

上篇【从大语言模型到通用人工智能】说到大语言模型将引发第四次产业革命:智能革命。本篇roadmap一图流开局。欢迎对“降低推理计算量”(软件解决方案)、“提高算力性价比”(硬件)、“提高资源利用率”(体系结构、编译器、数学库、驱动)感兴趣的同仁加入沐曦,也欢迎国内外友人洽谈合作。废话少说,进入正题。
“我们做工程有两个大目标,一个叫求极致,在特定维度或者核心技术上突破技术极限,比如,最快的超级计算机……另一个叫求通用,这类系统的设计要求约束多,可快速迭代,使用范围广,比如高性能计算机。这两类系统在相互促进和相互转换的过程中,存在一些内在规律。”
孙凝晖院士,CNCC 2021
最近朋友圈里的大佬们都在转发Sam Altman的“智能摩尔定律”(奥特曼定律?):宇宙中的智能将每18个月翻一番。作为一个有幸深耕了微电子十余年的小萌新,我推断,未来普惠化大模型的商业模式将走上一条类似集成电路产业的路线。
要理解这个推断背后的逻辑,我们需要对大模型商业应用的各个环节进行一番考察。本节在分析transformer模型,考察大模型应用中预训练、微调、推理这三个环节的潜在业务模式之后,研判预训练的成本大头在数据清洗,而微调和推理的主要成本则是算力芯片(即GPGPU)的一次性购买费用的折旧成本。

也许是受到流行科幻文化的影响,很多人一说强人工智能的应用场景,脑海中出现的就是类似机器人宠物、机器人劳工之类的具身化的、有自我意识的形象。然而,这些幻想不可能经由当下主流的transformer机器学习的技术路线通达。
Transformer模型为基础的大语言模型更像是一个数字大脑:擅长做知识归纳和检索,这将极大地提高人类在创意、咨询、教育领域的工作效率,以此彻底改变人类社会的形态,我在上一篇【从大语言模型到通用人工智能】中详细地分析了这一观点。Transformer不会是演化的终点。AGI不会基于transformer模型。但立足当下,transformer将是未来三年内大算力芯片最重要的workload。
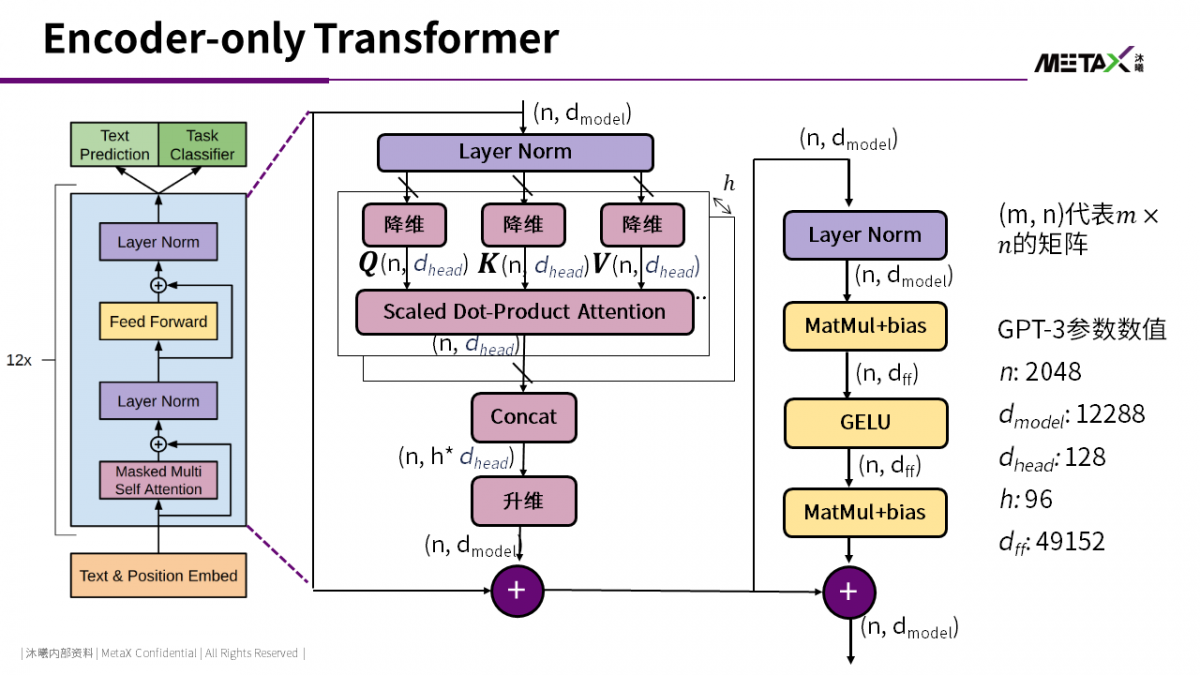
上图展示了GPT-3中transformer模型的结构。GPT-3中有96-layer的attention-FFN (Feed-Forward Network) 层。每个attention-FFN层的细节如图中所示。
最近研究认为,FFN中以key-value的形式保存了海量知识,attention则用来分析上下文关联 [1]。对于GPU而言,attention-FFN中的大量矩阵乘法非常适合GPU运算单元。这些矩阵乘法的中间结果需要保存在显存之中。例如,batch size=32时,(n, dff)的矩阵元素数量为32 * 2048 * 49152 = 3,221,225,472 (3B)。因此,目前人们大多使用具有HBM的V100/A100运行GPT-3的训练和推理。大模型的模型参数会有多大的?对于一个attention-FFN层,其参数就有
