经开启,包括华为、小鹏在内的多个国内团队立项,尝试将其落地成一个可以交付的产品。两年时间中,造车新势力,传统车企的智能电动汽车品牌,智能驾驶供应商,不断有企业加入战局。
今年,城市NoA的竞逐在极短时间内,从水下进入白热化。十余家车企与供应商齐声宣布将在今年开启城市NoA功能量产。
这背后,一场行业的集体共谋,一次技术范式的全面革新,一个史无前例的超级工程,已然接连拉开序幕。
在智能汽车的叙事中,城市NoA被认为是通往自动驾驶的最后一块拼图,也是技术与商业的高地。
技术上,足够难的城市场景能够倒逼智驾能力进步,赋能其他场景;商业上,能解放80%行车时间的功能,将会成为车主愿意付费的刚需,让智能驾驶商业闭环成立。兵家必争之地,势必吸引来各方势力向其发起冲锋。
而在之前,冲向高地的最短路径是,硬件堆料。
2021年,小鹏尝试在搭载英伟达Xavier的P5上实现城市NoA(小鹏内部称为CNGP),但30T的算力很快成为天花板,团队必须进行大量算法适配与优化工作。小鹏智驾团队后来将这段经历看作他们的“工程地狱”,并在第二年转入G9高配车型的计算平台开发,后者算力为508T。
高阶智驾的硬件军备竞赛在去年达到顶峰。
 蔚来NT2.0平台标配4枚Orin
蔚来NT2.0平台标配4枚Orin然而,拼硬件参数行业风风火火,讲功能落地大家唯唯诺诺。
去年一年,仅有华为(极狐/阿维塔)、小鹏在少数城市开通了试点性质的城市NoA,无论是车企还是消费者,对这样的进度都难言满意。
高精地图在今年被推到台前充当罪魁祸首。
4月中旬,在问界M5智驾版发布会上,余承东透露,如果要做有高精地图的城市智驾全域覆盖,上海需要采集3.6万公里道路高精地图,但直到目前也只采集了2.2万公里,并且道路在持续变化。
在此前的高阶智驾技术栈中,高精地图提供了上帝视角与先验信息,能够为智驾车辆提供指引、为其感知系统减负。但囿于成本、技术和强监管,其采集与更新速度赶不上趟,拖累了车企高阶智驾进城的步伐。因而在今年,车企们开始集体抛弃高精地图(具体可参见我们的文章,高精地图红与黑:从智驾必备到车企累赘),卷向重感知、轻地图城市NoA。
随着上海车展的临近,这场竞赛陡然提速。
1个月之内,小鹏、华为、理想相继公开城市NoA规划:小鹏今年下半年将在无图城市实现自动变道超车与左右转,华为年底将在45城实现无图城市智驾,理想将这一数字提升至100城。蔚来、智己紧随其后,连以蔑视智驾著称的比亚迪都开始集结重兵。
 华为理想城市NoA隔空交火
华为理想城市NoA隔空交火一大批智驾供应商也摩拳擦掌,低算力需求的方案是他们争夺订单的利器。在他们口中,无图城市NoA的算力门槛,可以降到254T(Orin X),128T(地平线J5),乃至80T(大疆车载方案)。这些方案基本会在今年登上量产车。
在行业集体奔涌的热潮中,乐观的声浪一波接着一波:这将是城市NoA的大规模量产元年。
冷静的声音显得稀缺而寂寞。
3月底,在电动汽车百人会上,地平线创始人余凯劝诫行业保持理性:“目前L2++城区NOA还存在技术挑战,基本几十公里就需要接管一次,在研发上至少三年才会有较好的进展,因此到2025年时高速NOA仍会是量产主力。”
但没人愿意克制,包括余凯的合作伙伴和客户们。
今年3月,原本以L4自动驾驶为主营业务的轻舟智航,发布了基于单片地平线征程5的城市NoA方案,计划今年量产。地平线的重点客户理想,也在加速测试验证城市NoA功能——CEO李想带头成为001号测试用户,而在旅客客流创下近年纪录的五一假期,其智驾团队选择了加班冲刺以保证进度。
