
随着全球对人工智能(AI)的需求不断增长,数据中心作为AI计算的重要基础设施,其网络架构与连接技术的发展变得尤为关键。
本文将简述数据中心网络架构的演变及其在AI应用中的重要性,并探讨两种主流网络架构——InfiniBand和RoCEv2。
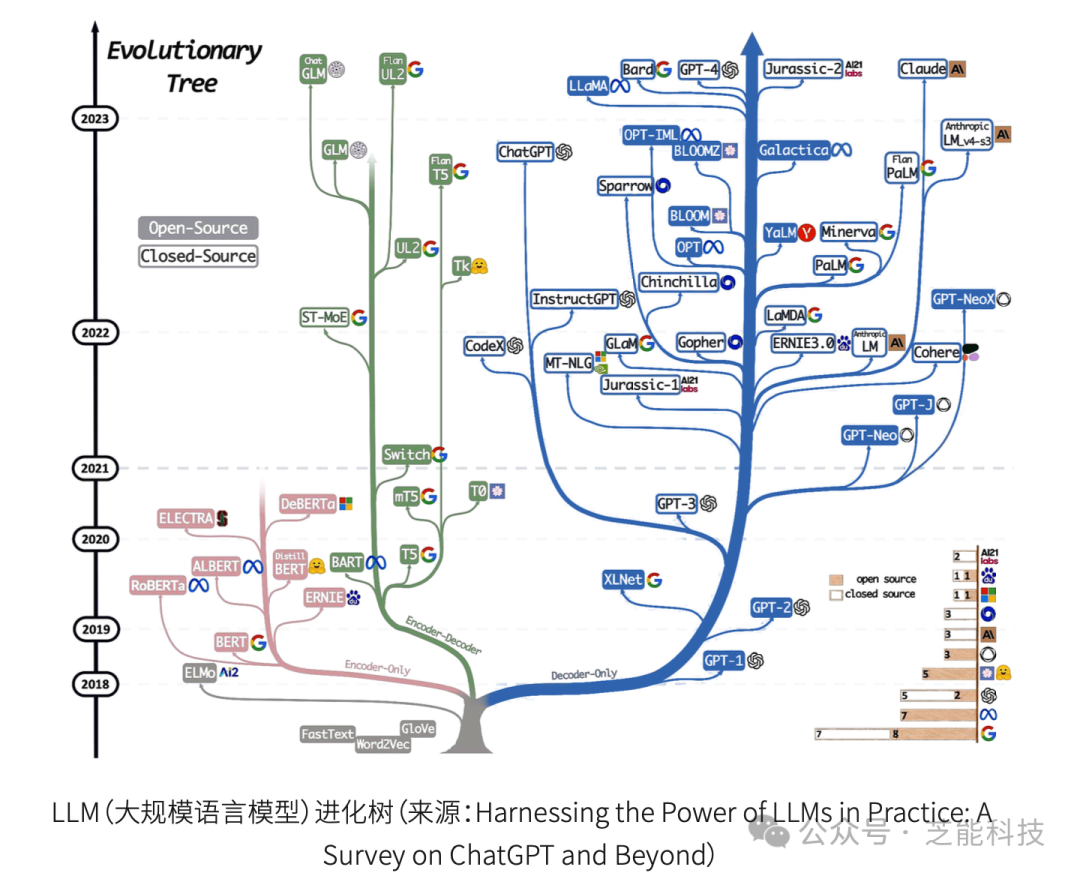
AI生成内容(AIGC)市场在2024年迎来了爆发式增长。OpenAI发布的Sora和国内的Kimi大模型引领了这一潮流。
预计到2024年,全球对AIGC解决方案的投资将达到200亿美元,并在2027年超过1400亿美元。这种增长对AI网络架构提出了更高的要求,因其需要支撑大规模AI模型的训练和推理。
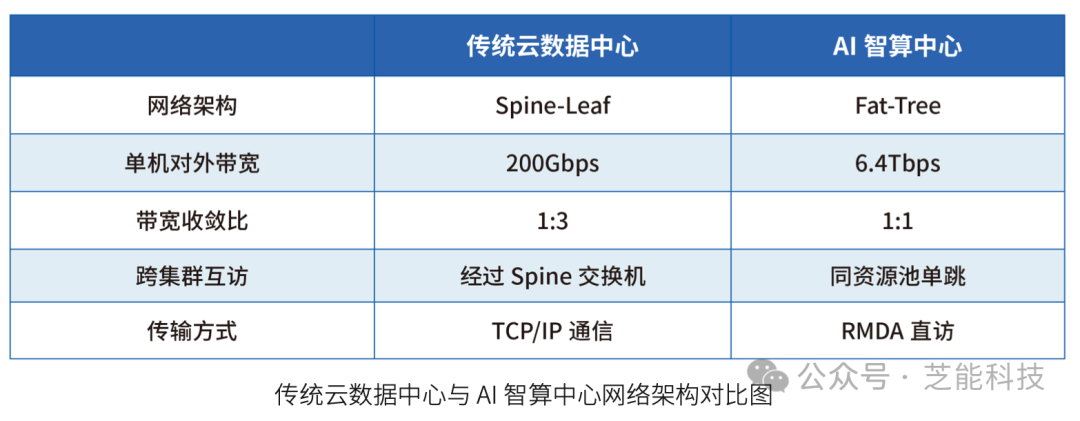
● 传统云计算数据中心网络架构
传统云计算数据中心主要基于南北向流量模型设计,即对外提供服务的流量较大,而内部东西向流量较小。
