[1] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. “Attention Is All You Need.” arXiv, August 1, 2023. http://arxiv.org/abs/1706.03762.[2] OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, et al. “GPT-4 Technical Report.” arXiv, March 4, 2024. http://arxiv.org/abs/2303.08774.[3] Touvron, Hugo, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, et al. “Llama 2: Open Foundation and Fine-Tuned Chat Models.” arXiv, July 19, 2023. http://arxiv.org/abs/2307.09288.

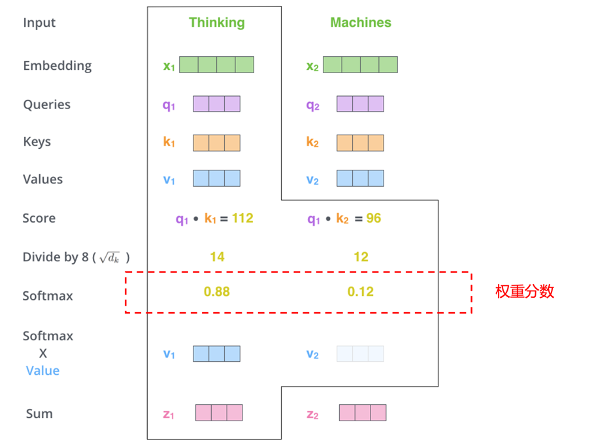
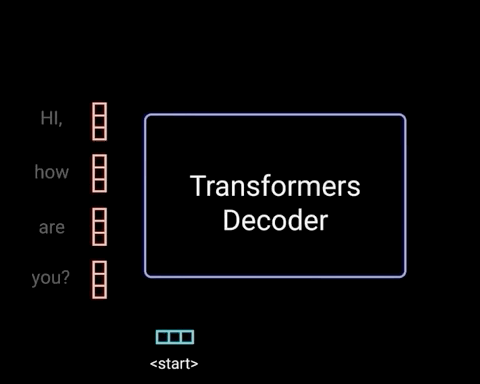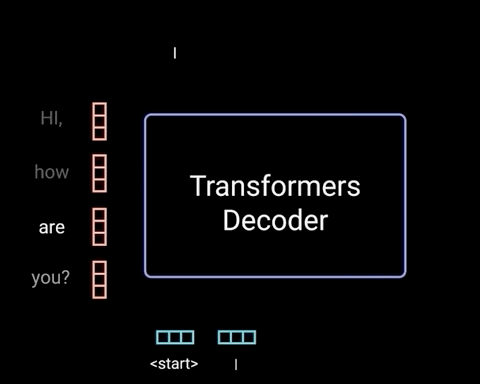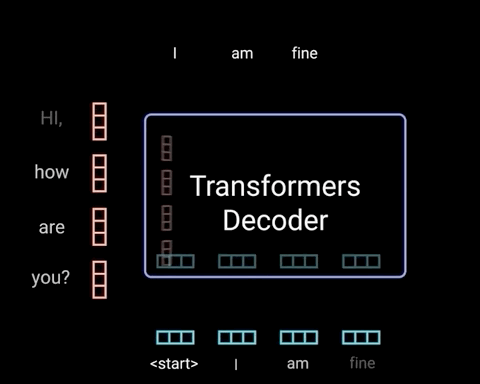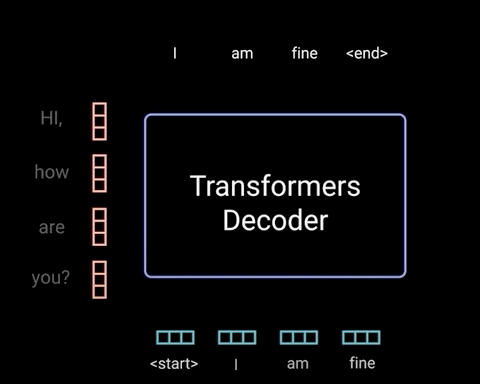
 图片来源:网络
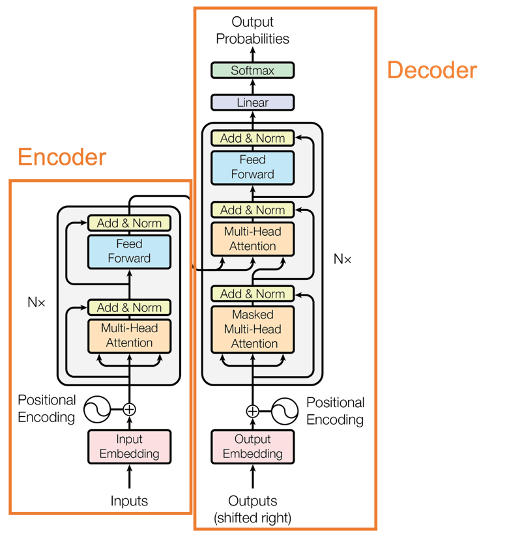
图片来源:网络

 最前沿的电子设计资讯
最前沿的电子设计资讯