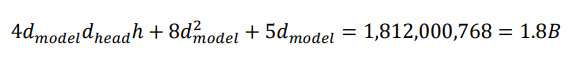
再乘以96个layer,参数数量可达到174B。GPT-3另外还有少量的token2embedding和position encoding参数,最终参数数量Nparam为175B。
可以预期的是,未来的大模型可以继续通过增加embedding维度dmodel,以及增加层数,继续增加参数数量。
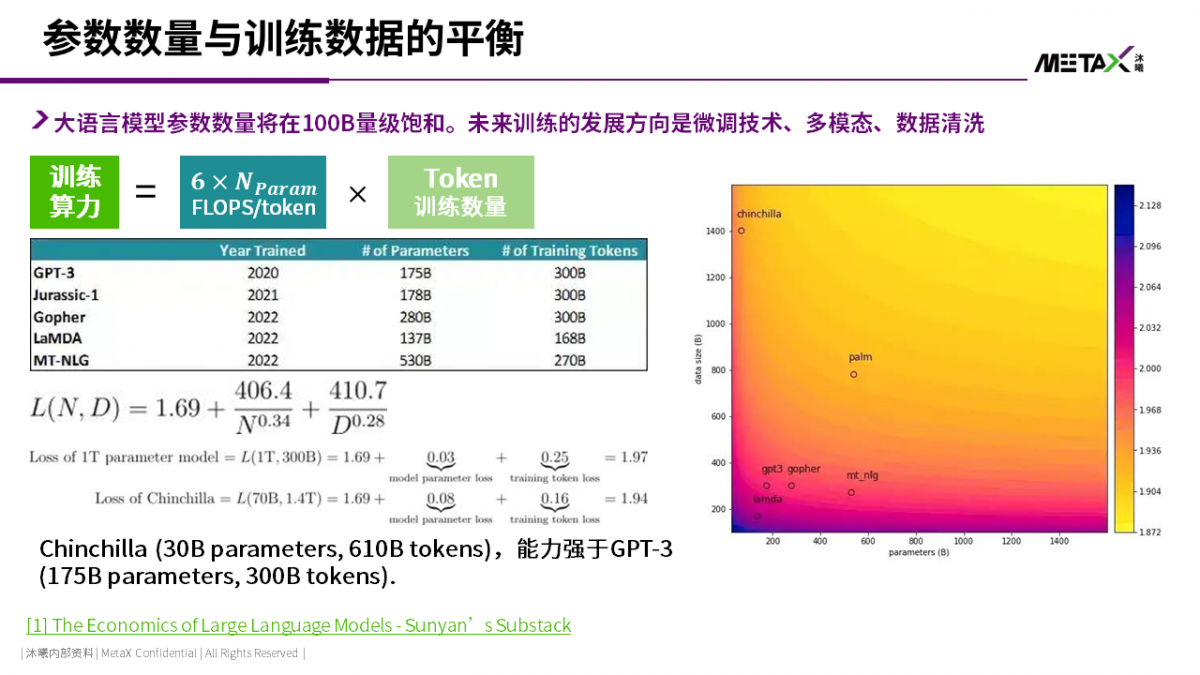
Deepmind在2022年的一篇论文发现 [2],预训练模型的能力,除了跟模型参数数量相关,更与预训练时使用的token数量相关。目前看来,单一语言模态的大模型,100B量级的参数足以满足大多数知识检索和浅层推理的需求,但充分释放这些参数的全部潜力,需要使用1000B量级的训练token。对于英文而言,Wikipedia + ArXiv + C4 + Github + Common Crawler的数据量几乎足以满足需求。但中文能否有如此高质量的语料数据库,目前依然存疑。Transformer is all we need, for now.回想2017年,Google的研究员在写“Attention is All You Need”论文时,大概也没有想到论文提出的transformer模型会在几年后掀起一场席卷全人类的风暴(不然他们也许会用一个更严肃点的标题?)。马后炮地回顾一下,transformer模型之所以成为了大模型的使能技术,大概有以下三个原因:
Transformer中全是矩阵乘法。考虑到GPGPU架构就是为高效执行矩阵乘法设计的。而在2008年之后,GPGPU暴算力的速度远快于其它类型的芯片,最终在2020年左右算力终于满足了训练大模型的需求。
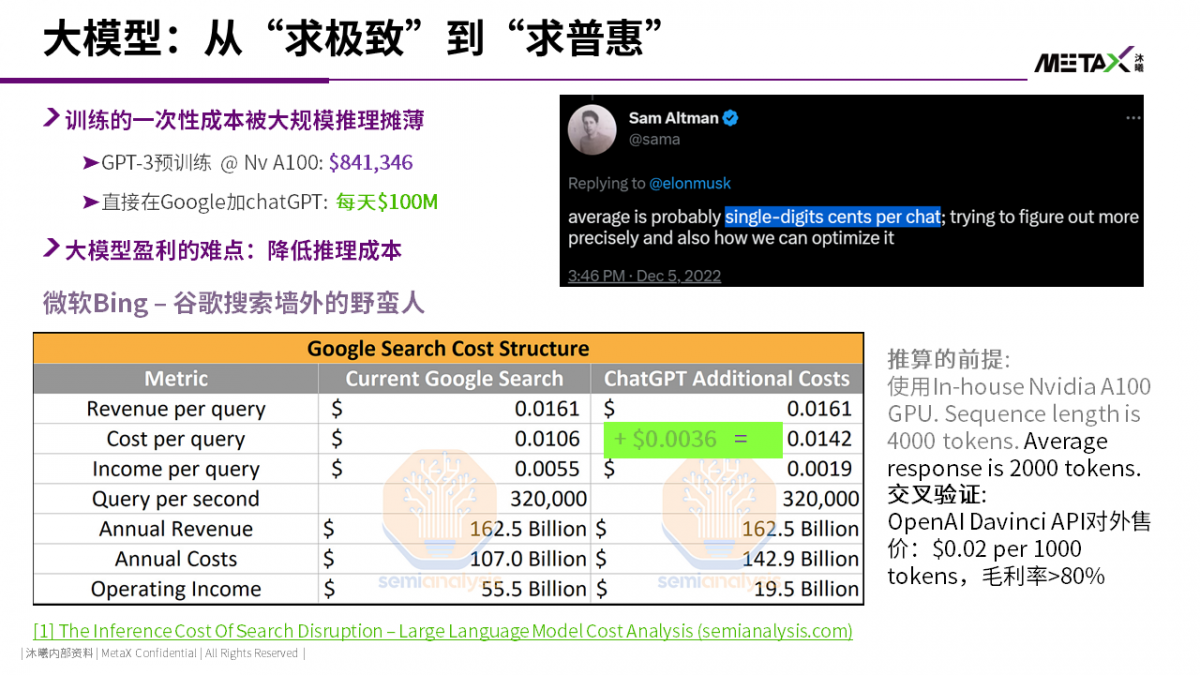
ChatGPT对搜索业务的颠覆,2月以来分析的文章已经汗牛充栋了。核心观点就是目前大语言模型推理成本极高。如果Google直接将ChatGPT简单地集成到搜索业务,$0.0036/query的成本将使得Google搜索“印钞机”彻底崩盘。
详细分析推荐The Inference Cost Of Search Disruption – Large Language Model Cost Analysis (semianalysis.com)和ChatGPT背后的经济账 - OneFlow深度学习框架。
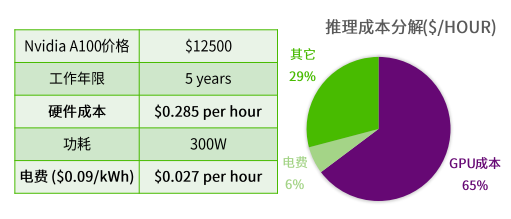
根据我们的推演,如果将Nvidia A100 GPU按照5年寿命线性折旧,那么$0.0036/query的推理成本中,有65%的比例是购买GPU的折旧成本。
因此,大模型可以普惠大众的关键难题,是如何提高芯片的算力性价比。
