
在今年OFC上,新加坡IME与Rain Tree公司发布了其基于FOWLP封装方案的光引擎最新进展,实现了1.6Tbps的硅光光引擎。最近他们在JLT的一篇文章中,展示了更多的技术细节,小豆芽这里做一下整理,方便大家参考。
不同于Broadcom、Cisco所采用的Fanout封装方案(对多颗EIC进行FOWLP封装,PIC倒装在EIC上),IME/雨树采用的方案是将EIC倒装在由多颗PIC芯片构成的fanout wafer上,PIC芯片埋入在molding材料中,如下图所示。PIC芯片正面有两层RDL金属,背面有一层RDL金属,便于高速信号、DC信号与电源的连接。在Molding材料中形成TMV(throug molding VIA), 用于信号在垂直方向的互联。
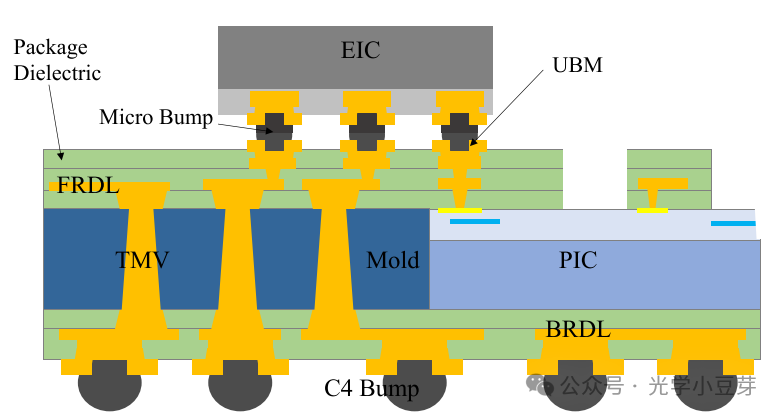
(图片来自文献1)
在进行FOWLP封装前,首先对PIC wafer进行晶圆级测试,筛选出KGDs(Known Good Dies)。接着将PIC芯片背面朝上,贴在molding材料的模具载板(adhesive molding plate)上,并对molding材料进行压塑,形成重构后的晶圆。此时PIC已经被molding材料包裹,在这一步中需要对光口位置进行特殊的处理,以保证molding材料不会影响后续的光耦合。接着将模具进行分离,在molding wafer正面进行两层RDL金属与介质层的加工。这一步完成后,对整个wafer进行减薄,将PIC的背面暴露出来,进而进行背面RDL金属与TMV的加工。TMV是一个锥形结构,顶部直径为150um, 底部直径为60um,高度为300um, pitch为300um。进而在wafer背面加工出C4 bump, 再进行正面EIC的flip-chip工艺,即完成整个FOWLP封装的加工,对wafer切割后就可以得到单个光引擎。整个工艺的步骤如下图所示,
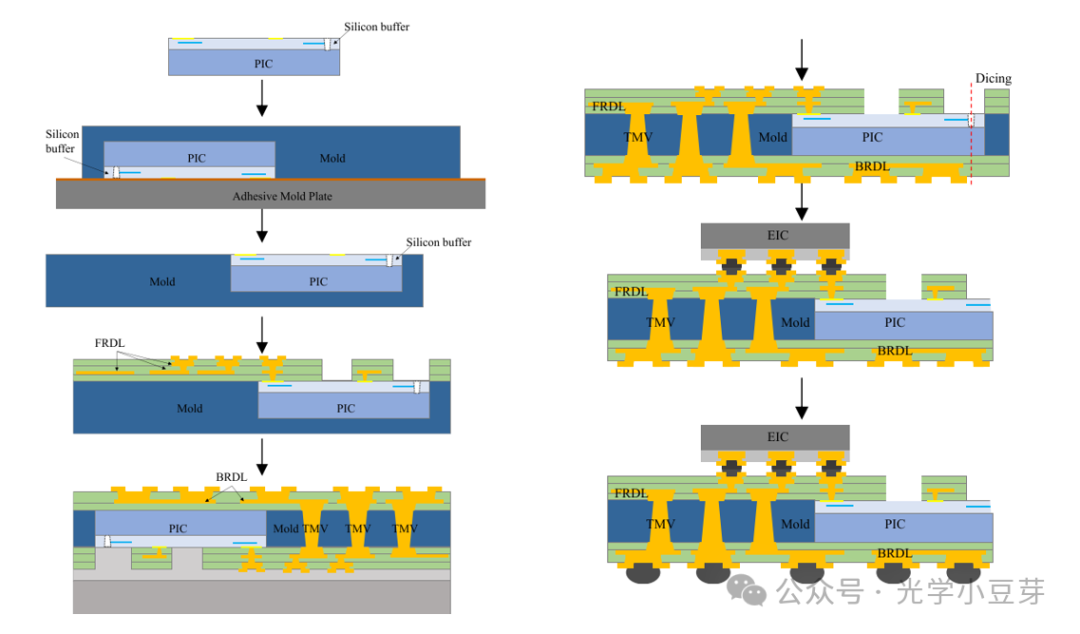
(图片来自文献1)
