
Tomer 又来了,还为你们带来了更多有关 ENC 的内容!在整个旅程中,我们通过介绍掌握了相关的基本情况,并探讨了需要考虑的关键因素。我们还探索了复杂的噪音分类世界,区分了稳态噪音和非稳态噪音,同时还探究了传统的语音增强方法(向下滚动至第 1 部分和第 2 部分链接的末尾)。现在,在这个第 3 部分中,我们将深入探讨 AI 音频领域:使用深度学习方法消除环境噪音。我们正处于声学进步新时代的前沿,诚邀各位加入我们,共同揭示这些尖端技术如何彻底改变与干扰声音的斗争,塑造一个听觉和谐的未来。
深度学习方法已成为先进的解决方案。相较于传统方法依赖精心手工设计的算法来分离噪音与所需音频,深度学习方法则利用神经网络的力量,能够自动从海量数据中学习复杂的模式和关系。这种从数据中适应和学习的能力与传统方法有显著的不同,传统方法通常难以捕捉真实世界噪音场景的复杂性。深度学习模型在通用化方面表现出色,能够处理更广泛的和变化,而这一点对于使用单通道的传统方法而言更具挑战,因为它们具有基于固定规则的性质。

(a)

(b)
图 SEQ Figure \* ARABIC :使用 CEVA 的深度学习解决方案降噪。(A) 交通噪音 (b) 鸟鸣声
深度神经网络拥有分析和处理复杂时间和声谱特征的能力,这使它们天生适合捕捉不断变化的环境噪音特性。这种适应能力不仅能够更高效地处理多样化和不断变化的噪音环境,还无需频繁进行手动调整,从而构建出更为出色的噪音消除解决方案。
深度学习的本质在于它从海量数据中提取模式和见解的卓越能力。在训练语音增强模型时,我们通过将模型暴露于噪音音频和干净音频样本对中来应用这一基本概念。这些音频对扮演模型的老师,指导它了解噪音的复杂性。这一过程的真正力量来自于海量数据,以及真实世界场景的多样性和代表性。
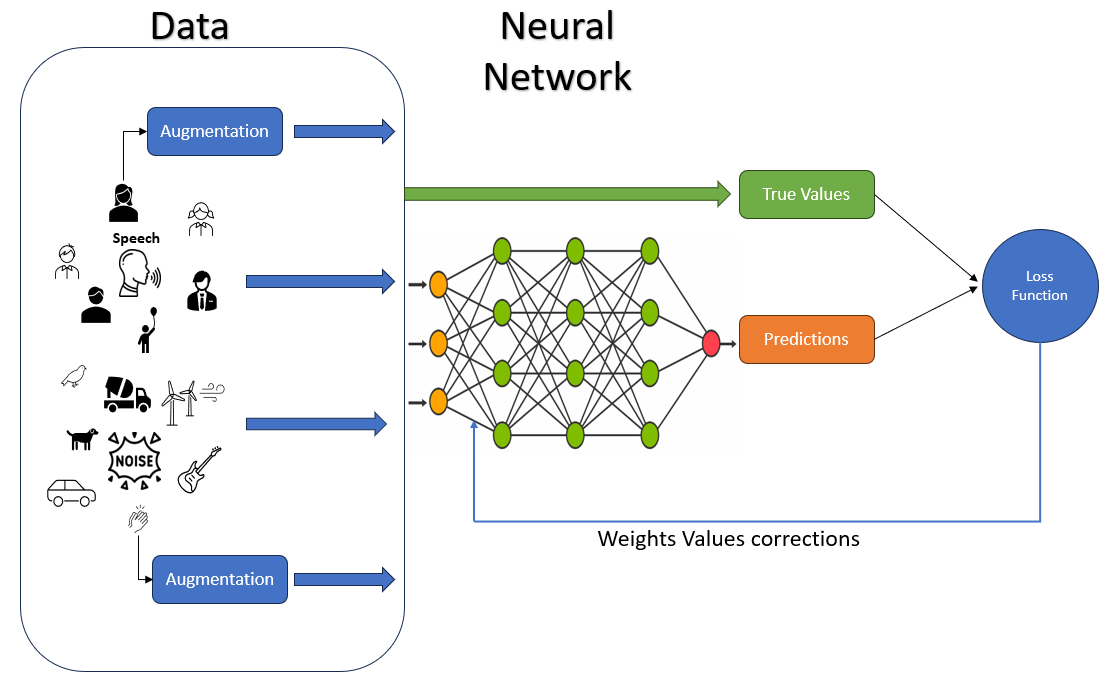
图 SEQ Figure \* ARABIC :模型训练流程
选择多样且全面的数据集至关重要,因为这将确保模型能够遇到各种噪音变化、背景环境和信号类型。该模型通过整合各种噪音来源(包括稳态和非稳态噪音),从而学习如何在不同情况下识别和消除噪音。数据增强概念在此处发挥重要作用,将受控的失真和变化引入数据集。这些增强模拟了真实世界场景的不可预测性,使模型能够灵活应对不同的噪音来源,并增强其通用化能力。