这种架构存在一些不足,例如高带宽收敛比、较高的互访时延和网卡带宽低。这些问题导致传统架构无法满足AI计算对高带宽和低时延的要求。
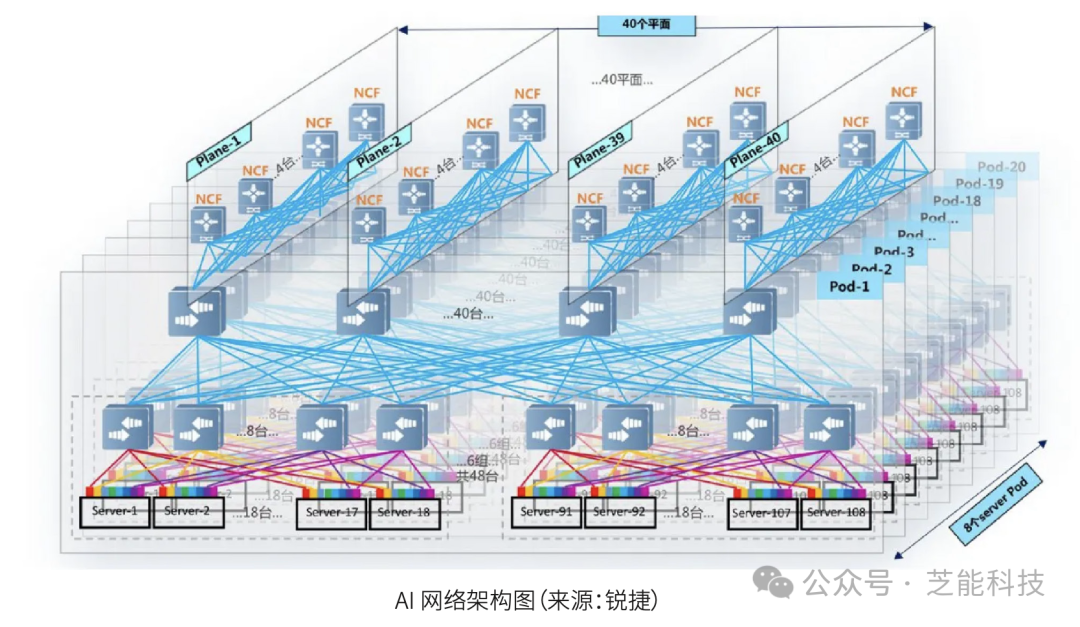
● AI智算中心网络架构
AI智算中心通常采用Fat-Tree(胖树)架构,通过1:1的无收敛配置,确保了高性能和无阻塞传输。此架构能够有效降低时延,并支持大规模GPU集群。
此外,AI网络架构中常用的RDMA技术,允许主机之间直接内存访问,显著降低了同集群内部的时延,提高了网络性能。

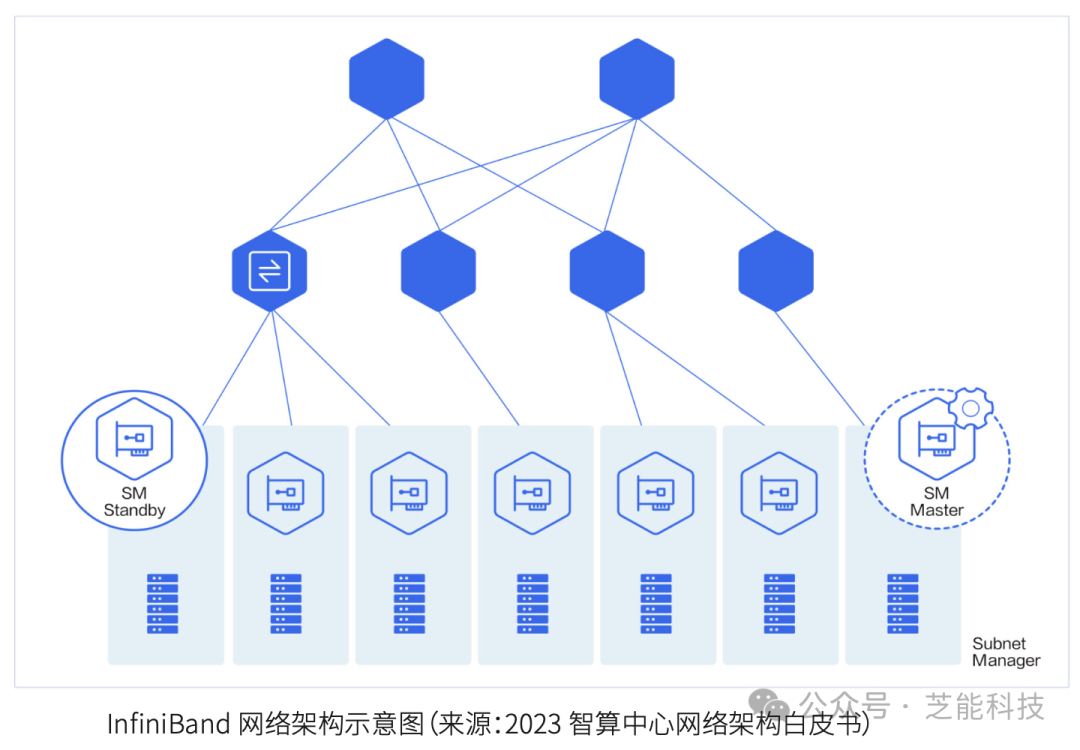
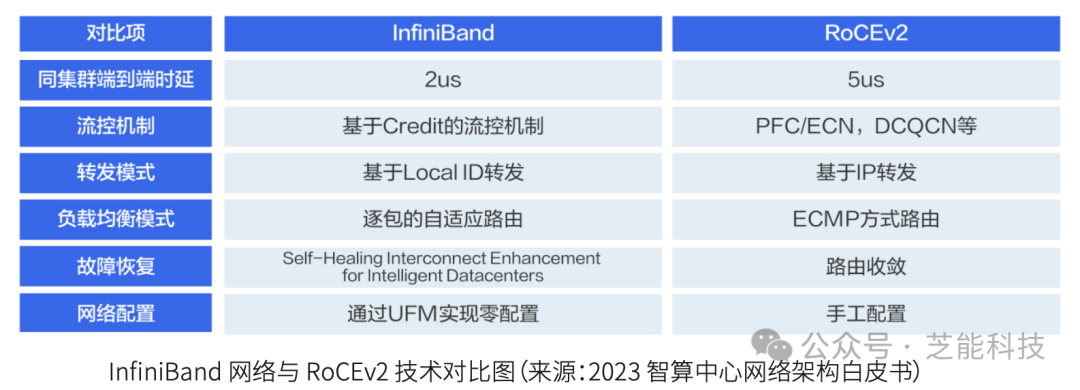
● InfiniBand网络架构
InfiniBand网络通过子网管理器(SM)进行集中管理,使用信用令牌机制确保数据在有足够缓冲区时才发送,从而避免数据丢包。其自适应路由技术能够根据数据包情况动态选择路径,实现最佳负载均衡。