GPT-3预训练模型,早在2020年就随着论文“Language Models are Few-Shot Learner”发布了,当时在自然语言处理学术圈外,并没有太多人关注(两年前提起OpenAI,大众想到的还是dota2 AI)。从使用效果上来看,GPT-3预训练模型只能仿写prompt,外行人完全看不出来OpenAI研究的意义。

之后的两年,OpenAI开展了大量的指令微调 (Instruction Fine-tuning) 的工作。具体而言,OpenAI将不同的任务抽象为(instruction, output) 二元组,喂给模型,在反向传播中更新模型参数。研究者发现,GPT-3逐渐表现出了对特定任务的理解能力,回答的形式不再是简单地仿写。但回答的内容经常胡言乱语,并且表现出对性别、种族、意识形态的强烈偏见。此外,指令微调依然需要很大的数据集,而这种二元组数据集类似有监督训练,比预训练使用的无监督训练数据集更难获取。
为了解决获取微调数据集的困境,同时减少对大模型的偏见,OpenAI在微调中以RLHF (Reinforcement Learning from Human Feedback) 之名引入了强化学习方法,又称对齐 (Alignment):OpenAI利用了一种对人类preference建模的可微分数学模型,然后让人类在OpenAI的多个回答中根据是否符合人类价值观进行排序,最后再反向传播更新模型参数。经过了几个月的努力,ChatGPT诞生了。之后,用户在使用ChatGPT时,发现特定的提问方式可以获得质量更高的答案。这就是最近看起来很神秘主义的prompt engineering(像是献给Deus ex Machina的祷告辞)。注意,相比微调,prompt engineering并没有修改模型参数。Prompt engineering本质就是给大模型设计符合人类习惯的API。从ChatGPT诞生的过程可以看出,微调的算力成本远大于预训练,难度也远高于预训练。OpenAI至今没有公开ChatGPT的微调方法细节。“2013年反乌托邦科幻神剧《黑镜》S02E01,讲述了一个利用亡夫在社交网络上的留下的信息,塑造了一个具有人工智能的假男友的故事。这个故事所需要的人工智能技术,在2023年已经完全成熟。我相信当模型微调和对齐的成本下降到数万美元时,会有大量的创业公司开展类似的业务。” 【从大语言模型到通用人工智能】由此可以导出本节开头的结论:OpenAI提供预训练模型,类似TSMC;大量从事面向特定应用领域微调和对齐的公司,类似集成电路产业从业人数最多、产值最大、技术附加值最高的fabless公司。一次成功的模型微调,就像是一次成功的tape-out。
“Moore's Law is not dead. It's not slowing down. It's not even sick."
黄汉森,TSMC研发副总裁,Hot chips 2019
“Moore's Law isn't possible anymore."