今年,伴随ChatGPT的大火,泛人工智能领域的竞争再度升级,具体到智能驾驶行业,所有人都在关注特斯拉的节奏。今年初,特斯拉向北美用户全量推送了FSD(Full Self-drving,实为高级辅助驾驶)。“FSD入华在即”的传言随即频繁响起,百度智能汽车事业部总经理褚瑞松认为,FSD会在2024年进入中国,并在2025年规模化开放。
没人愿意赌FSD是否会涌现成为智能驾驶的ChatGPT。在一定程度上,ChatGPT与城市NoA现在的技术栈同源,它们都采用了眼下让整个AI行业沸腾的神经网络模型,Transformer,名自变形金刚。
而在汽车行业,特斯拉最先将Transformer应用于量产车智能驾驶,比其他人早一到两年。
2021年8月,特斯拉举办的第一届 AI Day打响了如今城市NoA竞速赛的发令枪。
在那次AI Day上,特斯拉发布了基于Transformer的BEV(Bird Eye View,智驾车辆在鸟瞰视角下的环境感知建模),这项技术让智驾汽车的感知能力脱胎换骨,如今几乎被所有无图城市NoA方案采纳。
在此之前,量产车辅助驾驶的感知算法模块主要运行卷积神经网络CNN,其主要工作是一帧一帧地对图像进行分类、识别、追踪,将感知结果交由下游决策、规划、控制等模块。
作为已经商业化应用超10年的神经网络,CNN成熟、易用,但构筑在CNN基础上的智驾感知天花板也十分明显——
在它的世界里,空间是二维的(缺少“距离/深度”维度)、时间是断裂的(感知系统缺乏上下文记忆),各个传感器是各自为政的(各传感器时空坐标系不同,导致数据融合困难)。如果以人类作比,这将是一个双眼散焦、“声画不同步”且注意力时刻涣散的糟糕驾驶员。这是辅助驾驶此前只能胜任简单场景的重要原因。
而特斯拉最早意识到,Attention is All You Need。在2021年夏天,特斯拉团队在连续试错后,选择了这样一条技术路径:
设计更庞大、更复杂、参数更多的感知算法模块,利用Transformer的注意力机制,将各个传感器统一到同一个连续的四维(三维空间+一维时间)时空中。车辆进行驾驶决策的基础,不再是健忘症看二维图像,而是正常人看流畅三维视频——智能驾驶迎来了一次“时空观”的飞跃。
 上图为基于CNN的二维感知,下图基于Transformer的BEV感知
上图为基于CNN的二维感知,下图基于Transformer的BEV感知
一个高度巧合的例子是人类婴儿的成长。刚出生的几个月里,婴儿眼中的世界与成人有明显区别,他们无法理解深度,也缺乏空间记忆。但大约在半岁的时候,随着看过的物体越来越多,大脑中神经突触间建立的联系爆炸式增长,婴儿会开始“涌现”出视觉深度的概念和对被遮挡物体的记忆。
然而,婴儿只能慢慢成长,智能驾驶则在开挂进化。
2022年,特斯拉在新一届AI Day上推出了能够检测通用障碍物的Occupancy Network占用网络。同年,国内新势力车企相继完成了激光雷达的批量装车,智驾车辆的感知能力变得前所未有地强大,近乎成年人类——众所周知,人类开车并不需要高精地图。
由此,伴随着Transformer+BEV、占用网络的声名渐响,系统感知能力的史诗级提升,智能驾驶摸索出一条可以大规模、批量化进城的道路——大模型。西风东渐,国内企业纷纷跟进,高精地图逐渐从智能驾驶的小甜甜变成了牛夫人。
(关于高精地图的生死去留,其实远比一刀切地扔掉要复杂。后续我们将推出相应文章,欢迎添加微信讨论)
只不过,与技术的大跃进一同到来的,是骤然拉高的门槛。
无论是对特斯拉还是对其他企业,大模型都是一枚沉甸甸的硬币。
