
在2023 OCP全球峰会上,三星提出了在HBM与Logic芯片间采用Optical IO技术进行数据互联,并给出了两个可能的芯片架构,如下图所示。

先解释下什么是HBM。HBM的全称是High Bandwidth Memory, 即高带宽内存,目前广泛应用于GPU芯片中。HBM采用的是3D堆叠的DRAM芯片结构,如下图所示。多颗DRAM芯片通过TSV技术和micro-bump,在垂直方向堆叠在一起。HBM芯片与CPU/GPU芯片通过interposer中的金属线实现信号互联。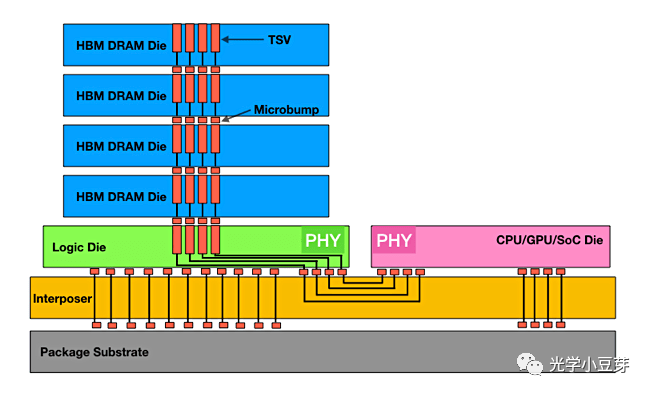
(图片来自https://semiengineering.com/choosing-the-correct-high-bandwidth-memory/)
HBM技术的初衷是给CPU/GPU芯片提供更大容量的内存与更大的互连带宽,解决芯片的内存墙难题。HBM的主要特征包括高容量、高带宽、小面积、低功耗、低延迟。HBM技术目前已经发展到第四代HBM3E, 下表是不同代HBM的参数对比。
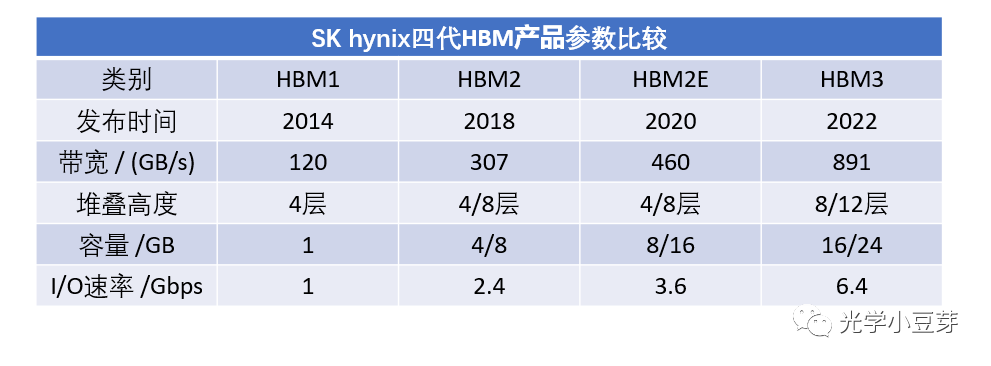 (数据来自https://news.skhynix.com/the-story-of-sk-hynixs-hbm-development/)
(数据来自https://news.skhynix.com/the-story-of-sk-hynixs-hbm-development/)
以Nvidia H100为例,其配置了5颗HBM3芯片,共80GB内存, 对应总带宽高达3TB/s,如下图所示,HBM3芯片分布在GPU芯片的两侧。