黄仁勋,Nvidia总裁,CES 2019
为了给大模型的微调和推理降低成本,我们需要将目光转向集成电路的摩尔定律。按照排中律,上面两位黄总看似相互矛盾的发言,肯定有一位是错的。然而现实世界比逻辑世界复杂多了。摩尔定律到底是死是活?我相信这个问题困扰过每个微电子领域的学生。20世纪90年代以来,每年都有学者跳预言家,指出摩尔定律已死。然而集成电路的工艺标称尺寸一路从0.5um狂飙到了3nm,只不过3nm芯片上已经不会有任何一个尺寸测量出来是3nm(广电总局快来管管虚假广告)。
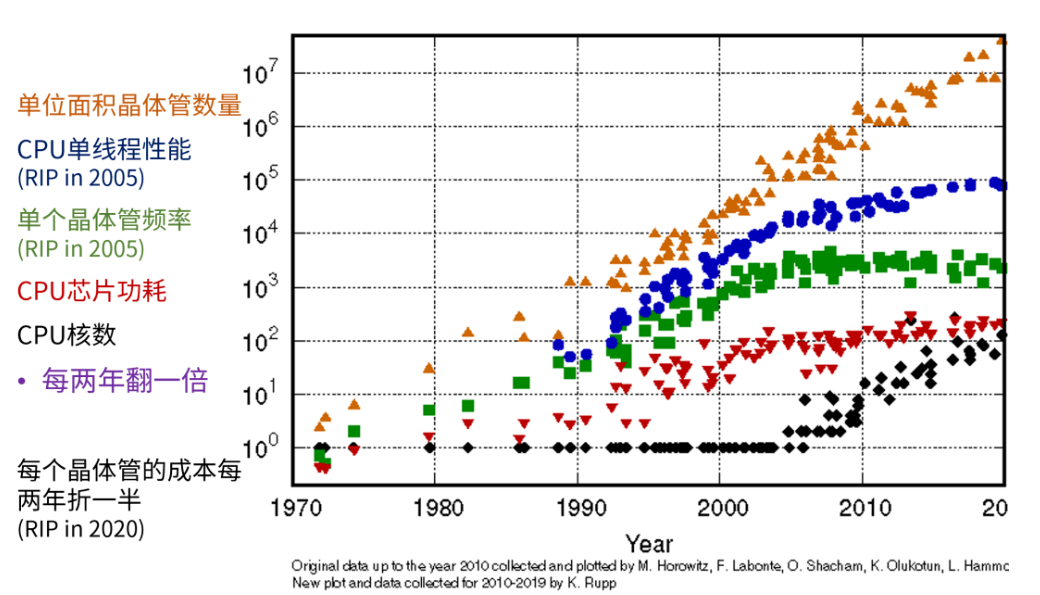
简单地解释,摩尔定律不是一个定律,而是由芯片相关多个表征参数所构成的定律族。这些参数的共同特征都是每两年翻一番或折一半。
上图是CPU性能相关参数的摩尔定律,可以清晰地观察到,2005年之后,由于Dennard Scaling终结,“功耗墙”出现 【异构编程模型(2):溯洄从之,道阻且长】,CPU频率、单线程性能的摩尔定律已死。但单位芯片面积晶体管的数量依然在指数增长。时间来到2023年,摩尔定律也面临着越来越严峻的挑战,越来越多的“摩尔定律已死”,比如晶体管栅极面积、单位面积引脚数等。全局来看,摩尔定律面临边际效用递减的困境。但是通过工艺创新、材料创新和先进封装创新,单位面积的晶体管数量依然在指数增长,因此单个芯片的能力和复杂度依然在随着摩尔定律指数提高。本文主要关注以GPGPU为代表的大算力芯片发展趋势。因此本节我们将首先介绍最近终结的两个摩尔定律:单晶体管成本(RIP in 2020)、SRAM密度(RIP in 2022)。
在戈登·摩尔1965年的论文中,他特别强调了平均单个晶体管的成本每18个月(后来调整为24个月)降一半。这一条定律结合每24个月芯片单位面积晶体管数量翻倍,确保了新一代工艺下同等面积的芯片售价不变。去除通货膨胀,消费者可以以相同的价格,享受硬件的升级。然而,这一美好的幻象在2020年左右被彻底打碎。