为了保护edge coupler区域, 避免在加工过程损伤edge coupler,PIC加工时在edge coupler的deep trench区域之外,额外保留一段区域,作为缓冲区(silicon buffer),如下图所示。它的作用类似一个大坝,对molding材料进行阻挡。最终wafer切割的时候,再将这段区域切掉,露出edge coupler的端面,巧妙地保护了光口。
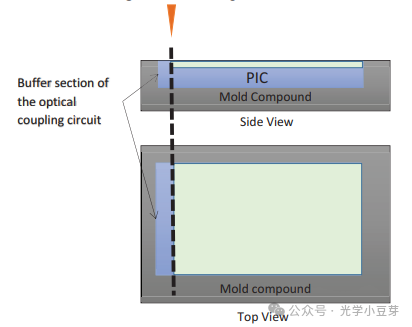
(图片来自文献2)
FOWLP封装后的光引擎尺寸为9.5m*13mm, 包含8个Tx与8个Rx通道。TWMZM和PD的高速信号输入/输出引脚都在PIC的左侧,Driver和TIA并没有放置在PIC的正上方,有点像wire bonding方案的布局,如下图所示。单个通道支持200Gbps信号,整个光引擎即可实现1.6Tbps的信号传输。
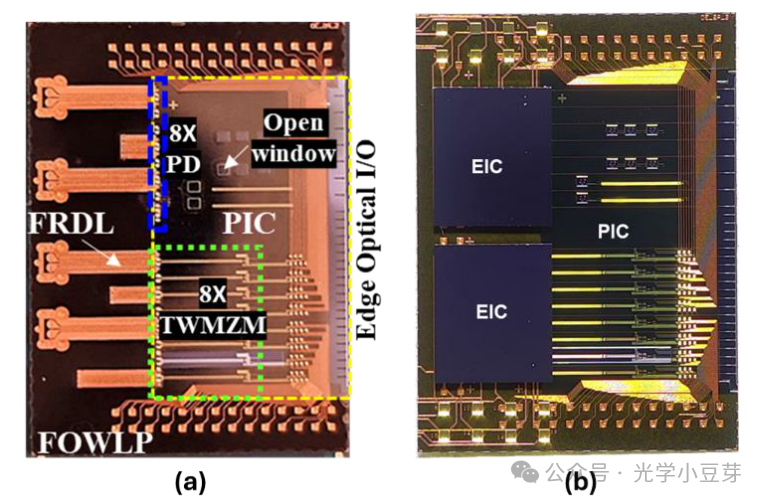
(图片来自文献1)
对于FOWLP方案可以支持的信号速率,研究组给出了相应的测试结果,对于从正面RDL的probe到背面RDL的probe这一金属链路,回损小于-15dB, 50GHz时的插损小于0.5dB,如下图所示。
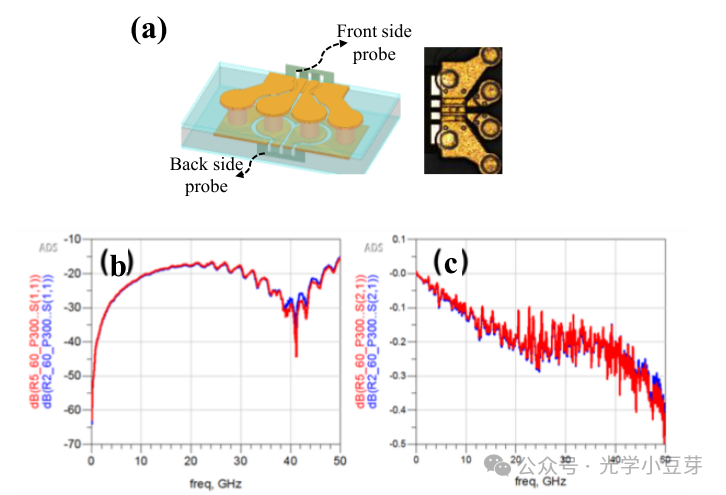
(图片来自文献1)
在经历FOWLP工艺后,端面耦合器的耦合损耗小于2dB/facet, 与裸die的结果接近,证实FOWLP工艺没有裂化光口的性能,测试结果如下图所示。文章中没有给出裸die的测试结果。
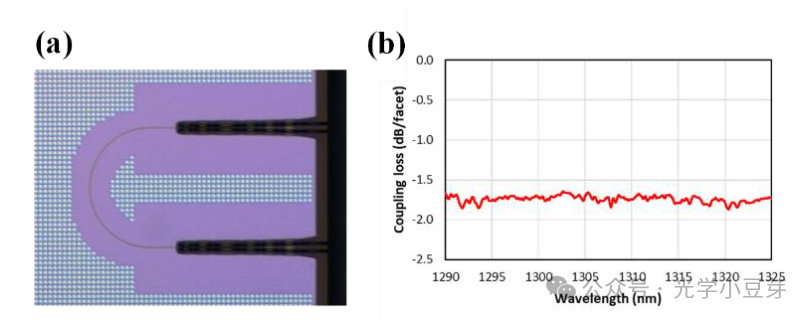
(图片来自文献1)
FOWLP工艺通过在正面介质层上开口,也保留了光栅耦合的能力,因此光引擎可以在wafer level机台上进行测试。类似的,对于芯片中的子链路,共有36个测试样本,在经历FOWLP工艺后,其链路插损保持一致,如下图所示。这也表明,包含PIC的FOWLP wafer可以在wafer level机台上进行测试,方便后续的量产。