(图片来自https://www.hardwarezone.com.sg/tech-news-nvidia-h100-gpu-hopper-architecture-building-block-ai-infrastructure-dgx-h100-supercomputer)
随着以chatGPT为代表的生成式AI应用的兴起,AI训练大模型中包含数亿个参数,需要更大的内存空间以及更高速的内存读取能力。如何发展下一代HBM技术,以满足AI大模型的需求?三星提出了基于Optical IO的两个方案。第一种方案,将光芯片作为Interposer, Logic芯片与HBM芯片分别放置在Interposer上,电芯片中的电信号通过Interposer中的光电接口转换为光信号,进而通过光波导传递到另一颗电芯片下方的光学探测器处,再转换回电信号,实现in-package的光互连。这其实与TSMC iOIS平台的方案(TSMC硅光封装平台的最新进展)类似,也是将HBM和逻辑芯片堆叠到Photonics Interposer上,如下图所示。该方案对Interposer的工艺要求较高。
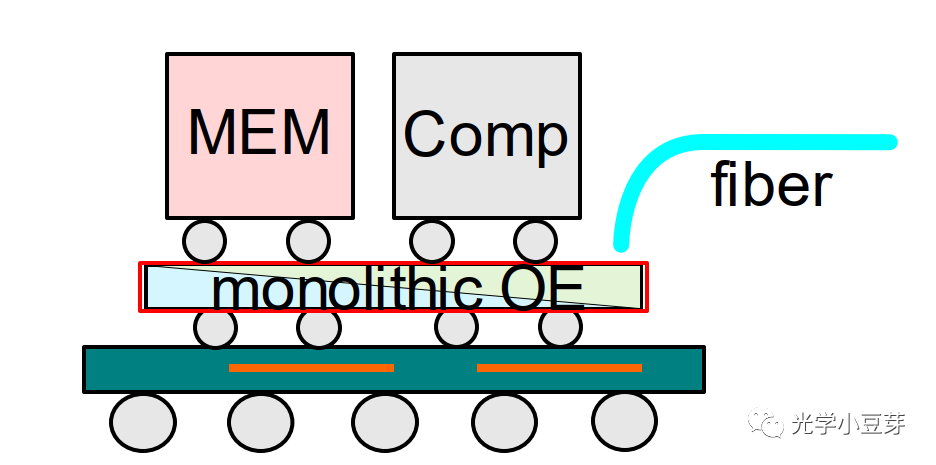
(图片来自文献1)
而三星的第二种方案,在逻辑芯片和HBM芯片中分别引入Optical IO, 电信号通过Optical IO转换为光信号,进而通过光纤传递到远处的HBM处,实现Logic芯片与HBM芯片间off-package的光互连,将Logic芯片的封装与HBM芯片的封装解耦。借助低延迟、低功耗的光互连,可以突破距离与空间的限制,实现更大容量、更大带宽的HBM连接。该方案其实与Ayar Labs公司的方案类似,只是三星更加关注Logic芯片与HBM的互连,而Ayar Labs此前更多的是与Intel、Nvidia等公司合作,实现计算芯片间的高速互连,如下图所示。
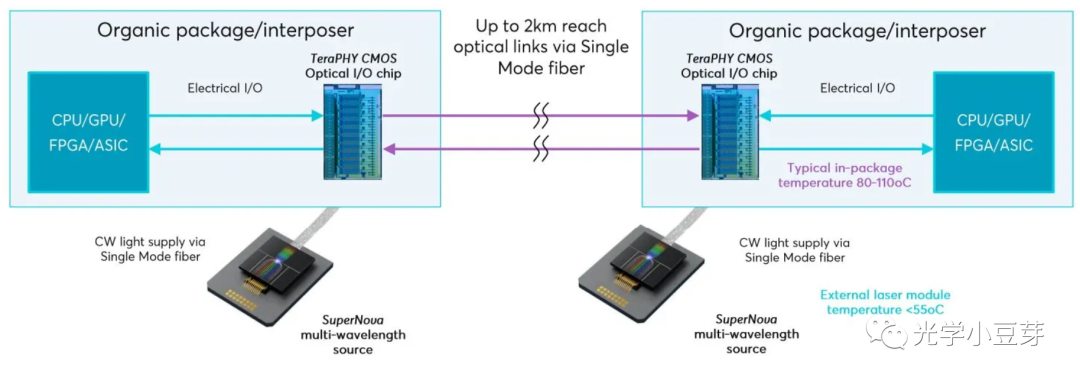
(图片来自https://www.eetimes.com/ayar-labs-partners-with-nvidia-for-optical-i-o-chiplets/)
比较有意思的是,在最新的一篇关于Ayar Labs进展的报道中,有pluggable high-capacity HBM的描述,但是没有更多细节透露。

(https://www.servethehome.com/ayar-labs-teraphy-is-terrifyingly-quick-with-fiber-directly-plugging-into-chips/)
简单总结下,Optical IO技术旨在解决计算芯片间的高速互连难题,在带宽密度、功耗、延迟等方面超越electrical IO。将Optical IO的概念引入到存储芯片中,是一个很自然的想法,而且结合当前生成式AI中大模型训练任务对高带宽、大容量内存的需求,也许HBM的光互连更容易落地。存在技术痛点,新技术才会有机会大范围推广。TSMC、Samsung、Nvidia等芯片巨头的入局,也许会加速Optical IO技术推广与的产业化进程。就让我们拭目以待!
 最前沿的电子设计资讯
最前沿的电子设计资讯