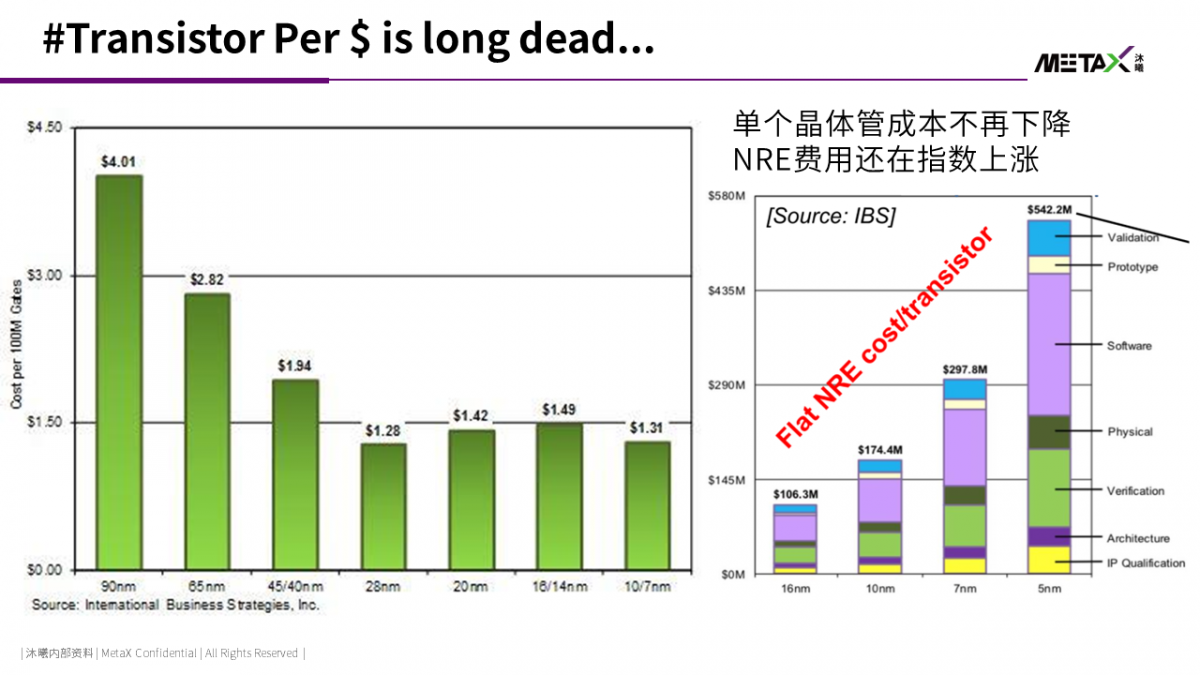
IBS报告显示所示,进入28nm以下工艺后,首发时平均每个晶体管的成本不再下降。虽然随着工艺成熟度的提高,每个工艺节点后期,成本依然有下降空间;但是工艺能成熟的前提时有大量用户。目前只有苹果能用得起TSMC 3nm工艺。
当单个晶体管的成本不再随着工艺的提升而下降,同时单位面积晶体管的数量依然在指数增长时,同样面积的芯片的成本也必然指数增长(皮衣黄:4系显卡价格暴涨,不是我想黑你们游戏佬的钱,是TSMC在黑我的钱)。
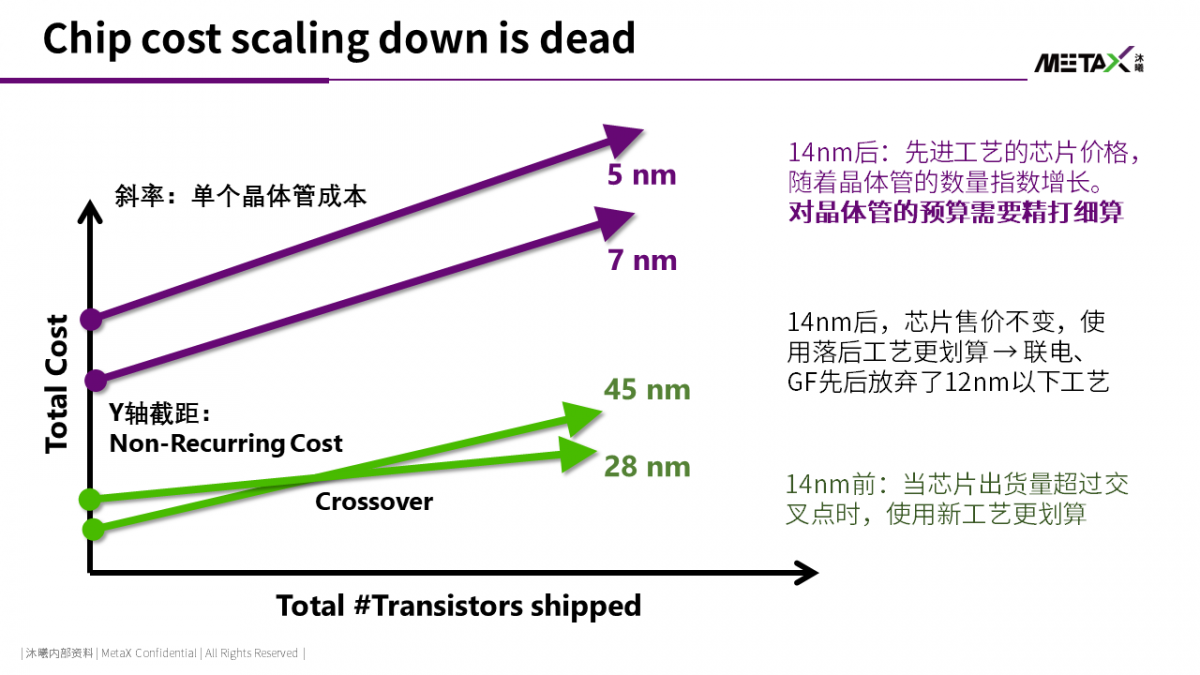
如果同时考虑到随着新工艺暴涨的一次性费用,先进工艺的成本问题将愈发严峻。如上图所示,28nm以前的成熟工艺,随着芯片出货量的增加,芯片生命周期总成本中会有一个交叉点:新工艺的总成本在越过交叉点后会低于旧工艺。因此,集成电路是一个赢者通吃、规模效应非常明显的行业:芯片卖的越多,单个芯片的平均成本将越低。
但7nm后的先进工艺,随着单个晶体管的成本不再下降,新工艺对旧工艺的成本交叉点消失了。这将对整个芯片行业产生深远影响。
对于GPGPU而言,SRAM微缩已死是一个更坏的消息。Nvidia首席科学家William Dally在2020年的论文“Domain-Specific Architecture”研判当前芯片设计的约束条件:“logic is free; memory dominates (逻辑免费,存储主导)”.对于GPU的架构设计而言,在芯片上堆算力单元并不困难,难点是如何将数据通过存储子系统供给算力单元。