正面,是智驾系统上限的提升,反面,则是智驾整个体系架构的更改,形式上不能完全说推到重来,但工作量与难度绝对是超级加倍。
原因并不难理解:基于相对轻量CNN的二维感知,升维到了基于Transformer的四维感知,升维的条件是,需求的数据与算力指数级增加,智驾数据收集、云端算法训练、车端算法部署三个重点环节需要全部革新。
一个AI行业的热知识是,Transformer对数据规模有硬性要求,如果数据量达不到要求,其性能反而会比CNN更差。因此,向Transformer切换的前提是,能获得足够的数据喂养它。
对此,智驾车辆保有量高的车企往往有更大优势,但实际上,智驾功能激活后的行驶里程才是真正的关键数字,这些里程中捕捉到的那些系统应对不佳的瞬间,被行业称为Corner Case,才是更有价值的数据,它们是智驾系统的“错题本”。
对这些数据进行标注仍是刚需,但数据形式切换后,纯人工标注无力应对上万小时的视频以及人眼并不熟悉的点云,这必须启用半自动/自动化标注——在接稳方向盘之前,神经网络会先取代数据标注员。
这只是开始。因为收集更多、更高质量的数据是一码事,用它们训练出足够强大的模型则是另一码事。
一方面,在向大模型切换后,由于数据从图像为主转向了视频流为主,其体积呈幂次方膨胀,将达到PB乃至EB级别(1EB=1000PB=1000000TB)。
另一方面,基于Transformer的智驾大模型结构空前复杂,其训练模型参数量通常上百亿乃至上千亿,比如毫末智行的智驾模型总参数量就达到1200亿。
在海量数据中训练海量参数的大模型,需要的是天量算力,只有大型云计算中心才能胜任。
在2022年,特斯拉为了训练占用网络,使用了14.4亿帧视频数据,数据量超过30PB,需要10万个A100 GPU训练小时。
而其自研的DOJO超算仍处于开发状态,为应对快速膨胀的数据处理需求,特斯拉去年将其最大的GPU超算集群提升至7360张A100 GPU,这些GPU总算力将近2.4 EFLOPS。这在当时是全球第七大GPU超算集群,仅硬件成本就超过1亿美元。
由于自建算力成本过于高昂,国内企业大多选择与云服务大厂共建云计算中心。
在已经公开信息中,小鹏与阿里云在乌兰察布共建了600PFLOPS超算——对应约2000块A100,毫末智行与字节火山引擎共建了670PFLOPS算力,理想出于供应安全拒绝透露自身拥有的云端算力数据,但表示在国内车企中领先。
 小鹏与阿里云共建的智算中心
小鹏与阿里云共建的智算中心
更多国内智驾企业没有披露自身掌握的云端算力。但游戏规则对所有人都适用:算力不够,则训练更慢,算法迭代更慢,被竞争对手拉开差距的可能性就越大。
而在算法训练之后,最难的部分在于算法部署——在云端,训练算法的算力可以通过堆叠数千乃至上万块GPU获得,对实时性并不敏感;但在车上,算法必须实时推理,而运行神经网络的芯片只有一两块,算力通常在数百T。
并且,车端目前的智能驾驶芯片,并不是为Transformer准备的。
由于CNN仍在智能驾驶中占绝对支配地位,市面上已量产的智驾芯片,其计算架构几乎都为适配CNN高度特化。表现在硬件上,芯片普遍内建大量相同的MAC阵列(一种适合并行计算的运算单元),对CNN进行硬件加速;在软件上,芯片主要支持CNN使用的算子(可粗略理解为计算公式)。
然而,相对于更轻量、简单的CNN,Transformer不仅仅是模型更宽、更深、参数更多,其算子复杂度也更高,计算单元需要频繁地从存储单元中存取数据与指令——要运行这样的算法,芯片不仅算力要更大,存储与带宽性能要更强,还要同时具备较强的串行与并行计算能力,支持更多元化的计算类型。