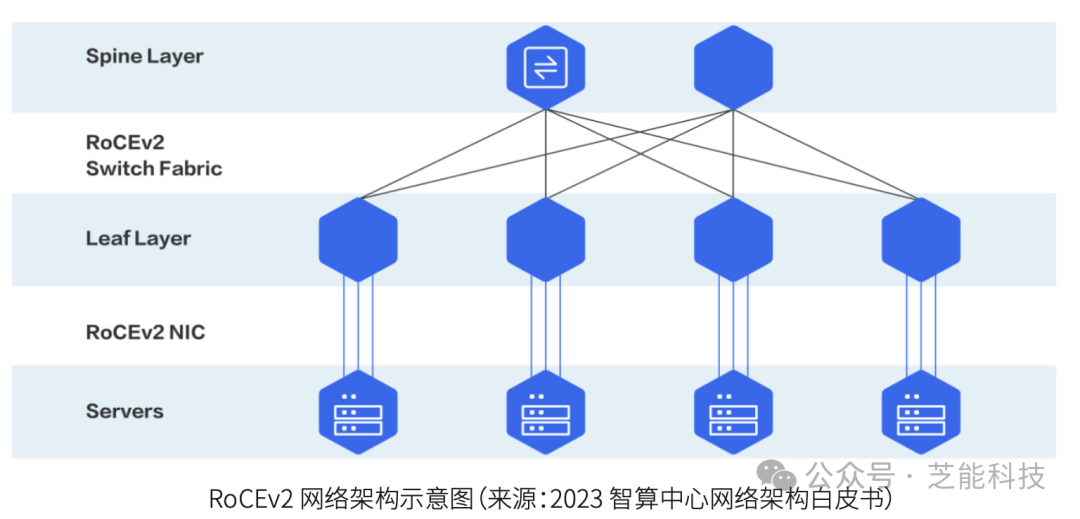
● RoCEv2网络架构
RoCEv2(RDMA over Converged Ethernet)采用以太网和UDP传输层,具有更好的可扩展性和部署灵活性。其流控机制包括优先流控制(PFC)和显式拥塞通知(ECN),结合数据中心量化拥塞通知(DCQCN),能够在保持网络高效运行的同时避免数据丢失。
随着AI计算需求的增加,800G和1.6T的主流传输方案逐渐成为市场热点。
这些方案在实际应用中,尤其是单模传输和预端接技术方面,提供了创新的解决方案。
同时,为应对高能耗高热量问题,液冷解决方案也在AI数据中心得到广泛应用。
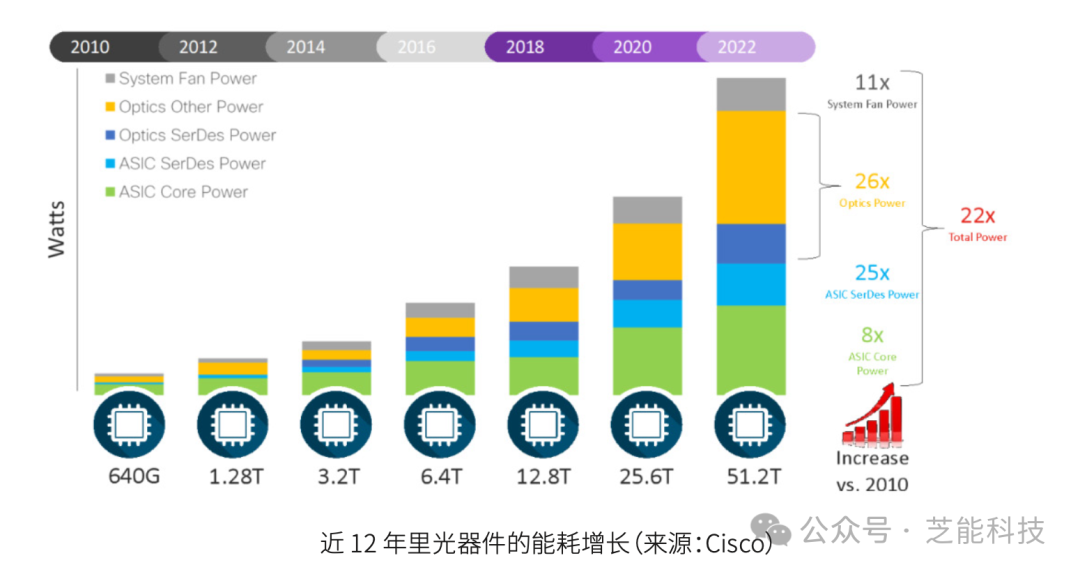
随着光模块技术向 400G 及更高速率迈进,挑战不单是提升数据传输速度,还包括功耗和成本。
从 2007 年的 10G 光模块仅需 1W 功率,到如今 400G 及 800G光模块功耗接近 30W,随着速率的每一次迭代,功耗也相应攀升。
在满载状态下,一个交换机可能搭载多达数十个光模块,48 个光模块的总功耗可达 1440W,而光模块通常占整机功耗的 40%以上,导致整个智算中心的能耗可能超过 3000W。
液冷技术因其高导热性能和高效散热能力,已成为降低网络系统能源功耗的广泛认可解决方案,特别适用于高功率密度数据中心,但需解决冷却液腐蚀性和压强差等挑战以确保系统安全。
AI智算数据中心的网络架构和连接技术正朝着更高效、更低时延和更高带宽的方向发展。无论是InfiniBand还是RoCEv2,这些技术的进步都在为AI的发展提供坚实的基础。
在未来,随着技术的不断创新,AI智算网络架构将进一步优化,推动AI应用的广泛普及和深入发展。
 最前沿的电子设计资讯
最前沿的电子设计资讯