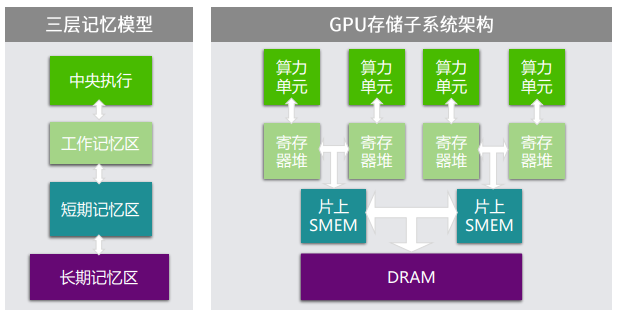
认知科学中对于人类的记忆 (也译为memory) 有一个三层记忆模型,用来类比GPU的存储子系统非常合适:工作记忆区缓存当下正在用的数据,类比距离算力单元最近的寄存器堆;短期记忆区缓存短期内有复用的数据,类比GPU的shared memory和片上cache;长期记忆区缓存人的所有记忆,类比GPU的显存。GPU上的算力单元,需要从最下层的显存数据池中,向上一级级地抽取数据。
当下主流GPU的“工作记忆区”和“短期记忆区”使用片上SRAM实现,“长期记忆区”使用片外DRAM。经验上GPGPU芯片上的计算逻辑和存储晶体管数量在6:4比较合理。根据前面对Transformer模型结构的讨论,GPGPU上,为大模型推理提高算力资源利用率的关键问题,是考虑如何尽量减少对片外DRAM的访问。数据需要尽量在片上的SRAM之间循环流动。因此GPGPU对片上SRAM容量的需求是极大的。
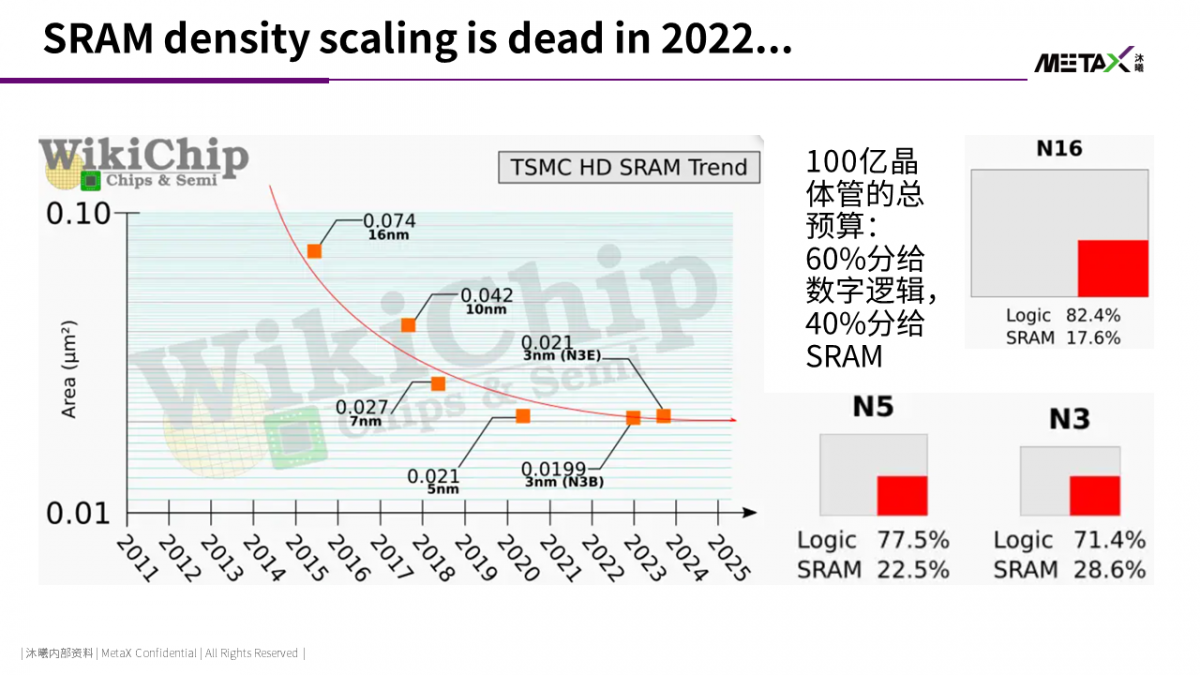
根据TSMC在IEDM 2022上的论文 [3],TSMC 3nm工艺下SRAM的密度,相比5nm而言,几乎没有提升。于是,如果总晶体管的预算还是在logic和memory之间按照六四开分配的话,3nm工艺下实际SRAM所占的面积比例,相比5nm,会从22.5%提高到28.6%。这将极大地挤占GPU上算力资源密度的提升空间。
William Dally在GTC 2020上曾提出了以黄仁勋命名的“黄氏定律”:GPU将推动AI性能实现逐年翻倍。从Nvidia近三代的旗舰级GPGPU的FP16 tensor算力来看,黄氏定律基本是成立的。那Nvidia是如何在单晶体管成本和SRAM密度scaling down终结的世代下,在H100上为黄氏定律续命的呢?