算法快速演进的结果是,“英伟达对Orin在软件层面做了大量的优化与弥补,但本质上并没有解决硬件加速的问题”,理想汽车自动驾驶副总裁郎咸朋告诉我们。同样的情况对其他智驾芯片企业也大致成立。
芯片企业试图尽力满足变化的需求,英伟达去年发布了舱驾一体芯片Thor,地平线则在上海车展期间推出了下一代智驾芯片架构纳什。它们都有更大的算力,更强的带宽/存储,更均衡的计算能力,对Transformer有更好的硬件级支持。
这些芯片量产上车的时间将在2025年乃至更晚,但车企们等不及。
 地平线下一代智驾芯片架构
地平线下一代智驾芯片架构
在更强大的芯片问世前,车企、供应商、芯片公司必须在软件上加倍努力,将复杂的算法压缩到条件有限的芯片上。一个有能力将Transformer轻量化部署的团队,此时将表现出更强的竞争力。
大疆车载今年公开表示,有能力在80T算力平台上实现城市NoA。而此前行业传闻称,大疆车载已经获得比亚迪城市NoA项目定点。
高阶智驾通向城市的道路上,大规模、高质量的数据收集,天量算力下的算法训练,资源受限下的算法部署,环环相扣,又难度递增。
如果要保证体验领先,这对一家车企的要求会是:在台前,有一个强大的产品与销售团队,打造并卖出了一大批智驾功能保持常驻的车队,以收集有效数据;幕后,需要一个质量极高的智驾团队,一边自行打造部分不成熟的工具,一边搭建起一条高度自动化的数据管线,对算法快速迭代。
这将是一场名副其实的销金游戏。李想今年三月在公开演讲中表示,要做好城市NoA,投资要20亿美金起,有不少公司会在中途选择放弃。
2022年7月,特斯拉人工智能高级总监Andrej Karpathy选择离职,并在今年2月回到了Open AI。他的离职在业内引发了一阵不小的轰动,数家国内车企的智驾负责人发文回顾他的贡献,连马斯克也罕见地送出顶格彩虹屁,“与你共事是我的荣幸。”
 让马斯克感到荣幸的男人
让马斯克感到荣幸的男人任何一个怀有AGI理想的人都难以抗拒Open AI的吸引力。这里有微软提供的数万块GPU,已经训练出了GPT4,后者在多项技能测试中超越了大多数接受过高等教育的人类,而后续还会有更强大的GPT-5——顶级天才们有机会在这里成为硅基生命的上帝。
并且,活在物理世界的人类对活在赛博空间的ChatGPT仍有着极大的宽容度。
即使是持续地胡说八道,ChatGPT也可以谦卑地认错并取得使用者的谅解,因为它在物理上并不会对使用者造成即刻的影响(尽管它正在全球各地迅速消灭相当一部分人类赖以生存的岗位)。
相比之下,人们对智能驾驶汽车则严格得多,因为一个错误的输出可能就会让车辆径直撞向路边。过去五年,全球媒体没有放过任何辅助驾驶伤亡案例,特斯拉首当其冲,蔚小理也相继被推上过风口浪尖。
不对等的责任与前景,让行业已经出现AIGC吸引智能驾驶人才转行的迹象。毕竟,在前者的工作像是充当下一个世代的造物主,而在后者的工作,则更像是在众人的密切注视下,翻越一座比一座高的大山。
面对还看不见终点的征途,付出真金白银的用户与顶级人才团队都急需确切的目标和时间节点。
企业们纷纷许下诺言,随着系统能力的提升,驾驶员接管车辆的次数将会越来越少——马斯克会不时在推特上宣传一些零接管的智驾体验,小鹏计划2025年实现城市NoA百公里小于1次接管的目标,华为则声称其高阶智驾系统ADS2.0的平均人工接管里程已经从100km提升到200km。
但当下的现实是,人们对城市NoA需求最确切、最能减负的场景,如复杂十字路口通行(含转弯、掉头)、早晚高峰/节假日拥堵,仍然是智驾系统的弱势场景。