至关重要的是,该模型的转换过程涉及到学习区分基本音频成分与不需要的噪音,这与人类听觉系统的处理方式相类似。随着该模型经过迭代训练阶段,其内部参数会逐渐优化调整,从而更深入地理解数据内部的复杂关系。它模仿的是我们大脑的工作方式,即通过不断学习来适应和提升认知能力。
当对实时音频流应用经过训练的模型时,就可以真正证明此过程的有效性。借助其获取的知识和学习的模式,该模型能够精确地预测并消除噪音,从而在嘈杂环境中提供更加宁静的体验。该模型的成功,不仅依赖于其识别噪音的能力,还取决于其理解噪音在不同环境下呈现方式的能力。因此,噪音消除模型的训练过程超越了算法和参数,更是一场对数据多样性、增强策略以及数字学习与人类感知之间和谐相互作用的探索之旅。
基于掩蔽的方法和基于映射的方法是使用深度学习的两种不同的 ENC 方法。这两种方法的目的都是通过减少不必要噪音的影响来提高所需音频信号的质量,但它们是通过不同的机制来实现这一目标的。
基于掩蔽的方法按照声谱掩蔽原理运行。该方法需要估算时间频率掩蔽,指示每个时间频率区间是否存在目标信号和噪音。然后,将这些掩蔽应用于噪音声谱图,以衰减噪音成分并增强所需信号。掩蔽方法可被视为“软”干预,在该方法中,模型通过修改声谱图的量级来指导增强过程,同时保持相位基本不变。
基于掩蔽的方法具有以下优点:能够有效减少噪音,不会使目标信号显著失真。但是,如果目标和噪音来源在频域中明显重叠,则可能会遇到困难,导致降噪不完全。
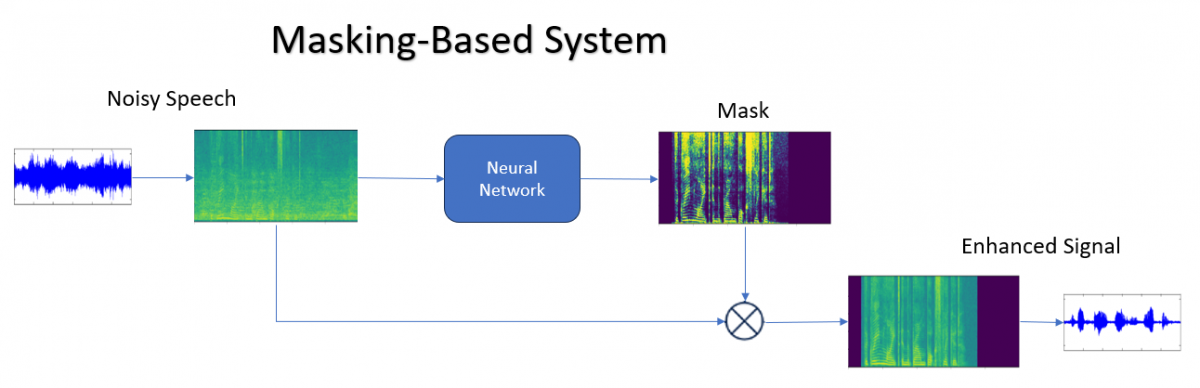
图 SEQ Figure \* ARABIC :基于掩蔽的系统方案
基于映射的方法采用不同的方法,将噪音输入声谱图直接映射到更清洁的声谱图。这些方法不是估计掩蔽,而是学习复杂的映射函数,从而转换输入声谱图以匹配相应的清洁声谱图。这种方法更类似于“硬”过滤,在该方法中,模型在其中明确地决定了声谱图中哪些部分需要增强,哪些部分需要抑制。