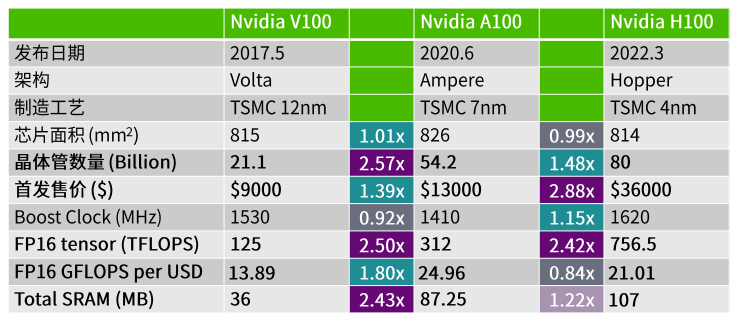
答案就在这张表中。
1.由于6nm后单晶体管平均成本不再下降,H100首发售价相比A100暴涨3倍(有待验证),H100相比A100的FP16 GFLOPS per USD甚至是下降的!
当然,H100上新加入了FP8 tensor。如果以FP8算力计价,performance per USD会有1.6倍提升。但目前FP8在大模型中的效果尚未得到充分验证。据此观察,7nm/6nm可能会是performance per USD的sweet spot。
2.芯片上cache + shared memory + register file的总容量上,A100相比V100有2.43倍的提升,基本跟上了FP16算力提升步伐;但H100相比A100,SRAM容量只有1.22倍的提升。这是5nm后SRAM scaling down终结的直接后果。
为了避免SRAM比例减小后,存储子系统不成为性能瓶颈,Nvidia从Ampere架构之后,在体系结构和编程模型上针对“内存墙”做了大量的创新。篇幅所限不再一一列举。但这些创新的后果是,GPU将越来越多的体系结构层的复杂性交由程序员处理:Hopper架构上程序员只使用CUDA,将很难写出一个tensor算力利用率超过70%的FP16矩阵乘法。
总之,黄氏定律得以延续的关键,在于将更多的晶体管和功耗预算分给计算逻辑,减少片上SRAM的占比,提高算力资源的性价比;然后通过体系结构和编程模型的创新,避免片上SRAM成为性能瓶颈。
“资本家只追求增长;而企业家追求发展:通过创造性地破坏市场的均衡 (creative destruction) ,实现生产要素的重新组合,获取超额利润。”
熊彼特 (Joseph Schumpeter),奥地利经济学家
大模型带来的对高性价比算力的需求,结合摩尔定律scaling down边际效用递减,将延续David Patterson在2018年提出的体系结构创新的黄金时代。20世纪90年代的PC浪潮中Intel在摩尔定律的黄金时代,凭借工艺优势碾压一众RISC对手的景象,将不会在这个世代出现。智能革命浪潮中,只有创造出极致的高性能、高可编程性、高性价比的体系结构,才有机会走上浪潮之巅,赢取超额利润。本节将讨论三个可能的创新方向。
这个小标题源自2020年Science上的一篇体系结构的论文,而该论文的标题则致敬了费曼在1959年预言了纳米技术的著名演讲, there are plenty of room at the bottom.软件-体系结构的联合创新,将是提升芯片上实际算力利用率的关键。【异构编程模型(1): 软件到硬件,天堑变通途】 中介绍了自顶(应用)向下(芯片)的多个中间层。每一个中间层的引入,都会对应用在芯片上的性能造成损失。中间层越多,性能损失越大。当摩尔定律边际效用递减时,高抽象层次语言(如Python)和低抽象层次语言(如汇编、CUDA)之间的执行效率差距成为了有巨大潜力的金矿。本小节试着展示三个矿脉潜在方向。
对于大模型而言,考虑到Transformer的计算访存比CNN更低,同时每层activation的数据量又远大于CNN,如果直接将Python描述的计算图映射为GPU kernel,训练和推理的性能将严重受限于显存带宽。
所幸,学术界对于transformer在GPGPU上的算子融合进行了大量的研究。其中最有代表性的当属2022年6月ArXiv上公开的flash-attention [4]:通过设计一种数值稳定的tiled softmax算法,flash-attention在transformer推理中使能了attention单元的matmul-softmax-matmul算子融合。该方案一经提出就迅速在所有GPU transformer框架中流行开来。
类似的,matmul-layernorm-matmul算子融合也较容易类推出来。而大模型算子中最有价值的算子融合,当属FFN中的matmul-bias-gelu-matmul。
目前Nvidia GPU+CUDA依然是AI研发生态的事实标准平台。学术界算子融合的研究大都是基于GPU开展的,也将最快地应用于GPU上。
必须注意的是,Nvidia CUDA是一个已经延续了15年的编程抽象,其中累积了大量的“遗产税”。CUDA设计之初首要考量是让CPU程序员平滑地迁移到GPU上,因此它将GPU上的海量线程抽象为对程序员思维友好的单一线程 + global线性地址空间,辅以用来提高性能的warp-level synchronization/primitives + shared分布式地址空间。
然而Volta架构引入tensor core之后,这一编程抽象越来越难以为继。如果程序员还用单一线程 + global线性地址空间的编程抽象编写矩阵乘法,TA实际能拿到的性能可能只有标称tensor性能的10%。如果程序员想在GPU上编写高性能的矩阵乘法,TA必须了解汇编级tensor原语和各级memory的容量以对矩阵进行分块,必须手动设计global-shared-registerfile之间数据搬移的软件流水编排。对于更加复杂的融合算子,程序员的思维负担也会越来越重。
Nvidia的解法是投入了大量的软件研发人员,为每一代新架构,使用CUDA开发cutlass库。但这是一种治标不治本的解法。一旦程序员的需求无法被cutlass支持的模板覆盖,TA很难自行开发高性能的CUDA程序。