在我们体验过的城市NoA功能中,一旦上述场景叠加车流密集、人车混行等路况,系统的应对将变得不稳定,此时无论是出于安全还是效率考虑,都更适合人类接管。
美好许愿与现实的落差之间,是城市NoA接连不断的工程挑战。
一个事实是,即使是Transformer、BEV和占用网络这些让业界竞相追逐的突破,目前主要解决的仍是智驾车辆的感知问题,在完整的智能驾驶技术架构中,这之后还有依旧困难的决策/规控环节。
在城区的复杂交通流下驾驶,需要建立对不同类别交通参与者的交互策略,理解人-人、人-车、车-车关系,作出预判、进行博弈、即刻修正。只是截至目前,尚无任何企业的城市NoA功能可以普遍而连续地做到这一点,这仍是老司机的专属技能。
一些企业选择彻底皈依大模型——他们正在用神经网络取代基于规则的决策/规控算法,利用大模型涌现出来的常识与推理能力,让智能驾驶表现得更像老司机乃至超越人类司机。
智驾系统所有算法都交由神经网络负责的方案,行业称之“端到端”,理论上它将有更强大的适应性与性能上限。
特斯拉在这条道路上一马当先。目前特斯拉的FSD算法绝大多数已经神经网络化,根据马斯克画下的饼,FSD V12将更进一步,实现端到端的智能驾驶,只是时间未知。

更多企业对端到端仍充满顾虑——这将把智能驾驶整个系统“黑盒化”,缺乏可解释性,对问题的追溯与修正将变得困难。
小鹏智驾负责人吴新宙与理想智驾负责人郎咸朋都认为,端到端的方案在一段时间内都将处于技术探索而非实用的状态。吴新宙要求团队,能用数学方法解决的问题,就不用深度学习。
不过,神经网络在智能驾驶算法中占比越来越高的趋势已难以逆转。
小鹏与理想的智能驾驶产品经理都放出风声,两家企业将在今年上线的城市NoA功能中,上线基于神经网络的预测算法,这将显著提升智驾车辆在城市道路的博弈能力。
然而,现实的复杂度依然远超神经网络的拟合能力。
小鹏的智驾产品经理在分享时提到,他们发现一套智驾算法原封不动地去适应每个城市不太可能。比如,上海是立体化的城市交通,有大量会对视野和定位造成干扰的高架桥;广深则可能有更多行为难以预测的行人与电动车。因此,在进入一个城市之前,算法会针对性地吸收当地数据进行小比例地微调。
而特斯拉那些令人惊叹的FSD全程无接管视频,也大多出现在大本营湾区,而不是纽约的曼哈顿。
这意味着,城市NoA的扩张计划会是一场持续且绵长的开城活动,而不是北上广算法团队一阵加班,车辆就能在千里之外的二三线城市齐刷刷开通功能的“Coding Changes World”式浪漫故事。
工程的世界里没有银弹。
早两年,智能驾驶行业有过攀登珠峰南坡还是北坡的争论——选择从辅助驾驶到自动驾驶的渐进式路线,是攀登稍微平缓的南坡;选择直接突破L4自动驾驶,是挑战陡峭的北坡。
后来随着特斯拉证明渐进式路线更能规模化,争论偃旗息鼓,似乎所有人都看到了一条最终通往自动驾驶的可行路径。然而,当高阶智驾要真正大规模进城,无论是从南坡出发的企业还是由北坡改道南坡的公司,都会直面严肃的问题:他们的任务难度远远不是登山,而是登月。
作为能对物理世界即刻造成影响的人工智能,城市NoA将要对抗沉重的现实引力:它们不止是性能、成本、可靠性的不可能三角,还有人机共驾过程中艰难的用户期望管理、几乎不可避免的伤亡,以及相应的强力监管。
对所有城市NoA的参与者来说,坏消息是,他们将要挑战的,很可能是民用工业有史以来复杂度最高、约束条件最苛刻、实现难度最大的超级工程。
 最前沿的电子设计资讯
最前沿的电子设计资讯