基于映射的方法具有以下优点:能够处理噪音声谱图和干净声谱图之间的复杂转换。该方法可以解决相位重构和处理不同频率分量之间复杂的时间关系等问题。但是,如果不加以仔细训练,它们可能会引入一些伪像,因为它们会对声谱图施加更直接的转换。
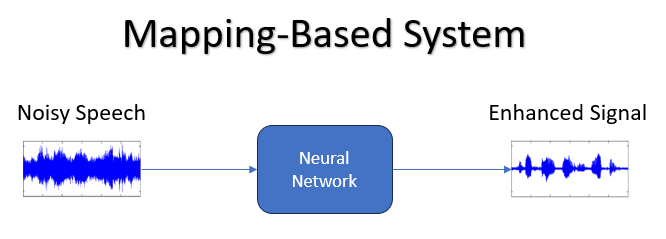
图 SEQ Figure \* ARABIC :基于映射的系统方案
CEVA ClearVox 基于 AI 的 ENC 解决方案是一种基于掩蔽的方法,旨在提高信号的清晰度,同时保留人类语音的自然品质,从而防止失真和不良伪像。
深度学习在 AI 音频处理中的应用,在通用层面,特别是 ENC 方面,具有深远的意义。从提升语音通话和虚拟会议的音质,到通过消除设备噪音营造更宁静的生活环境,这些潜在的好处不可否认。然而,这项前景广阔的技术也面临着挑战。构建包含各种噪音场景的强大数据集并在噪音降低和信号失真间保持平衡,是研究人员和工程师努力克服的障碍之一。
我们的解决方案可正面应对这些挑战。通过利用出色的架构,使其接触广泛而多样的数据集,执行大量数据增强,精心选择和准备数据,以及设置正确的训练目标,我们成功解决了这些挑战。ClearVox 基于 AI 的解决方案标志着 ENC 领域的一项重大进步,提供了一个强大而高效的解决方案,用于提升音频质量并减少不必要的噪音。
声音处理技术的发展,特别是在 ENC 领域,凸显了我们对克服不断变化的听觉环境挑战所做出的坚定承诺。从采用过滤和自适应算法的传统方法,到如今由深度学习推动的 AI 音频的前沿进步,我们经历了一场声波革命。 在 CEVA,我们致力于将 ENC 无缝集成到我们的音频处理解决方案中,克服上述挑战,重新定义我们体验声音世界的方式。当我们发现自己正站在全新机遇的门槛上时,我们对卓越音频质量和有效通信的追求显然是永无止境的。随着每一次创新,我们距离一个噪音不再是障碍的世界越来越近,在这个世界中,人类之间的联系可以在任何环境下和谐发展。因此,让我们继续聆听、学习和创造,因为声音的未来比以往任何时候都更加清晰和充满活力。
在声音处理中通过消除环境噪音提高音频质量 - 第 1 部分 - 简介
环境噪音消除 (ENC): 第 2 部分 – 噪音类型和传统的语音增强方法
 最前沿的电子设计资讯
最前沿的电子设计资讯