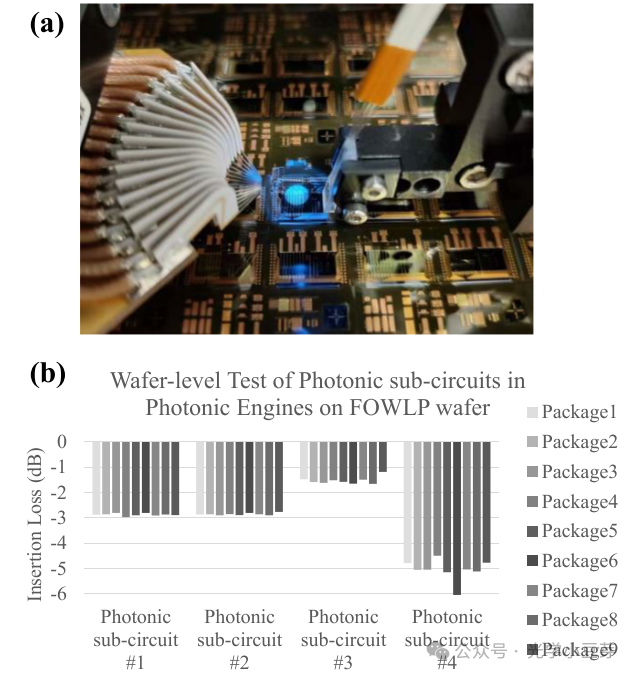
(图片来自文献1)
对发射端进行表征时,研究组采用了两种不同的配置,一种是有900um长的FRDL连接到调制器,一种是通过基板上的pad探测,信号通过substrate RDL到TMV再到FRDL。第二种情况下,高速信号需要经过较长的链路,用于模拟switch芯片直驱的场景。直驱情形下,在使用21-tap FFE下,链路可以支持224Gbps PAM4信号的传输,ER为4.28dB, TDECQ为2.32dB, 如下图所示。

(图片来自文献1)
接收端测试时,采用了reference EVB调制好的112Gbaud的NRZ与PAM4信号,传递到FOWLP光引擎的收端,眼图测试结果如下图所示。
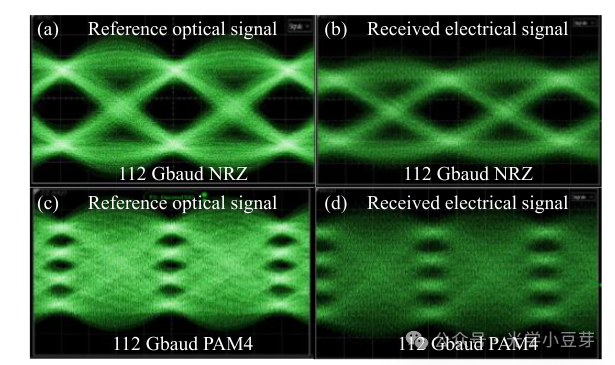
文章中未给出FOWLP光引擎收发端环回的测试结果。通过上述的发送与接收端的链路测试,证实了FOWLP光引擎可以支持单波224Gbps信号的传输。较好的高速信号质量,可以支持LPO与CPO的应用场景。相比于Broadcom单个CPO中64通道的光引擎,IME/雨树的光引擎规模略小,但是其将EIC倒装在PIC上,便于散热。对于1.6T的应用场景,采用wirebonding或者flip-chip的封装方案,是更加经济可行的方案。对于更多通道更高密度的光引擎,FOWLP方案或许才能体现其优势。
文章中如果有任何错误和不严谨之处,还望大家不吝指出,欢迎大家留言讨论。
参考文献:
1. X. Li, et.al., "1.6 Tbps FOWLP-Based Silicon Photonic Engine for Co-Packaged Optics", 10.1109/JLT.2024.3493855
2. L. T. Guan, et.al.,"FOWLP and Si-Interposer for High-Speed Photonic Packaging",
 最前沿的电子设计资讯
最前沿的电子设计资讯