可以推测,在SRAM scaling down终结之后,随着GPU将越来越多的体系结构层的复杂性暴露出来,CUDA程序开发生态将逐渐从开放走向封闭:只有Nvidia自己的软件开发者能充分理解新架构特性;外部开发者不借助cutlass等官方库,很难自行写出高性能CUDA程序。
对CUDA的革命只能从Nvidia外部推动,而OpenAI Triton作为Pytorch 2.0面向GPU的后端代码生成模块,已经吹响了革命的号角。OpenAI Triton将tensor作为数据结构的first-class citizen(而CUDA跟随CPU,数据结构的first-class citizen是malloc得到的一维连续内存空间)。于是编译器就有了更多信息,可以在IR lowering过程中,以tensor为单元,开展显存聚合、分块搬运、流水编排等性能优化。
类似OpenAI Triton的以tensor为中间表示的编程语言,将打破CUDA在GPU上的垄断地位。
目前Transformer推理中,GPU将算子与算子之间的所有activation都通过显存流通。这种方法只是简化实现的权宜之计。
从仿生学的角度来看,大脑中并没有一个巨大的、保存中间数据的memory pool,而是让相互关联的神经元之间,频繁地交换activation。
使能activation数据的生产者直接与消费者进行通信的能力,将有效地节省片外memory访问带宽。在体系结构设计中,使用片上存储和互联资源,显式地满足算力单元间生产者-消费者局域性的设计理念,引出了空间架构(Spatial Architecture)或可重构架构(Reconfigurable Architecture)。
空间架构/可重构架构已经用在一些新兴的机器学习加速器芯片中。典型的代表有硅谷“硅仙人” Jim Keller领导的Tenstorrent;以及国内清华背景的清微智能等初创公司。
GPU架构设计中亦将融合可重构架构的理念:增强片上互联能力和暂存器容量,让具有生产者-消费者局域性的activation等数据显式地通过片上互联和暂存器流通,从而减少大模型对片外显存的带宽和容量需求。
全文搜索一下,你会发现这篇文章行文至此,memory/存储/SRAM,已经出现了32次。如果让我写一本GPU架构的书,可能会有一半的篇幅在讨论各种SRAM应该如何组织的。而随着SRAM scaling down在5nm工艺的终结,我们必须考虑如何解决GPGPU片上存储供应受限的问题了。

AMD在Ryzen 7 5800X3D CPU中引入的3DVCache L3C是解决片上存储供给问题的方向标。通过在4nm logic die顶部,通过hybrid bonding技术贴上一个6nm SRAM die。这样可以减小logic die上SRAM的总量,使能logic继续随着摩尔定律scaling down。而且,这种设计可以有效提高芯片良率,降低将数据搬移到运算单元的能耗。
当然,3D芯片也带来了很多新的挑战。比如目前EDA工具很难对3D芯片的逻辑特性和物理特性进行建模仿真;上下两个die的电源电路很难设计等等。另外,AMD将如此大的SRAM全部做成Cache的思路,对于CPU合理,但对于GPU就太浪费了。GPU有更好的办法,充分开发头顶上的SRAM的潜力。
目前GPT-3大模型的推理任务,依然需要4张或者8张Nvidia A100。这里最主要的限制是显存容量。一张Nvidia A100只有40GB或者80GB的显存。如果有办法为一张GPU扩充出来一个512GB的显存……
砰,梦想即将成真。去看看Hot Chips 2022吧,CXL (Compute Express Link) 3.0标准刚刚发布,预计2030年会大量出现在芯片上……
当下立即马上就要512GB的显存?那我们只能抓紧时间看看支持CXL 1.1的芯片了。目前Astera Lab、Marvell、三星、澜起都发布了支持CXL 1.1的内存扩展芯片。最新的服务器CPU架构Intel Sapphire Rapids和AMD Genoa都支持了CXL 1.1。
然而GPU呢?最新的GPGPU架构, Nvidia Hopper、AMD CDNA3和Intel Ponte Vecchio,都没有支持CXL 1.1。
当然,Nvidia、AMD和Intel不是不了解显存扩展的刚需,而是他们有更赚钱的技术路线。2022年发布的高性能GPGPU架构,都有一款CPU-GPU通过Nvlink/Infinity Fabric紧耦合的产品:Nvidia Grace Hopper和AMD MI300。这两家的如意算法打得叮当响:与其让CXL芯片公司分一勺羹,不如用自家的CPU当显存扩展控制芯片,这样卖GPGPU的时候还能搭售自家的CPU。
但无论如何,there are plenty of room outside of GPGPU die.
参考资料
[1] 通向AGI之路:大型语言模型(LLM)技术精要 - 知乎 (zhihu.com)
[2] [2001.08361] Scaling Laws for Neural Language Models (arxiv.org)
[3] IEDM 2022: Did We Just Witness The Death Of SRAM? – WikiChip Fuse
[4] https://github.com/HazyResearch/flash-attention
 最前沿的电子设计资讯
最前沿的电子设计资讯
